Ready to learn Data Science? Browse courses like Data Science Training and Certification developed by industry thought leaders and Experfy in Harvard Innovation Lab.
Design, ethnography, and future-proof data science
I never intended to be a data scientist. I graduated from college with a degree in cultural anthropology and a naive confidence that the type of research I wanted to do didn’t require math. Through sheer luck, I fell into one of the few anthropology graduate programs in the United States that took math seriously, which changed my perspective a little but not a lot. When, for my doctoral fieldwork, I traveled to Central Asia to study identity narratives among religious, political, and social activists, I used a handful of standard statistical tools like principal component analysis and regression models alongside my decidedly non-mathy interviews and participant observation.
I eventually got my PhD and landed a job doing strategic intelligence and planning with the U.S. Department of the Army. They hired me because I was an anthropologist, but it didn’t take me long to see that there was a flood of data coming out of Afghanistan that very few people were really leveraging. Over time, I expanded the quantitative part of my toolkit to tackle data at larger and larger scale. I hacked myself into a data scientist because being a data scientist was the best way to do my job. Since that time, I’ve built and managed data science capabilities in the public, private, and non-profit sectors, and across the security, travel, asset management, education, and marketing technology industries.
When people learn about my background, they often ask “do you miss being an anthropologist?” My answer to that question is always the same: “I’m still an anthropologist.” People almost never ask me what I mean by that, but the more I think about it, the more I believe that what I mean says something important about how data science can remain a cohesive profession in face of increasing automation and public scrutiny.
Good implementation requires good design
As a profession, I think we’ve devoted too little attention to the issue of design. The relatively few discussions of the topic I’ve seen strike me as either too general or too specific. On the one hand, we seem to talk about “good design” as something sort of indefinable — we can only know it when we see it — while at the same time we seem to shift too quickly from the importance of good design to a list of specific methods, metrics, and other technical tools necessary to turn the design into an implementation.
Once, when my daughter was very little, she wanted a toy kitchen. I got it into my head to get old cabinets and hardware from a second-hand store and make her that kitchen set. In the end, the thing was held together with wood glue and wishful thinking. My daughter loved it, but it was a real piece of junk. My implementation suffered from two weaknesses.
On the one hand, I only used tools that I already had, which meant five screw drivers that were all too large or too small, slip-joint pliers a mechanic had once left under the hood of my car after an oil change, a hammer I took from my dad’s garage when I went to college, and a small bag of tool-like objects collected from IKEA furniture purchases. In short, my technical toolset stunk and I didn’t really know how to use the few tools I did have.
On the other hand, I really had no experience or competency at envisioning, in detail, what I wanted to build. I didn’t know how to plan the thing as a whole, or consider contingencies, or adapt after mistakes, or anticipate the way the various pieces could or should or would go together.
If I had had the biggest, best set of hardware in the world, I would have finished a little sooner and ended up with a marginally better product. Not knowing how to implement was certainly a big problem, but not knowing how to design was what really held me back.
I think design skills are particularly important to data science as a discipline at this particular moment in time, because how much of the technical side of data science will eventually be automated is still very much an open question. Training and validating models is an important part of the job. Many of the models I have trained and validated over the course of my career could have been automated today in whole or in part by services like DataRobot. Design skills, and how we learn those skills, deserve more attention than we, as a profession, have given them to date.
The word “design” has the same root as “designate”: the word “signum”, which means “a mark” — something you write or place or cut that distinguishes one thing from another. In other words, “design” is the practice of taking a particular goal and distinguishing all of that goal’s relevant tasks, materials, and possibilities one from another. Certain problems are challenging to conceptually organize in this way, regardless of how difficult the technical implementation may or may not be. I think those problems are a big part of data science’s future.
Design as negotiated story-telling
In my experience, design skills are harder for people to learn than other non-technical skills, like “domain expertise” or “communication skills”. I think that’s because of how the learning of each skill happens:
- When you need to learn a subject domain, you put yourself in contact with people who are already familiar with the domain. Each time someone uses a word you don’t know, or cites an unfamiliar example, or tells a story from their experience to explain a decision you don’t understand, you gain domain expertise.
- When you need to learn communication skills, you communicate and then get feedback on what you could have done better. Each time you learn of a new tactic, watch someone demonstrate best practices, and then try to mimic those in your next attempt to communicate, you gain communication skills.
In both cases, the skills themselves can be difficult to learn, but it’s not particularly difficult to understand how to learn them. With design, it’s different. It’s difficult to learn, but it’s also difficult to learn how to learn. That’s because what makes someone competent in design skills is different from what makes someone competent in other, non-technical skill sets:
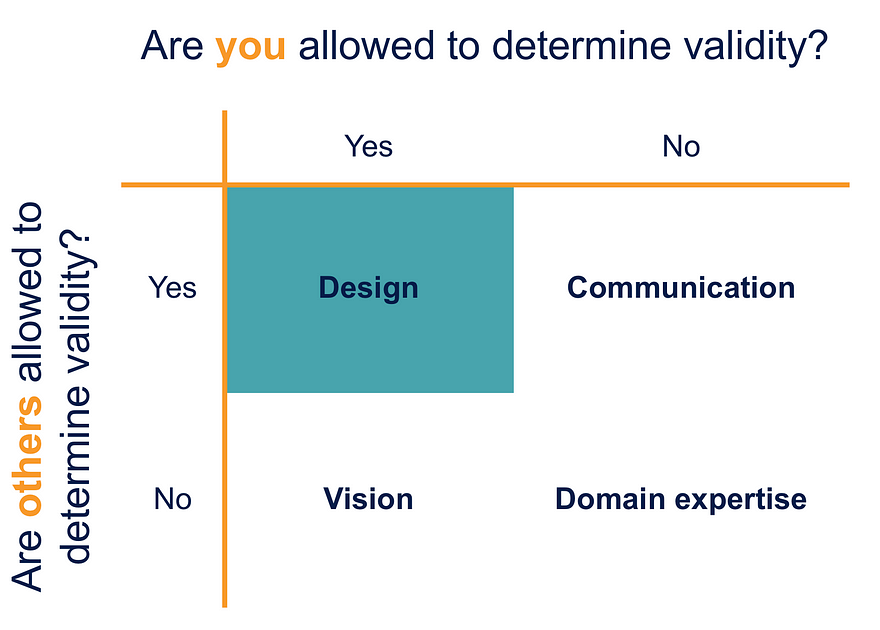
(I’m not going to talk about the “vision” part of the table. That’s a topic for another post).
It boils down to the extent to which you, versus other people, get to decide that particular piece of knowledge or a particular action is reasonable, acceptable, “right” — in a word, whether it is valid. With domain expertise, no one has that authority: if a thing happens within a domain, it’s a part of the domain. In communication, others have the entire authority to decide what is valid: it doesn’t matter how good you thought your presentation was if everyone else thought it was terrible. You can’t say “I don’t care what everyone else says, I know I’m a great communicator.” That betrays a fundamental misunderstanding about how communication works.
In design, both you and others hold the authority to determine validity. I don’t mean that validity can be determined by either you or others. I mean validity has to be negotiated.
Anthropologists tend to use a method called “ethnography” as a way of negotiating design validity. The method gets characterized in many different ways, but I find it useful to think about ethnography as requiring you to go into situations that are more-or-less foreign to you and to put your own intuition and assumptions to sleep. You get input from “natives” about how they view those situations, and then you wake your own intuition back up in order to translate what you’ve learned into something that looks like a coherent and reasonable story to you. You then take that story back and revise it until it seems like a coherent and reasonable story to them too. It’s iterated, negotiated story-telling.
As an anthropologist, when I have a research question, I find someone who will talk to me about it. I have them tell me how the world works according to them, take notes, and eventually I craft a story that explains the assumptions and context and circumstances that make their story reasonable and logical to me. Then I share that story with them. Then they tell me I’m full of crap.
I don’t think I’ve ever had anyone recognize their story the first time I had tried to retell it. Their intuition and my intuition were just too far apart. I get detailed criticism, then I recraft the story. A few iterations of this, and I get a response along the lines of: “well, that’s not exactly how I’d put it, but I think you got all the major points right.” Then I find someone else to talk to. This time, I start by telling the story I’ve crafted — tell them that was how the world works. Then they tell me I’m wrong, and I ask them to put me right.
Over time, as I work with more people and deliberately seek out those who had exposure or perspectives that past contributors didn’t have, I craft a story that most contributors recognize as reasonable. Sometimes the story splits into more than one story, because different groups of people fundamentally disagree. More often than not, I end up with one main story that tells most of the picture, and then several satellite stories that tell important variations.
I don’t just compile information. I fill in the gaps between individual contributors’ stories. Often contributors themselves disagree (sometimes vehemently) with each other’s stories, but agree with my bridge. I defend my contributions to the story as much as they defend theirs. It’s not enough for me to recognize a perspective as simply being there, and it’s not enough for others to tell me what worked and what didn’t. I needed to negotiate a story that blends how I view the world and how others view it, and the results need to be accepted as a whole even if it is hard to swallow in parts.
Good design comes from negotiating stories. There are learnable skills, beyond communication skills, that make a person a good designer.
Give data a voice
Now, the idea of design as the outcome of negotiation among various stakeholders is certainly nothing new. In fact, that kind of iterative setting of priorities is at the core of agile approaches to software design. However, I think design in data science differs from design in most other engineering contexts, in that the data itself needs to have a voice. I mean that in largely the same way that I mean each stakeholder in a project needs a voice. In a healthy design environment, stakeholders don’t just give input only at the times and in the ways that the designer stipulates they should. They are able to contradict. They’re able to raise doubts. They’re able to add unanticipated insights. I believe it needs to be a core part of a data scientist’s job to create tools that allow individual data stories to be told, even when no one specifically asks for the story.
These storytelling tools need to be responsive because design is negotiated, and therefore iterative. When a stakeholder proposes a course of action to address a particular business problem, the storytelling tool set should be able to react to that: to show, in an intuitive way, some ways that data will look different if that course of action is carried out, and flag any cases where the story ceases to make sense. And it needs to do that quickly: if data is a drag on the conversation, it’s going to be let out.
Improved design skills are the key to solving one of data science’s biggest current challenges: algorithmic bias. It’s not hard to find examples of efficient and scalable technical solutions that suffer from serious design flaws. For example:
- An investigation by Bloomberg into Amazon’s offering of same-day delivery service revealed that poorer, more minority-populated zip codes were frequently excluded. The algorithm recommended same day delivery in places where Amazon already had a lot of Prime subscribers, which subscribers tend to be fewer in number in poorer areas.
- A story by Wired showed how child-abuse protection algorithms tended to target poor families. The indicators of child abuse that the algorithm tried to take into account (“not having enough food, having inadequate or unsafe housing, lacking medical care, or leaving a child alone while you work”, etc.) blurred the lines between neglect and poverty.
- Researchers from Carnegie Mellon created fake users that behaved in the same way and whose profiles only differed in their gender. Google’s ad display system tended to show ads for highly-paid jobs much less often to the users whose profiles indicated that they were women.
In none of the above cases is there any indication that race, wealth, or gender were explicitly targeted. The tools were built to answer a simple business question: how do we differentiate people, places or situations that interest us? The technical solution in each case, as far as we can tell, seems entirely reasonable: choose a set of proxy measures and flag the people places and situations that most frequently exhibit those proxy measures. However, in building these system, it does not seem that any set of tools was also built to answer the question of whether the flagged people, places, or situations systematically differed in any attributes form those that were not flagged? That is not a technical failure. It’s a design failure.
I think this issue of tooling-for-design is largely unexplored territory in data science, although it’s starting to receive a little more attention in software development. At any rate, it’s an area that is much more robust against the threat of automation than are the technical skill sets that are often promoted as the core of what defines the profession.
Example 1: parcel geometry overlap resolution
Valassis Digital collects location data from mobile devices and uses that data to help companies more precisely market to their target audiences. A lot of my work with that data touches on the issue of location semantics: we find that certain devices tend to cluster in a particular geographic space, but we want to understand why they cluster there. One way to try to understand location semantics is through parcel geometries. One way to understand why a device might appear in a particular place is to look at who owns that particular place. That kind of data is obtainable through assessor’s offices across the United States and Canada. We get a geometry definition that defines the borders of the property, and by looking at the metadata associated with a geometry, we find way to attach meaning to geolocation data.
Parcel geometry quality varies widely. One difficulty we’ve encountered in using that data is that sometimes parcel geometries overlap. We don’t have a great understanding of why the overlap happens: in some cases, it looks like a simple matter of sloppy record keeping; in other cases, two definitions of property (personal property vs city right-of-ways, for example) create situations where parcels might legitimately overlap. For most of our purposes, it’s helpful for one piece of land to be associate with one and only one parcel. Therefore, I’ve had to work to detect that overlap, which is easy, and automatically resolve it, which is harder. Consider the following case:
This is fairly typical of the overlap we encounter in our parcel data. The blue polygon represents one parcel, and the yellow outline represents another. Seeing this example, several relatively simple technical solutions suggest themselves. We could assign the overlapping area to the larger of the two parcels, or to the smaller of the two, for example. The solution I finally arrived at was to difference the area of overlap from both parcels to create a simulation of what each parcel would look like if it lost its overlap. I then checked each simulation against size and shape thresholds. If a simulated parcel was smaller or more narrow than what we typically saw in useful residential and commercial parcels (the two kinds of land that we are most interested in), I simply removed the shape associated with the unsuccessful simulation. If neither shape resulted in an unsuccessful simulation, I assigned the overlap area to the larger shape. If both resulted in an unsuccessful simulation, I merged the two shapes together.
Once I arrived at the above process for resolving parcel geometry overlap, I went through and did some simple descriptive analysis of the results, noting how many parcels were removed, edited, merged, etc. I also went through dozens of images like the one above to confirm that the results looked reasonable. In other words, I did some normal checking of results. However, I continued to overlay satellite images with polygons — a few thousand of them, and I built a tool show the results of my algorithm alongside the original breakdown. It was tedious. But we have millions of parcel geometries, and I’m used to seeing new stories emerge unexpectedly, even after long periods of hearing the same story over and over again. The result:
In the image above, an assessor took a multi story building and created a parcel geometry for each apartment on each floor. They’re all stacked. My simple algorithm made a huge mess of this situation: it effectively ended up removing the entire building because every parcel ended up becoming too narrow or two small when compared to some other parcel. This was a special case of parcel overlap that had to be separately detected and dealt with before running the core algorithm. In this case, I looked for stacking (sum the areas of each parcel and divide by the total area that all the parcels cover together — anything over 1.0 indicates stacking), and in cases where I detected it, I merged all of the stacked parcels together into a single building. That should work fine, right?
Look closely at the border lines in the above image. Nearly all of the lines are doubled. In fact, this entire area is represented by two sets of parcels, although the sets are not identical — one is offset a little from the other, but the shapes are also slightly different in many of the cases. My stacking detection resulted in this entire subdivision being merged into a single building — not an optimal result. In this cases, I needed to check for stacking as before, but then check for redundant layers. I created a network where each parcel was a node and each edge was a case of parcels touching — not overlapping. I then took the largest set of connected components from this network and used that as a base layer. It then went through every other set of connected components, deleting the new layer if it overlapped above a certain threshold, and merging it if it didn’t.
All of the above is a simple example, but it illustrates the benefits — and sometimes the necessity — of creating a way for a data set to react to an intended algorithm. It required me to create a new tool set that highlighted areas of overlap so I could more intuitively see problem areas, and it required me to keep “asking” portions of the dataset whether my implementation made sense. Most of the images I looked at indicated no problem at all with my basic algorithm. It was only after many hours of searching that I started to discover the gaps.
Example 2: location precision calibration
We get hundreds of millions of geo-located records a day. However, not all of that data can be taken at face value. Among other problems, specific ISPs, apps, devices, or particular device configurations can report data in the form of pinpoint coordinates when in fact the coordinates aren’t a pinpoint. There are a number of reasons for this, only one of which is that sources sometimes rely on high-level records that encode an entire area as a single set of coordinates, as one unfortunate family at the geographic center of the contiguous United States has felt for over ten years.
So, at the start, the problem seemed pretty straightforward: flag coordinates that are attached to an unusually high number of unique devices. For example, if most of the coordinate pairs in an area see between one and ten unique devices, but one coordinate pair has 1,527 unique devices, then that one coordinate pair is probably being used as a default location. This zoom-in of the top 20 coordinate pairs in one area, ordered by number of unique devices, shows what that looks like.
Incidentally, I omitted all coordinates with fewer than three decimal places precision, and rounded all other coordinates to six decimal places. Six decimal places represents a space with diameter of about 4 inches, which is around the limits of what GPS can offer in terms of precision without some substantial triangulation.
There’s an interesting analytic and business question here. The red line in the graph above represents a example of how I could set a threshold for filtering out coordinates. You can clearly see the jump in number of devices, but you can see at least two similarly-sized jumps further down the line. What should be considered an extreme value rather than simply a very busy spot?
There is no good technical answer to that question. There are a variety of methods for doing changepoint detection, but all of those methods naturally have parameters that need to be tuned. And, as far as I’m aware, none of them tell you how many change points to pay attention to. What if you see at least three large jumps like we do in the graph above. Is the first one the cutoff for identifying the fake location data? The last one? Even in cases where there is only one changepoint, that only give us an unambiguous course of action in those situations (and there were many of them) where the changepoint separates the very largest datapoint from all of the rest. That matches our naive conception of how this problem of default locations works. But I found cases where the change point separates many, sometimes dozens of data points from the rest.
There’s no clear technical solution to the problem, and the subject domain doesn’t give us clear guidance — because we don’t know the system that is generating the hotspots, we don’t know how many are plausible. This is a design challenge.
This is where data needs a voice, and with geo-coordinate data it’s not very hard to give data a voice. One person in a location during any given day is normal — that fits right in with our assumptions about people with mobile devices. And if we look at the location data we got from one day at Penn Station in New York City, it’s about what we would expect:
There’s a high density of coordinates in the middle of Madison Square Garden, which is what we would expect since Penn Station’s main Amtrak waiting area is right there just below ground level. If we filter this down to only those coordinates where many people connected at the same location within a single day, we get a different picture:
We still see a number of hits in the Amtrak waiting area, many of them practically on top of one another. I’m willing to bet most of those are spots right in front of a schedule board or right next to an electrical outlet. We also have several hits in between Madison Square Gardens and Two Penn Plaza (the rectangular building to the east), where, one level below the Amtrak level, is the Long Island Rail Road waiting area. We also have some on the other side of Two Penn Plaza, which is a major taxi pickup area. In other words, even though these coordinates were attached to more devices than we would normally expect (some of them had as many as 50 devices), the pattern is plausible.
However, I was only able to recognize that plausibility by happening to know something about the area I was looking at. That’s not scalable. So I took the basic map visualization functionality I’d already put together, and incorporated it into a workflow that pulled shapefiles of US administrative divisions (states, counties, cities, and zip codes), matched up the device coordinates dataset with the shapes, and then used the frequency of devices-per-coordinate-pair to let the data say something about how normal a particular device count was.
I divided the count of unique devices by the maximum count found within the boundaries of the administrative division I was looking at. In most cases, the grand majority of the hits were less than 1% of the maximum, so I took all of those that are 50% or more of the maximum. I then started paging through satellite images overlaid with the coordinates, looking for stories. Many looked like I expected them to — one or two points in the entire shape. Then I landed in a zip code on the outskirts of Fort Worth:
It’s a grid. There are a couple points that don’t fit the grid, and there are naturally parts of the grid missing, but there’s patterning there. Paging through more results, I found the same thing in zip codes in Boise, San Antonio, Colorado Springs. Here’s one in Manhattan:
Note that those circles I plotted on the image are much larger than the actual locations — I enlarged them for visibility. In reality, each circle is about four inches in diameter.
This took me in a whole new direction. I worked up a simple algorithm to automatically identify the grids — I took all coordinates that had a lot of unique devices attached to them, calculated the angle of rotation from the x-axis for each coordinate pair, kept the top four angles from that process, and then filtered out all coordinates that weren’t attached to another coordinate by at least one of those angles. Each circle on the following map represents a grid I discovered through that process:
Here’s a zoom in on one cluster of grids:
Each node in the grid was a four-inch patch, separated from other nodes by at least one kilometer. The distances and angles differed for different places — it wasn’t a single grid over the whole world. It captured a large number of the coordinates that had comparatively extreme counts of devices. And I never would have found it if I hadn’t built a tool to allow the data to create stories on demand about what was normal and what wasn’t.
One other feature of these grids: nearly all of them involved weather apps. However those apps created far more coordinates that didn’t fall within a grid than coordinates that did, and many of the apps involved in the coordinates weren’t obviously weather-related. But it gave me the idea that this could maybe be a weather grid, and so I spent the better part of week researching and downloading weather grid projections from the U.S. National Weather Service. I finally found one that had roughly the same granularity as what I was seeing in my data (the device coordinates are in yellow, the weather grid in white):
But the grid wouldn’t match up. After staring at pictures like the one above for a very long time, I suddenly realized something obvious:
The weather grid (white) is a proper grid — the nodes form right angles. The same is not true of the data grid (yellow). Because the National Weather Service only uses proper grids, by definition the pattern I was seeing in the data couldn’t have come from the National Weather Service. I was stumped until, as often happens in ethnographic fieldwork, I had a random conversation on a seemingly unrelated topic that gave me some sudden insight. In this case, the conversation was with the front seat of my car:
Notice the pattern in the fabric. Imagine centroids in the middle of each of those hexagons. I hadn’t been able to find an appropriate weather grid because I had been searching for “weather grid”. I need to be searching for “weather mesh”. As soon as I did:
Apparently the Weather Company (owned by IBM and owner of both the Weather Channel and Weather Underground) collaborated with the climate group at Los Alamos to develop a mesh that could be stretched to have higher resolution at some places in the world and shrunk to have lower resolution at others. Their implementation of that mesh is proprietary, and is possibly subject to change over time as their forecasting needs change. And the weather channel hosts an API that allows others to serve weather, which explains why so many other apps end up falling into the hexagon centroids as well. However, weather apps have tons of hits outside of these centroids, which suggests they only provide centroid data sometimes, perhaps only when location services are disabled on a device. It makes a whole lot of sense for the Weather Company to use some sort of a grid or mesh to decide what forecasts to serve users, and it makes a whole lot of sense for apps to simply report the centroids of those hexagons when reporting user location — a simple coordinate pair is all most of these reporting systems ask for. Here, understanding the design of the data-generation process enables the most accurate use of the data
This series of discoveries changed the entire design of how I addressed this issue of location precision calibration:
- Look only at coordinates from specific weather apps
- Pick coordinates that have multiple devices attached to them.
- Partition the data into arbitrary groups of nearby coordinates (administrative shapes no longer necessary because now I know what I’m looking for).
- Pick the top n-most common angles of rotation between coordinate pairs within a group, and pick the most frequent distance between coordinate pairs that exhibit each angle of rotation.
- Go through all coordinates (not just those with multiple devices), keeping only those that are connected by one of the selected angles of rotation, and are separated by roughly the typical distance for that angle of rotation.
- Build in an update process since the grid nodes can change over time.
- Look for outliers in administrative divisions using a standard changepoint detection approach, but only after the grid coordinates have been removed.
By building tools to give data a voice — to show me in rough but intuitive terms what the coordinates looked like under different assumptions of how many devices was considered “normal” — the problem changed from a purely technical challenge of parameterizing a changepoint analysis, to a design problem of how to accommodate a widespread but systematically imprecise location reporting system. And by removing the grid coordinates ahead of time, it made my changepoint detection much more straightforward — it substantially increased the states, counties, cities, and zip codes in which there was only one set of coordinates with an extreme device count. And, as a bonus, it flagged coordinates that couldn’t be trusted (at least at the precision those coordinates gave), even though the device count at those coordinates wasn’t extreme at all.
We need a good question-generating toolset
Data science is currently very good at coming up with answers. It’s not very good at coming up with questions. I believe that requires data scientists to pay more attention to building non-technical skills, but I think it also requires us to build more tools that facilitate that part of the process. In fact, building the tools will contribute, in large measure, to building the non-technical skills.
The examples I gave used in this post was of a relatively easy use case, as geospatial data lends itself to straightforward, intuitive communication. Other kinds of data and other kinds of business problems will present more of a challenge. It’s a challenge worth undertaking. A focus on design — not just being aware of it but actively building our design intuition, competency, and toolset — is the best chance data science has to survive the increasing automation of core technical functions, and the heightened scrutiny of a public increasingly skeptical of the idea that algorithms can ethical as well as scalable.


