With a lot going on, what happened in 2018, and what looks promising for 2019?
This year can be considered the booming of Artificial Intelligence (AI). Just look at the number of startups with the term AI in their taglines; where acquisitions from big companies focused on; and the topics at the biggest tech conferences. AI is everywhere — even if just as a buzzword. But what actually is AI? That’s a rather difficult and controversial question to answer.

Hype bag-of-words. Let’s not focus on buzzwords, but on what the beneath technologies can actually solve.
What is clear is that data science is solving problems. Data is everywhere, and the uses we are making out of it (science) are increasing and impacting society more and more. Let’s focus on Data Science, while other philosophize on the best definition of AI.
While other buzzwords keep thriving, how’s data science?
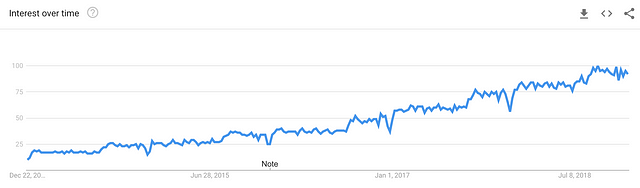
Interest for “data science” term since December 2013 (source: Google Trends)
The interest is not bad at all! I keep making my stand that data science is not a buzzword. Even for people now joining data science — and there are a lot of them — you just need to make a quick job search on LinkedIn and you’ll be amazed by the number of offers. Let’s start by taking a look at what has happened in 2018 and then focus on hot topics for 2019.
Today
Last year, I published an article on my expectations on Data Science trends for 2018. The main developments I mentioned were: automation of workflows, explainability, fairness, commoditization of data science and improvements in feature engineering/cleaning tools.
Regarding automation, the data scientists’ job is, very often, the automation of their own work. Companies open sourcing their own automation pipelines is common nowadays. Others, just keep selling it, but every day with more competition (e.g., Microsoft Azure, H2O, Data Robot, Google). Fortunately, data science is a transversal discipline and the same algorithms that are used in healthcare can be used, with some tweaks, in agriculture. So, if a company fails in a vertical, their developments can be quickly adapted to another field.
These tools are becoming regular commodities that you don’t even need to know how to code to use them. Some of them were born out of the scarcity of data science talent some years ago and were turned into profitable products afterward. This recalls one of the principles of Rework book — sell your by-products.

Ways to make humans trust machines are being paved (image by rawpixel)
Explainability and fairness saw great developments in 2018. There are now many more available resources. Tools that were just Python alpha versions have matured (e.g., SHAP). Also, you can easily find structured and supported books on the topic, such as Interpretable Machine Learning book, by Christoph Molnar. Understanding highly complex models is going in the right direction by decreasing barriers — Google’s What-If Tool is a great example.
Feature engineering is still one of the main secret sauces of Data Science solutions — take a look at the description of the winning solution for Home Credit Default Risk in Kaggle. While much of the best features are still manually created, Feature Tools became one of the main feature engineering libraries this year, for the lazy (smart?) data scientist. The problem of these tools is that you need to have data standards across your business, i.e., if one of your clients delivers data in one format, you should make sure the second client follows the same procedure — otherwise, you’re going to have a lot of undesirable manual work.
Finally, if we delivered Oscars to programming languages, Python would probably receive some of them. It is today the fastest-growing major programming language and the most wanted language for the second year in a row, according to Stack Overflow. At this rate, it is quickly becoming the most used programming language.
Tomorrow
So, what’s next? What can still be done?
There is plenty to be done in the above topics. And they will continue to be some of the main focus of data scientists in 2019, and the following years. The focus will be on maturing technologies while answering the questions:
- How can we minimize the time spent, by data scientists, on data cleaning and feature engineering?
- How can we define trust in the context of machine learning?
- If we say that a machine model is fair, what are its characteristics?

What are the principles according to which we can say that we trust a robot? (image by Andy Kelly)
But, besides these meta-questions, that are difficult to answer, what are the promising topics?
Reinforcement Learning might have gone through a lot of winters during its life. However, it looks like we are approaching another spring. A great example is the fantastic performance in Dota 2. There is a lot to be done, and a lot of computational power will be needed… But, anyway, reinforcement learning is the most human-like learning behavior we currently have and it’s exciting to see its applications.
We’ll most probably start seeing these proof-of-concepts turned into actual products. If you have the time, take a look at them and use OpenAI gym to develop them.
GDPR’s Recital 71: The data subject should have “the right… to obtain an explanation of the decision reached… and to challenge the decision.”
General Data Protection Regulation (GDPR) is in effect in EU since 25th of May 2018 and directly affects data science. The problem is: companies are still understanding the limits of this new regulation. Two of the main open topics are:
- Data Privacy. Companies that mishandle personal data are now threatened by huge fines. Does this mean that access to data will become more difficult for research? Will we see new developments in data synthetization? Can we truly anonymize data?
- Right to explanation. Fully automated decisions must be explainable. Well, that is great… But what does it actually mean “explainable”? Will we see the standardization of a machine learning interpretability algorithm? There isn’t an answer from EU entities on this — we’re just probably waiting for the biggest fine ever to be executed.
Trustworthy AI has two components: (1) it should respect fundamental rights, applicable regulation and core principles and values, ensuring an “ethical purpose” and (2) it should be technically robust and reliable since, even with good intentions, a lack of technological mastery can cause unintentional harm [EU AI Ethics]
As algorithms affect society more, we are entitled to make sure biases are mitigated, and their use is towards the benefit of the whole and not just a few. Fortunately, companies and institutions are working on this. The EU AI Ethics draft and the Google AI principles are perfect examples. There’s still a long way forward for ethics, but it’s now a recurrent discussed topic — and that’s good.

EU’s draft on AI ethics is an example on how governmental institutions are tackling the subject.
As algorithms become more complex, and more data is readily available (every gadget now generates data, right?), fewer people will be just using their laptops to do data science. We’ll use cloud-based solutions, even for the simplest projects (e.g., Google Colab). Time is scarce, GPUs are not… Laptops are not evolving fast enough to keep the pace with the required computational power.
Google Colab: making it easier to share notebooks and using more computational power.
Now, imagine you see a company with an open vacancy for the position of “Engineer” — just that. That’s great… But there are like 100 types of engineers nowadays. Is it a mechanical engineer? Aerospace? Software? “Engineer” is too generalist.
One or two years ago, companies would just publish a job vacancy as “Data Scientist”. Well, it is starting to feel incomplete. And if you’re just starting in this field, becoming a general data scientist might be too overwhelming. After having a grasp on this field, you better focus on a particular topic. Take for instance Netflix, which has nine Data roles:

Netflix data roles (source: Netflix Tech Blog)
There are a lot of specializations areas that didn’t exist before and itis becoming more important for data scientists focus on one to make a stand. It’s time to find your own if you haven’t already. From my point of view, Data Engineering skills are the most interesting ones for next years. If you don’t have them in your team, you’re probably just playing data science in Jupyter notebooks. And companies are realizing that.
2019 is going to be an amazing year, again. There’s a lot to be done, and it is not just techy and nerdy! Real problems to be solved are awaiting.
As a concluding remark, remember that time is our biggest asset. Every second you spend doing worthless is a second you just lost not doing something great. Pick your topic, and do not consider your work business as usual.


