Ready to learn Data Science? Browse courses like Data Science Training and Certification developed by industry thought leaders and Experfy in Harvard Innovation Lab.
There’s no lack of advice on how to hire a data scientist. I’ve written on this topic before. Most of this advice assumes a list of skills or qualities that an ideal data scientist is supposed to have, and focuses on how to feel confident that a job candidate has those skills. I want to take a closer look at that list of essential skills. Labeling is problematic. For example, “statistics” is often considered an important dimension of the data scientist skills set, but then you get data scientists who come from more of a computer science background than a statistics background. So then we might create a “machine learning” dimension accommodate that background. So we either focus on two different skills that actually have a lot of overlap, or we bucket them into a “statistics and machine learning” skill, which just avoids the issue. In other words, the question of what skills a data scientist needs is a dimensionality-reduction problem.
And a key feature of most dimensionality reduction — and what I think is missing from most of these discussions — is a focus on orthogonality. A data scientist skills framework should take the big, messy data-scientist-by-data-scientist’s-skills matrix and try to reduce it to a few informative dimensions that minimally overlap. It might require some word-smithing to avoid using already-loaded terms, but it pays off in conceptual clarity. For example, I don’t think “ability to code”, let alone specific languages like R or Python, belong in a skills framework. A data scientist who exhibits all the skills in a well-designed rubric should necessarily exhibit coding skills simply as a matter of course, because a company has a tech stack and data scientists need the skills to integrate with that tech stack in order to ensure that their work is reproducible and scalable. Things like coding are a means, not an end, and therefore I don’t think they should be a direct target.
I should also state up front that I firmly believe the role of “data scientist” to be separate from the roles of “engineer” and “analyst”. That’s how the role exists where I currently work, but I know that’s not the case in many other organizations, including those I’ve previously worked for. I think my current employer has it right. Even in cases where finances or other business considerations require a single person to occupy two or more of those roles, I think that should be viewed as one person wearing multiple hats rather than a sign that the data scientist hat is big enough to encompass the other two.
I’ve come to think of “good data science” as something that doesn’t really exist at the individual level: while individual team members are all very good at certain skills, building a robust data science capability is something more than any one individual can accomplish. Most discussions of data science skills I’ve seen don’t explicitly acknowledge this. We all have gaps in our skill sets, but as long as the team doesn’t have any gaps, that’s ok: it ensures that we’re collectively able to do what we need to do and still leaves us all with lots of opportunity to grow. What I usually see in discussions like this is some sort of disclaimer to the effect that not everyone will need to check every box. If that’s how we as data science professionals think (and I think for the most part it is), it should be explicitly incorporated into our frameworks.
The framework

Individual skills
Let’s go through each of the skills and talk about how to recognize them when we see them.
Design analyses. The skills that fall into this competency have to do with translating business requirements into a technical analytic plan. The decisions data scientists use these skills to make partially depend upon the structure, type, and amount of data available, but also depend on business needs that exist regardless of what the data look like. All of the skills within this competency might fall under the general heading of “knowing how to deal with ambiguous requirements.”
- Explicitly plan the analysis. This includes things like scoping, ordering, and justification of milestones. It is rare for analysis to have a natural stopping point — nearly analysis could be endlessly refined. In business applications, an analysis needs to be scoped and partitioned: milestones need to be set out, stopping rules need to be determined for each milestone, and all of the pieces need to sum up to a whole in a way that maintains conceptual integrity.
- Anticipate and address competing explanations. This may include things like design of experiments, sampling strategy, or sensitivity analysis. Any analysis makes assertions: predictions are accurate enough to have business value, variables x and y are important predictors, adding variable z doesn’t add enough value to be worth it, etc. All of these assertions are vulnerable to competing explanations: sampling was biased, the data set was imbalanced, the variables were defined poorly, etc. Anticipating these vulnerabilities is a skill. Specific methods may mitigate problems, but often the key is to incorporate assumption checks into the design of the analysis.
- Determine the best way to evaluate the results. This may include diagnostic metrics, benchmarking, or KPI development to monitor product quality over time). Analyses rarely yield results that have clearly interpretable value. Often, the question isn’t “are the results good?”, but rather “are the results more valuable to the business than what we had before?” Evaluating the results of an analysis requires knowledge about an analytic method’s outputs as well as knowledge about the business context into which the results will be deployed.
Conduct analyses. The skills that fall into this competency often receive the bulk of attention when people talk about data science. The decisions data scientists use these skills to make depend almost entirely upon the details of the data itself.
- Explore the data appropriately. This includes distributions, summary metrics, visualization, and feature selection/engineering. These skills can be as simple as knowing how to characterize a distribution or measure of central tendency, or as complicated as engineering completely new features. The focus of this skill is on knowing what types of “gotchas” to look for in a data set so those idiosyncrasies can be transformed, omitted, accommodated, or otherwise mitigated.
- Build or apply appropriate algorithms. This includes regression, classification, dimensionality reduction, clustering, and parameter tuning. Categorical data sometimes imposes different constraints upon an analysis than continuous data. The same is true of sparse vs. dense data, supervised vs. unsupervised learning problems, etc. Different problems require different technical solutions, and knowing how to choose the appropriate technical solution is a valuable skill.
- Clearly document findings. This most often includes data visualization and technical communication. Documenting a summary of conclusions from analysis helps others pick up an analysis where one data scientist left off, but they also serve as a sanity check on the data scientist’s conclusions. If analytic results can’t be documented clearly, then there’s a good chance the analysis wasn’t coherent enough to be trusted.
Incorporate analyses into pipelines. A lot happens to data before and after it is used in an analysis. Part of a data scientist’s responsibilities is ensuring these handoffs happen smoothly. This is where the skill set of a data scientist most aligns with the skill set of an engineer. It’s always useful when an engineer can clean, structure, and locate data in exactly the way the data scientist needs, but that should be a way to increase efficiency, not a prerequisite for being able to do one’s job.
- Read/write data to/from any format and location. This includes database queries, merging disparate file types, APIs, and file management. Data scientists cannot assume the luxury of having someone else orgnize their data sets. The data for an analysis need to be pulled form whatever format(s) and location(s) they happen to reside in, and output to whatever format(s) and location(s) is required by those who will use the results.
- Incorporate complex matching and filtering. It’s a relatively simple task to do boolean matching or filtering, comparing strings or numbers as wholes. However, much of data science requires more complex operations, defining patterns for matching string subsets or using complex data types such as timestamps, shapefiles, graphs.
- Make work compatible with the engineering stack. This includes thigns like version control, coding style, and software engineering best practices. The best analysis in the world is of no use if it can’t be incorporated into the business’s other technical systems or can’t scale (if the business needs it to).
Incorporate pipelines into the business. All three of the skills in this competency fall under the general umbrella of “communication skills”. That label is generally not precise enough to be useful. It’s nice if a data scientist can just communicate well with everyone in every situation. It’s nice for anyone to be able to do that. It’s essential that a data scientist be able to communicate in three specific contexts.
- Discover the needs of the business. This includes pre-technical requirements and understanding of wider industry context.This skill has mostly to do with making non-technical topics intelligible to the data scientist. A data scientist often serves as a bridge between technical and non-technical stakeholders, and so should be able to understand the non-technical side of the business.
- Navigate the business’s organizational structure. This includes relationship building and stakeholder management, and sometimes gets summarized as “soft skills”. Any organization has human relationships that need to be navigated in order to achieve business outcomes. This of course includes the people skill of not being a jerk, but also involves, for example, the more nuanced skill of recognizing the unofficial gatekeeper on a project and getting that person’s buy-in before planning a wider hearing.
- Package technical work for diverse audiences. This includes non-technical communication, including visualization for effect as well as information. This is the other side of the “discover the needs of the business” skill. Data scientists need to be able to make technical topics accessible to non-technical people, whether for the purpose of marketing or to make sure stakeholders can use a data science product wisely.
Build the profession. This competency area might seem more like a “nice to have”, but I think that drastically underestimates the value reaching beyond one’s job into the larger profession. Data science as a profession is too rapidly changing for a data science team to really keep up with the state of the art if that same team doesn’t continuously re-evaluate what data science is. Engagement with the larger profession flags an individual contributor as someone whose ability to contribute meaningfully has been vetted.
- Contribute exernally. Meetups, hackathons, open source code repositories, blogs, and other public contributions keep a data scientist connected with the wider community. Public contributions invite public comment and criticism, which in turn improves practice.
- Lead the team. Participation on workingroups and serving as a mentor for a junior member of the team or an intern are some of the most common unofficial leadership positions on a team. In some ways, unofficial leadership is a narrower-scope version of contributing publicly: it opens a data scientist’s practice to scrutiny, which improves practice.
- Draft policy and procedure. This may include creation of candidate interview protocols, conference attendance policy, or social media policy. A contrbution to the wider data science community doesn’t necessarily need to be public. How best to structure and manage data science teams is still very much an open queston. Policy and procedure are disseminatable artifacts — capable of improving more than just the organization in which they were created.
Competency levels
Deciding upon orthogonal areas of competency is half of the challenge of defining a data science skills rubric. The other half of the challenge is deciding how to assess degree of competency. I’ve found the conscious competencemodel of learning to be a convenient way of thinking about skills levels:

Unconscious incompetence means a data scientist is unskilled but for the most part does not realize it — in fact, does not realize it is important to even have the skill. For example, people in technical professions generally are often stereotyped as being unconsciously incompetent in the area of soft skills — they are bad at interacting with people, don’t realize they are bad at it, and sometimes even deny that it is important to be good at that sort of thing in the first place. People who are unconsciously incompetent have bad intuition regarding a skill: they reach wrong conclusions because they don’t even know what the problem is.
Conscious incompetence means a data scientist knows what the problem is but doesn’t really know how to solve it. This stage of learning is rough — a data scientist may see mistakes as an indictment of their value as an employee, perhaps closely mimicing widely-recognized best practices longer than is wise before asking for a mentor to point out a more nuanced approach.
Conscious competence means a data scientist knows the problem and the answer. This is still a high-growth stage of learning, but the data scientist sees mistakes as a valuable source of new information. Feelings of confusion or inability are seen as signs pointing to a way to proactively build competency.
Unconscious competence is a stage where a skill has become “second nature” — so much so, that it requires little conscious thought to exhibit the skills.
Using the rubric
Traditionally, a rubric has provided a checklist: the evaluator chooses the one option for each line item that best exemplifies the skill level of the one being evaluated. As data scientists are extremely aware of the dangers of reporting measures of central tendency rather than a distribution, this rubric is designed for a more nuanced usage. For example, here is how I filled out the rubric for myself after being in my current position for only a couple months:
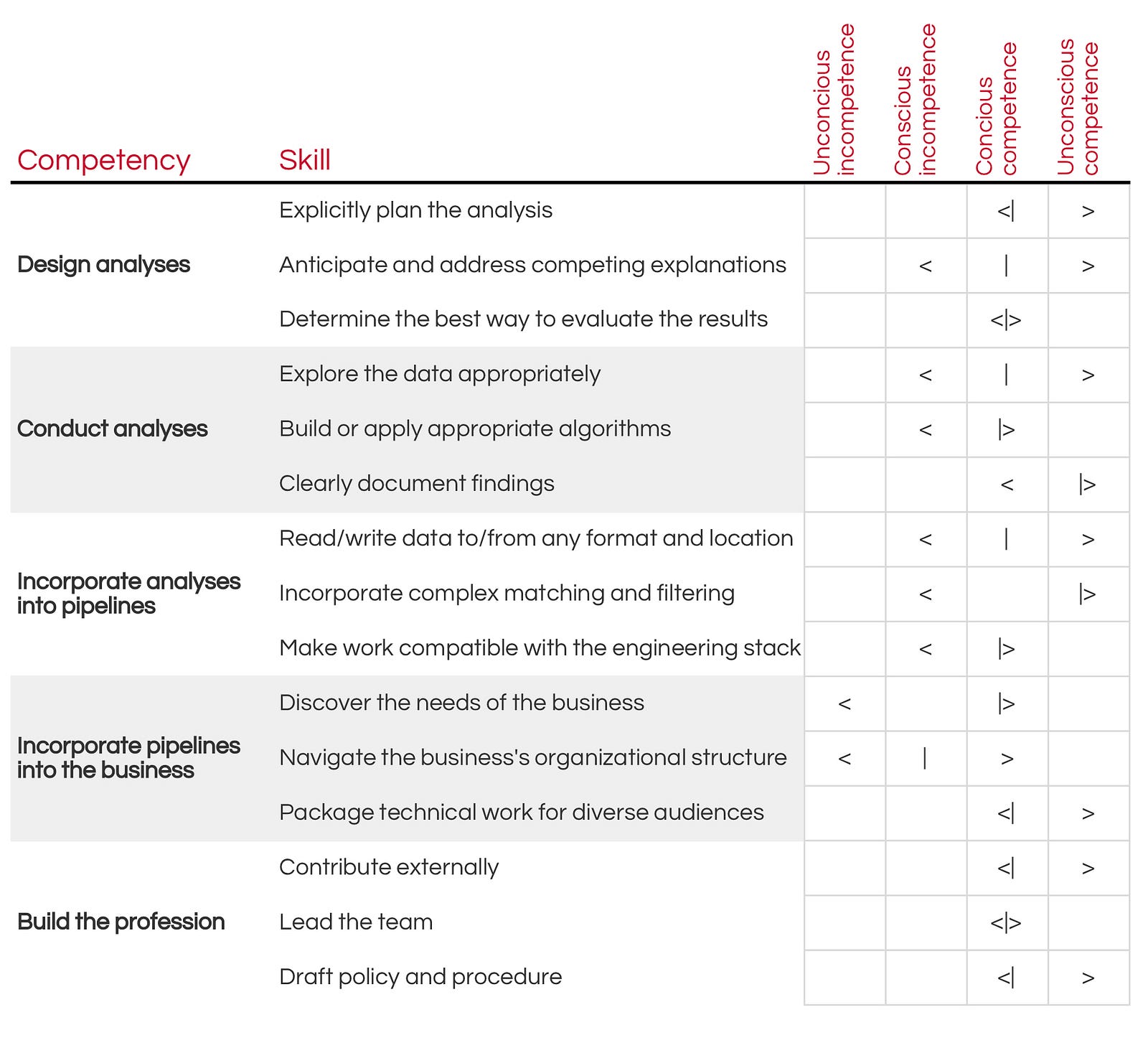
Because there are dozens or even hundreds of ways a data scientist could be said to exemplify a particular skill, I’ve delineated where I think my minimum (<), median (|), and maximum (>)performance in each skill falls. Below is a quick explanation of what I was thinking when I decided to fill out the chart the way I did.
- Explicitly plan the analysis. My background in social science and my decade in a wide variety of industries and sectors has made it more-or-less second nature to take an ambiguous goal and decompose it into a handful of measurable sub-goals, and to provide a justification for my plans. That being said, I read articles and books on principles of design, and still frequently find best practices of which I was not aware.
- Anticipate and address competing explanations. It’s second nature for me to define assumptions I make in an analysis and to build in tests of those assumptions. I’m entirely comfortable with implementing most sampling strategies or coming up with my own. I’m only marginally familiar with formal design of experiments principles and would not feel competent to implement such principles by myself without further learning.
- Determine the best way to evaluate the results. I think I’m just generally solid in this area. It’s not second nature, but it’s been a while since I encountered any completely unfamiliar territory.
- Explore the data appropriately. I’d rate myself high to very high on exploratory visualization, but a little lower on statistical distributions (I didn’t come from a statistics background so there’s a lot in that area that I don’t know). I’m also aware that there are a number of methods for engineering features that I am familiar with only in name.
- Build or apply appropriate algorithms. I feel I’m generally competent in this area, but I’ve had little chance to use deep-learning approaches. That’s a definite gap in my skill set.
- Clearly document findings. I feel about this skill similarly to how I feel about the “explicitly plan the analysis” skill. My background trained me for this and my experience has given me a lot of practice. I rarely have to think about how to do it.
- Read/write data to/from any format and location. On this skill, I range from second nature (CSVs, Postgres) to generally competent (most other flavors of SQL, Spark, AWS EC2 and S3), to incompetent-but-aware of it (other Hadoop technologies, other AWS services, other cloud systems like Google Bigtable, etc.)
- Incorporate complex matching and filtering. Text-pattern matching (regular expressions, etc.) is second nature to me, as is most datetime data management. I’ve recently become very familiar with shape data and graphs but know I have a lot more to learn in those areas.
- Make work compatible with the engineering stack. For the most part, I feel I’m generally competent in this area, mostly from having built and managed a combined data science and engineering team in the past. However, there are still many things I’m learning about smooth handoff to an engineering team that needs to operate at scale.
- Discover the needs of the business. In general, I have a lot of experience in stakeholder management, requirements development, business process mapping, etc. However, I moved to my current job having no experience in that’s job’s industry. I was largely ignorant of that industry context, and was content to learn as the opportunity came along rather than explicitly prioritizing growth in this area.
- Navigate the business’s organizational structure. I’m good at this in general, but I’m working in a new organization — one that is undergoing a lot of changes in its structure and policies. When it comes to specifics, I don’t know what I don’t know.
- Package technical work for diverse audiences. I’m generally very good at this. My background as an anthropologist makes it relatively easy for me to understand other people’s perspectives and several years of teaching experience make it relatively easy for me to craft the presentation of even difficult-to-understand topics.
- Contribute externally. I’ve blogged for years. I used to post a lot of my work to Github but haven’t done that very much for a few years because most of my work was proprietary. I still find ways to volunteer or consult in my spare time, and I actively participate in recruiting events.
- Lead the team. I lead a working group on external outreach and collaboration and mentor junior members of the team.
- Draft policy and procedure. I’m wrote this document 🙂 Aside from that, I tend to focus on policy in all the jobs I’ve had. There are times when that has been one of my main job responsibilities.
I personally prefer that a skills rubric be used more for forward-looking conversations than for backward-looking conversations. For example, a performance review isn’t necessarily the right time and place to talk about a data scientist’s general competency in any particular skill set. It is, however, an appropriate time and place to talk about how the data scientist spent a couple months, say, creating an elegant statistical solution that couldn’t be deployed at scale. The issue at review time isn’t the lack of skill; it’s the lack of value delivered. That can then set the stage for a separate forward-looking conversation about, in this case, building one’s knowledge of software engineering constraints and best practices. The performance review serves as a reality check, and then this rubric serves as a tool for constructing a growth plan. At the time I filled in the rubric for myself, there are the areas where I decided I wanted to grow, in order of priority:
- Get a better feel for the businesses needs. I felt a little distant from the actual needs of our customers. Most of my ideas for innovation came from me, not from the people actually using our products. I wanted to feel like I had an established pipeline for learning about customer pain points and wish lists.
- Improving my analytic planning/design skills. I was reading Fred Brooks’ Design of Design at the time and loved it, but felt I wasn’t retaining enough for me to really incorporate it well into my practice — I wanted more experience explicitly designing entire data-supported projects, not just designing individual analyses.
- Get practice using streaming data. Much of the data I used can from streams, but it was always a snapshot or a summary over time. I wanted to get some more experience using Kafka, Spark Streaming contexts, etc.
- Network analytics. I’d become more familiar with network analytics through some of my recent work, but there’s tons of ground to explore in this area and I found I really enjoyed it.
- Learn Scala. I used PySpark, but I’d encountered several situations where I might have been able to work more efficiently if I’d worked in Scala. I knew enough to make sense of Scala code when I saw it, but I couldn’t write it.
- Open-source some of my work. I wasn’t interested in starting my own library, and while I’d love to contribute to already-established libraries, I wasn’t sure where I could add value. In the meantime, I’d developed several convenience functions for dealing with messy shape data as well as some functions for getting connected components form an adjacency list at scale via Spark. I wanted to make it a priority to document those things and get clearance from my employer to share it openly.
- Expand my experience with feature engineering. There are loads of methods out there. I’ve used relatively few and am familiar with many others, but I felt like that was a thin part of my technical expertise.
- Get familiar with deep learning. It’s trendy right now and it really does yield some great results in the areas where it’s been successful, so I thought it would be in my interest to become competent in it.
Why does it matter?
I want to say that it’s fair to question why we need to be so specific in how we define the data science skill set, but I really don’t think that it is fair to question that. Not when we have so many job advertisements stipulating that a data scientist must have an advanced degree in a STEM field, or must pass a set of toy coding challenges, or must have on-the-job experience in an impossibly broad set of technical tools. Anyone who has been on the job market for a data science position has seen just how little most prospective employers understand about what they’re looking for, or how to recognize competency. A skills framework establishes common ground for conversations, even when those conversations are among people of wildly diverging perspectives. The rubric forces both you and others to be explicit about an evaluation. A good framework doesn’t guarantee that a conversation will be productive, but a bad framework comes pretty darn close to guaranteeing that it won’t be. A lot of people want to hire a data scientist. A lot of prospective data scientists want to be hired. If we can be more clear and precise about what a data scientist needs to be able to do, we can make both groups happier than they are now.


