Part 3: ML-Powered Web App in a Little Over 100 Lines of Code
This is Part 3 and I will be showing you how to build a machine learning powered data science web app in Python using the Streamlit library in a little over 100 lines of code.
The web app that we will be building today is the Penguins Classifier. The demo of this Penguins Classifier web app that we are building is available at http://dp-penguins.herokuapp.com/.
Previously, in Part 1 of this Streamlit tutorial series, I have shown you how to build your first data science web app in Python that is able to fetch stock price data from Yahoo! Finance followed by displaying a simple line chart. In Part 2, I have shown you how to build a machine learning web app using the Iris dataset.
As also explained in previous articles of this <em>Streamlit Tutorial Series</em>, model deployment is an essential and final component of the data science life cycle that helps to bring the power of data-driven insights to the hands of end users whether it be business stakeholders, managers or customers.

Overview of the Penguin Classification Web App
In this article, we will be building a Penguin Classifier web app for predicting the class label of Penguin species as being Adelie, Chinstrap or Gentoo as a function of 4 quantitative variables and 2 qualitative variables.

Penguins dataset
- Bill length (mm)
- Bill depth (mm)
- Flipper length (mm)
- Body mass (g)
- Sex (male/female)
- Island (Biscoe/Dream/Torgersen)
(Note: The full version of the Penguins dataset is available on the Data Professor GitHub)< Components of the Penguins Classifier web app
penguins_clf.pkl that can be quickly loaded in by the web app (without the need to build a machine learning model each time the web app is loaded by the user). 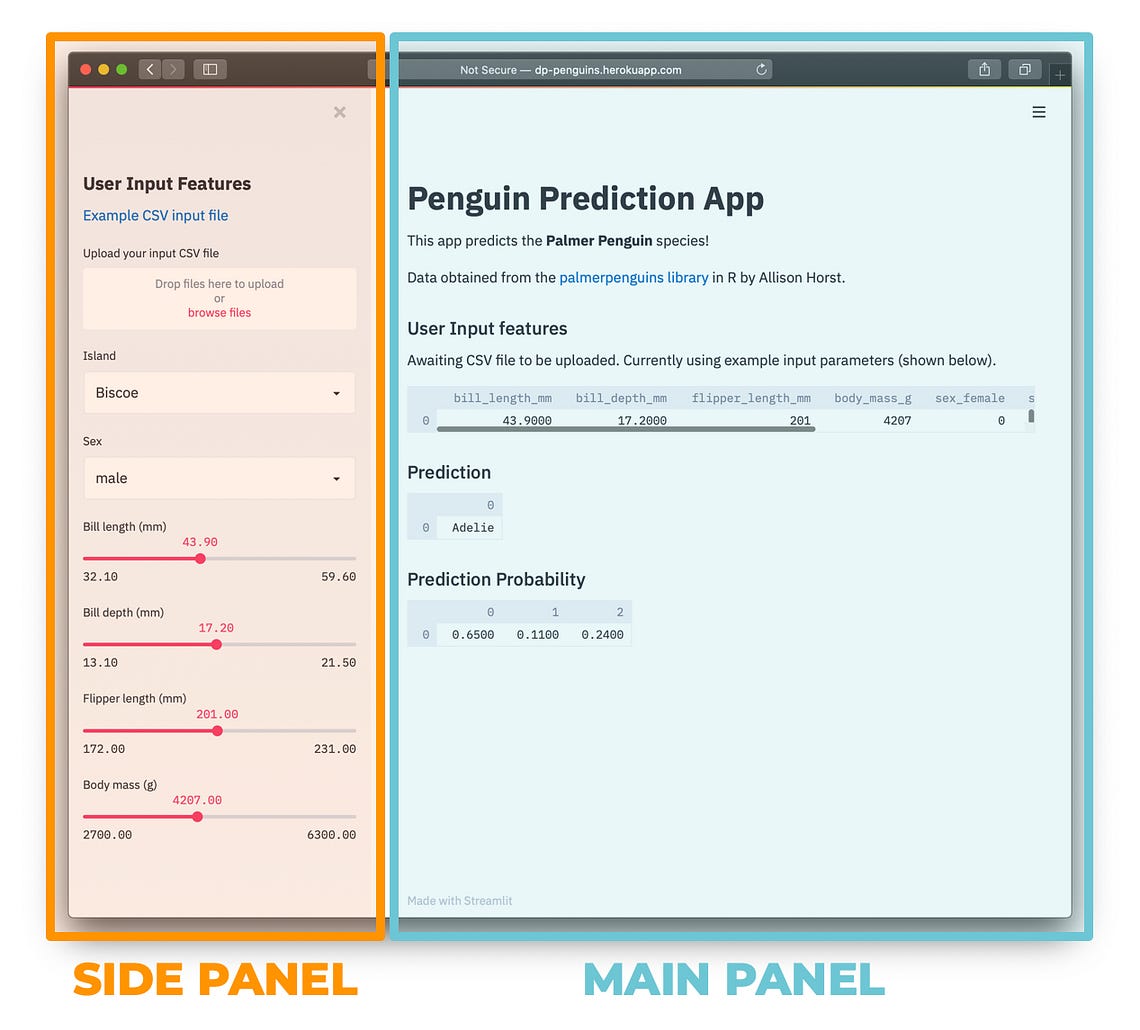
streamlit, pandas, numpy, scikit-learn and pickle. The first 4 will have to be installed if it is not yet already present in your computer while the last library is comes as a built-in library. To install the libraries, you can easily do this via thepip install command as follows:
pip install streamlit
streamlit with the name of other library such as pandas such that it becomes pip install pandas, and so forth. Or, you can install them all at once with this one-liner:
pip install streamlit pandas numpy scikit-learn
Codes of the web app
penguins-model-building.py and penguins-app.py. penguins-model-building.py) is used to build the machine learning model and saved as a pickle file, penguins_clf.pkl. penguins-app.py) will apply the trained model (penguins_clf.pkl) to predict the class label (the Penguin’s species as being Adelie, Chinstrap or Gentoo) by using input parameters from the sidebar panel of the web app’s front-end. Line-by-line explanation of the code
penguins-model-building.
Let’s start with the explanation of this first file that will essentially allow us to pre-build a trained machine learning model prior to running the web app. Why are we doing that? It is to save computational resources in the long run as we are initially building the model once and then applying it to make indefinite predictions (or at least until we re-train the model) on user input parameters made on the sidebar panel of the web app.
penguins-model-building.py
- Line 1
Import thepandaslibrary with alias ofpd - Line 2
Reads the cleaned penguins dataset from CSV file and assigning it to thepenguinsvariable - Lines 4–19
Perform ordinal feature encoding on the 3 qualitative variables comprising of the target Y variable (species) and the 2 X variables (sexandisland).

- Lines 21–23
Separates thedfdataframe toXandYmatrices. - Lines 25–28
Trains a random forest model - Lines 30–32
Saves the trained random forest model to a pickled file calledpenguins_clf.pkl.
penguins-app.py
This second file will serve the web app that will allow predictions to be made using the machine learning model loaded from the pickled file. As mentioned above, the web app accepts inout values from 2 sources:
- Feature values from the slider bars.
- Feature values from the uploaded CSV file.
penguins-app.py
- Lines 1–5
Importstreamlit,pandasandnumpylibraries with aliases ofst,pdandnp, respectively. Next, import thepicklelibrary and finally imports theRandomForestClassifier()function fromsklearn.ensemble. - Lines 7–13
Writes the web app title and intro text.
Sidebar Panel
- Line 15
Header title of the sidebar panel. - Lines 17–19
Link to download an example CSV file. - Lines 21–41
Collects feature values and puts it into a dataframe. We are going to use conditional statements if and else for determining whether the user has uploaded a CSV file (if so then read the CSV file and convert that into a dataframe) or enter feature values by sliding the slider bars whose values will also be converted into a dataframe. - Lines 43–47
Combines user input features (either from CSV file or from the slider bars) with the entire penguins dataset. The reason for doing this is to ensure that all variables contain the maximal number of possible values. For instance, if the user input contains data for 1 penguin then the ordinal feature encoding will not work. The reason is because the code will detect only 1 possible value for qualitative variables. For ordinal feature encoding to work, each of the qualitative variable will need to have all possible values.
Situation A
island has only 1 possible value which is Biscoe.
The above input feature will produce the following ordinal features after encoding.
Situation B
The above input features will produce the following ordinal features.
- Lines 49–56
Performs ordinal feature encoding in a similar fashion as explained above in the model building phase (penguins-model-building.py). - Lines 58–65
Displays the dataframe of the user input features. Conditional statements will allow the code to automatically determine either to display the dataframe of data from the CSV file or from the slider bars. - Lines 67–68
Loads the predictive model from the pickled file,penguins_clf.pkl. - Lines 70–72
Applies the loaded model to make predictions on the df variable, which corresponds to input from the CSV file or from the slider bars. - Lines 74–76
Predicted class label of the penguins species are displayed here. - Lines 78–79
Prediction probability values for each of the 3 penguins species are shown here.
Running the web app
streamlit run penguins-app.py
The following message should then be displayed in the command prompt:
> streamlit run penguins-app.py
> streamlit run penguins-app.py You can now view your Streamlit app in your browser. Local URL: http://localhost:8501 Network URL: http://10.0.0.11:8501
A screenshot of the penguins classifier web app is shown below:

Deploying and showcasing the web app
Great job! You have now created a machine learning-powered web app. Let’s deploy the web app to the internet so that you can share it to your friends and family.



