Welcome to the introduction of Big data and Hadoop where we are going to talk about Apache Hadoop and problems that big data bring with it. And how Apache Hadoop help to solve all these problems and then we will talk about the Apache Hadoop framework and how it’s work.

About Big Data
By an estimate, around 90% of the world’s data has created in the last two years alone. Moreover, 80% of the data is unstructured or available in widely varying structures, which are difficult to analyze.
Now, you know the amount of data produced. Though such a large amount of data bring big challenge and more significant challenge arises with the fact that this data is of no arranged format. It has images, line streaming records, videos, sensor records, GPS tracking details. In short, it’s unstructured data. Traditional systems are useful in working with structured data (limited as well), but they can’t manage such a large amount of unstructured data.
One may ask this question of why even need to care about storing this data and processing it? For what purpose? The answer is that we need this data to make more smart and calculative decisions in whatever field we are working on. Business forecasting is not a new thing. It has been prepared in the past as well, but with minimal data. Too ahead of the competition, businesses MUST use this data and then make more intelligent decisions. These decisions range from guessing the preferences of consumers to preventing fraud activities well in advance. Professionals in every field may find their reasons for analysis of this data.
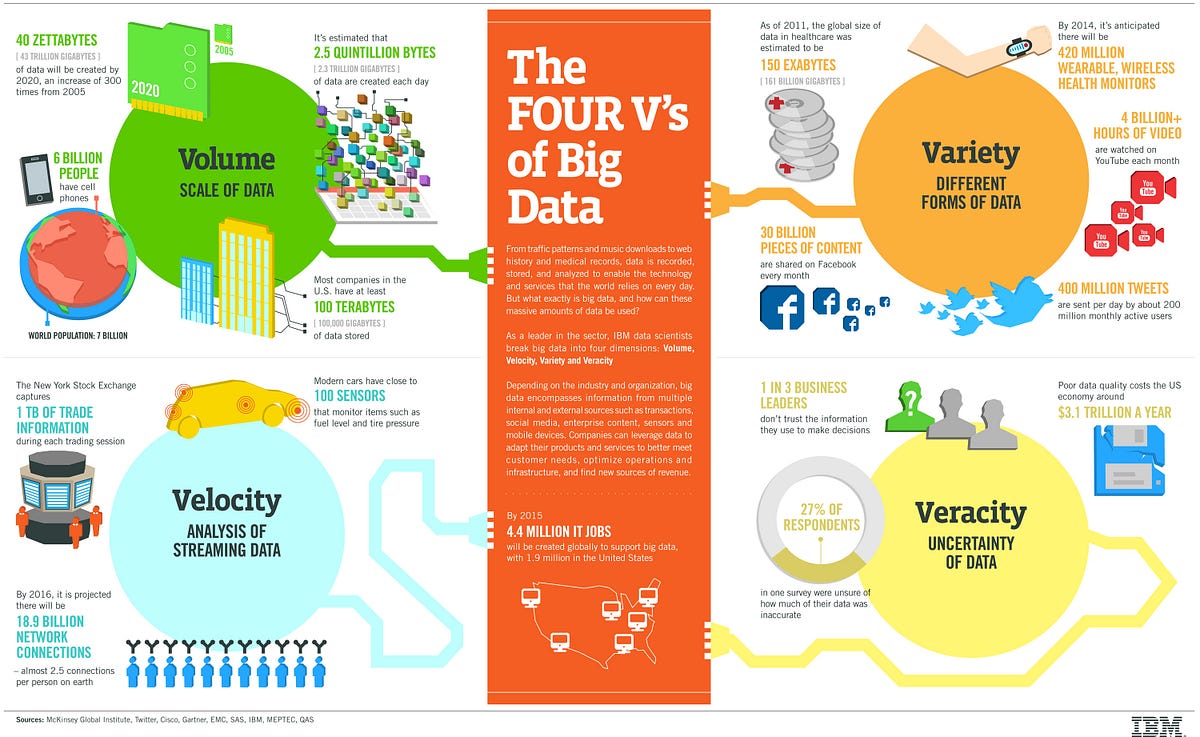
The four V’s of Big data(IBM big data club)
Characteristics Of Big Data Systems
When you require to determine that you need to use any big data system for your subsequent project, see into your data that your application will build and try to watch for these features. These points are called 4 V in the big data industry.
Volume
Volume is absolutely a slice of the bigger pie of Big data. The internet-mobile cycle, delivering with it a torrent of social media updates, sensor data from tools and an outburst of e-commerce, means that all industry swamped with data, which can be amazingly valuable if you understand how to work on it.
Variety
Structured data collected in SQL tables are a matter of past. Today, 90% of data produced is ‘unstructured,’ arriving in all shapes and forms- from Geospatial data to tweets which can investigate for content and thought, to visual data such as photos and videos.
So, is this always comes in structured still or is it come in unstructured or semi-structured?
Velocity
Each minute of every day, users throughout the globe upload 200 hours of video on Youtube, send 300,000 tweets and carry over 200 million emails. And this keeps growing as the internet speed is getting faster.
So, what is the future of your data and velocity?
Veracity
This applies to the uncertainty of the data available to marketers. This may also be referred to as the variability of data streaming that can be changeable, making it tough for organizations to respond quickly and more appropriately.
How Google Solved Big Data Problem?
This problem tickled google first due to their search engine data, which exploded with the revolution of the internet industry. And it is very hard to get any proof of it that its internet industry. They smartly resolved this difficulty using the theory of parallel processing. They designed an algorithm called MapReduce. This algorithm distributes the task into small pieces and assigns those pieces to many computers joined over the network, and assembles all the events to form the last event dataset.

Google.com
Well, this looks logical when you understand that I/O is the most costly operation in data processing. Traditionally, database systems were storing data into a single machine, and when you need data, you send them some commands in the form of SQL query. These systems fetch data from the store, put it in the local memory area, process it and send it back to you. This is the real thing which you could do with limited data in control and limited processing capability.
But when you see Big Data, you cannot collect all data in a single machine. You MUST save it into multiple computers (maybe thousands of devices). And when you require to run a query, you cannot aggregate data into a single place due to high I/O cost. So what MapReduce algorithm does; it works on your query into all nodes individually where data is present, and then aggregate the final result and return to you.
It brings two significant improvements, i.e. very low I/O cost because data movement is minimal; and second less time because your job parallel ran into multiple machines into smaller data sets.

Apache Hadoop ( hadoop.apache.org)
Introduction of Hadoop
Hadoop supports to leverage the chances provided by Big Data and overcome the challenges it encounters.
What is Hadoop?
Hadoop is an open-source, a Java-based programming framework that continues the processing of large data sets in a distributed computing environment. It based on the Google File System or GFS.
Why Hadoop?
Hadoop runs few applications on distributed systems with thousands of nodes involving petabytes of information. It has a distributed file system, called Hadoop Distributed File System or HDFS, which enables fast data transfer among the nodes.
Hadoop Framework
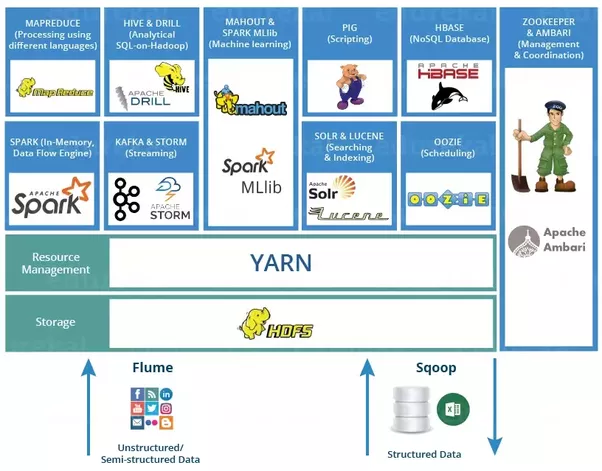
Hadoop Framework
Hadoop Distributed File System (Hadoop HDFS):
It provides a storage layer for Hadoop. It is suitable for distributed storage and processing, i.e. while the data is being stored it first get distributed & then it proceeds.
HDFS Provides a command line interface to interact with Hadoop. It provides streaming access to file system data. So, it includes file permission and authentication.
So, what store data here it is HBase who store data in HDFS.
HBase:
It helps to store data in HDFS. It is a NoSQL database or non-relational database. HBase mainly used when you need random, real-time, read/write access to your big data. It provides support to the high volume of data and high throughput. In HBase, a table can have thousands of columns.
So, till now we have discussed how data distributed & stored, how to understand how this data is ingested & transferred to HDFS. Sqoop does it.
Sqoop:
A sqoop is a tool designed to transfer data between Hadoop and NoSQL. It is managed to import data from relational databases such as Oracle and MySQL to HDFS and export data from HDFS to relational database.
If you want to ingest data such as streaming data, sensor data or log files, then you can use Flume.
Flume:
Flume distributed service for ingesting streaming data. So, Distributed data that collect event data & transfer it to HDFS. It is ideally suitable for event data from multiple systems.
After the data transferred in the HDFS, it processed and one the framework that process data it is SPARK.
SPARK:
An open source cluster computing framework. It provides 100 times faster performance as compared to MapReduce. For few applications with in-memory primitives as compared to the two-state disk-based MapReduce. Spark run in the Hadoop cluster & process data in HDFS it also supports a wide variety of workload.
Spark has the following major components:
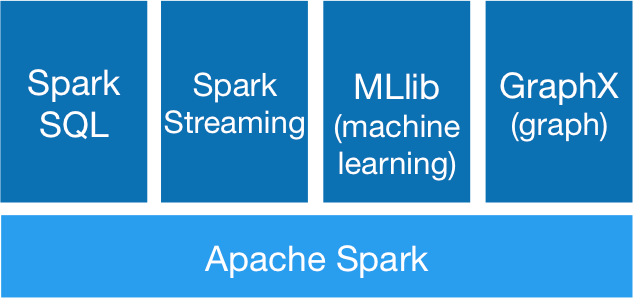
Spark Major components
Hadoop MapReduce:
It is another framework that processes the data. The original Hadoop processing engine which primarily based on JAVA. Based on the Map and Reduce programming model. Many tools such as Hive, Pig build on Map Reduce Model. It is broad & mature fault tolerance framework. It is the most commonly used framework.
After the data processing, it is an analysis done by the open-source data flow system called Pig.
Pig:
It is an open-source dataflow system. It mainly used for Analytics. It covert pig script to Map-Reduce code and saving producer from writing Map-Reduce code. At Ad-Hoc queries like filter & join which is challenging to perform in Map-Reduce can be done efficiently using Pig. It is an alternate to writing Map-Reduce code.
You can also practice Impala to analyze data.
Impala:
It is a high-performance SQL engine which runs on a Hadoop cluster. It is ideal for interactive analysis. It has a very low latency which can be measured in milliseconds.
It supports a dialect of SQL( Impala SQL). Impala supports a dialect of a sequel. So, data in HDFS modelled as a database table. You can also implement data analysis using Hive.
Hive:
It is an abstraction cover on top of the Hadoop. It’s very similar to the Impala. However, it preferred for data processing and ETL ( extract, transform and load) operations. Impala preferred for ad-hoc queries, and hive executes queries using Map-Reduce. However, a user no needs to write any code in low-level Map-Reduce. Hive is suitable for structured data. After the data examined it is ready for the user to access what supports the search of data, it can be done using clutter is Search Cloudera.
Cloudera Search:
It is near real-time access products it enables non-technical users to search and explore data stored in or ingest it into Hadoop and HBase. In Cloudera, users don’t need SQL or programming skill to use Cloudera search because it provides a simple full-text interface for searching. It is a wholly blended data processing platform.
Cloudera search does the flexible, scalable and robust storage system combined with CD8 or Cloudera distribution including Hadoop. This excludes the need to move large data sets across infrastructure to address the business task. A Hadoop job such as MapReduce, Pig, Hive and Sqoop have workflows.
Oozie:
Oozie is a workflow or coordination method that you can employ to manage Hadoop jobs. Oozie application lifecycle shown in the diagram.
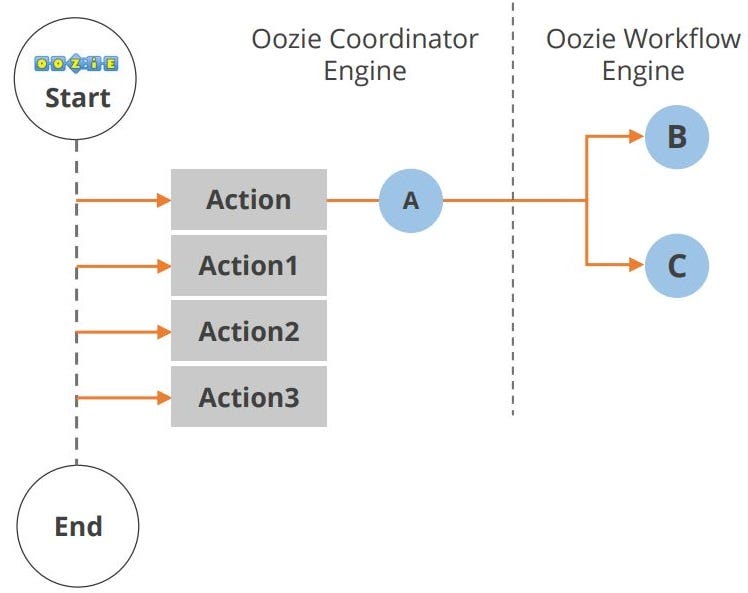
Oozie lifecycle ( Simpliearn.com)
Multiple actions occurred within the start and end of the workflow.
Hue:
Hue is an acronym for Haddop user experience. It is an open-source web interface for analyzing data with Hadoop. You can execute the following operations using Hue.
1. Upload and browse data
2. Query a table in Hive and Impala
3. Run Spark and Pig jobs
4. Workflow search data.
Hue makes Hadoop accessible to use. It also provides an editor for the hive, impala, MySQL, Oracle, Postgre SQL, Spark SQL and Solar SQL.
Now, We will discuss how all these components work together to process Big data.
There are four stages of Big data processing.
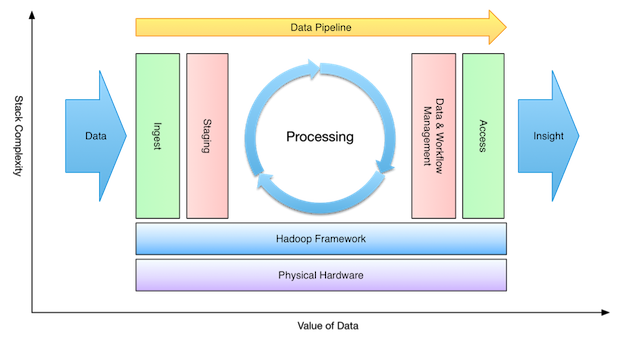
Four stages of Big data processing ( blog.cloudera.com/blog)
The first stage Ingested, where data is ingested or transferred to Hadoop from various resources such as relational databases system or local files. As we discussed earlier sqoop transfer data from our RDMS ( Relational Database) to HDFS.
Whereas Flume transfer event data. The second stage is processing. In this stage, the data is stored and processed. We discussed earlier that the information stored in distributed file system HDFS and the NoSQL distributed data HBase. Spark and MapReduce perform data processing.
The third stage is analyzing; here data interpreted by the processing framework such as Pig, Hive & Impala. Pig convert the data using Map and Reduce and then explain it. Hive also based upon Map and Reduce programming and it is more suitable to structured data.
The fourth stage is accessed which is performed by a tool such as Hue and Cloudera search. In this stage, the analyzed data can be accessed by users. Hue is web-interface for exploring data.
Now, you know all the basic of the Hadoop framework and can work on your further skill to be an expert in data engineer. But I’m going to keep writing about the Hadoop and other machine lear


