In this article, I will show you how to build a simple machine learning powered data science web app in Python using the streamlit library in less than 50 lines of code.
The data science life cycle is essentially comprised of data collection, data cleaning, exploratory data analysis, model building and model deployment. For more information, please check out the excellent video by Ken Jee on Different Data Science Roles Explained (by a Data Scientist). A summary infographic of this life cycle is shown below:

As a Data Scientist or Machine Learning Engineer, it is extremely important to be able to deploy our data science project as this would help to complete the data science life cycle. Traditional deployment of machine learning models with established framework such as Django or Flask may be a daunting and/or time-consuming task.
This article is based on a video that I made on the same topic on the Data Professor YouTube channel (How to Build a Simple Machine Learning Web App in Python) in which you can watch it alongside reading this article.
Overview of the Iris Flower Prediction App
Today, we will be building a simple machine learning-powered web app for predicting the class label of Iris flowers as being setosa, versicolor and virginica.
Perhaps, you have seen too many use of the infamous Iris dataset in tutorials and machine learning examples. Please bear with me on this one as the Iris dataset is merely used as a sort of “lorem ipsum” (typically used as fillers words in writing contents). I assure you that I will use other example datasets in future parts of this tutorial series.
This will require the use of three Python libraries namely <code>streamlit</code>, <code>pandas</code> and <code>scikit-learn</code>.
Let’s take a look at the conceptual flow of the app that will include two major components: (1) the front-end and (2) back-end.<
In the front-end, the sidebar found on the left will accept input parameters pertaining to features (i.e. petal length, petal width, sepal length and sepal width) of Iris flowers. These features will be relayed to the back-end where the trained model will predict the class labels as a function of the input parameters. Prediction results are sent back to the front-end for display.
In the back-end, the user input parameters will be saved into a dataframe that will be used as test data. In the meantime, a classification model will be built using the random forest algorithm from the
scikit-learn library. Finally, the model will be applied to make predictions on the user input data and return the predicted class labels as being one of three flower type: setosa, versicolor or virginica. Additionally, the prediction probability will also be provided that will allow us to discern the relative confidence in the predicted class labels. Install prerequisite libraries
In this tutorial, we will be using three Python libraries namely
streamlit, pandas and scikit-learn. You can install these libraries via the pip install command.
To install streamlit:
pip install streamlit
To install pandas:
pip install pandas
To install scikit-learn:
pip install -U scikit-learn
Code of the web app
Okay, so let’s take a look under the hood and we will see that the app that we are going to be building today is less than 50 lines of code (i.e. or 48 to be exact). And if we delete blank lines and comments (i.e. accounting for 12 lines) we can bring the number down to 36 lines.
Line-by-line explanation of the code
Okay, so let’s decode and see what each line (or code block) is doing.
Import libraries
- Lines 1–4
Importstreamlitandpandaslibraries with aliases ofstandpd, respectively. Specifically, import thedatasetspackage from the scikit-learn library (sklearn) where we will subsequently make use of the loader function to load the Iris dataset (line 30). Finally, we will specifically impor theRandomForestClassifier()function from thesklearn.ensemblepackage.
Side Panel
- Line 11
We will be adding the header text of the sidebar by usingst.sidebar.header()function. Notice that the use ofsidebarin betweenstandheader(i.e. thusst.sidebar.header()function) tells streamlit that you want the header to be placed in the sidebar panel. - Lines 13–23
Here we will be creating a customized function calleduser_input_features()that will essentially consolidate the user input parameters (i.e. the 4 flower characteristics that can accept the user specified value by means of the slider bar) and return the results in the form of a dataframe. It is worthy to note that each input parameter will accept user specified values by means of the slider button as inst.sidebar.slider(‘Sepal length’, 4.3, 7.9, 5.4)for the Sepal length. The first of the four input arguments correspond to the label text that will be specified above the slider button which in our case is‘Sepal length’while the next 2 values corresponds to the minimum and maximum value of the slider bar. Finally, the last input argument represents the default value that will be selected upon loading the web app, which is set to 5.4.
Model Building
- Line 25
As previously discussed above, the consolidated user input parameter information in the form of a dataframe will be assigned to thedfvariable. - Lines 30–38
This code block pertains to the actual model building phase.
* Line 30 — Loads in the Iris dataset from thesklearn.datasetspackage and assign it to theirisvariable.
* Line 31 — Creates theXvariable containing the 4 flower features (i.e. sepal length, sepal width, petal length and petal width) provided iniris.data.
* Line 32 — Creates theYvariable pertaining to the Iris class label provided iniris.target.
* Line 34 — Assign the random forest classifier, particularly theRandomForestClassifier()function, to theclfvariable.
* Line 35 — Train the model via theclf.fit()function by usingXandYvariables as input arguments. This essentially means that a classification model will be built by training it using the 4 flower features (X) and class label (Y).
Main Panel
- Lines 6–9
Uses thest.write()function to print out text, which in our case we are using it to print out the title of this app in markdown format (making use of the # symbol to signify header text (line 7) whereas normal descriptive text of the app is provided in the subsequent line (line 8). - Lines 27–28
This first section will be given the subheader text (assigned by using thest.subheader function) of‘User Input parameters’. In the subsequent line we will be displaying the contents of thedfdataframe via the use of thest.write()function. - Lines 40–41
In this second section of the main panel, the class labels (i.e. setosa, versicolor and virginica) and their corresponding index numbers (i.e. 0, 1 and 2) are printed out. - Lines 43–44
Predicted class labels are displayed in this third section of the main panel. It should be noted here that the contents of thepredictionvariable (line 45) is the predicted class index number and for the class label (i.e. setosa, versicolor and virginica) to be displayed we will need to use thepredictionvariable as an argument inside the bracket ofiris.target_names[prediction]. - Lines 47–48
In this fourth and last section of the main panel, the prediction probability are displayed. This value allow us to discern the relative confidence for the predicted class labels (i.e. the higher the probability values the higher confidence we have in that prediction).
Running the web app
So the code of the web app is saved into the iris-ml-app.py file and now we are ready to run it. You can run the app by typing the following command into your command prompt (terminal window):
streamlit run iris-ml-app.py
Afterwards, you should see the following message:
> streamlit run iris-ml-app.pyYou can now view your Streamlit app in your browser.Local URL: http://localhost:8501
Network URL: http://10.0.0.11:8501
A few seconds later, an internet browser window should pop-up and directs you to the created web app by taking you to
http://localhost:8501 as shown below. 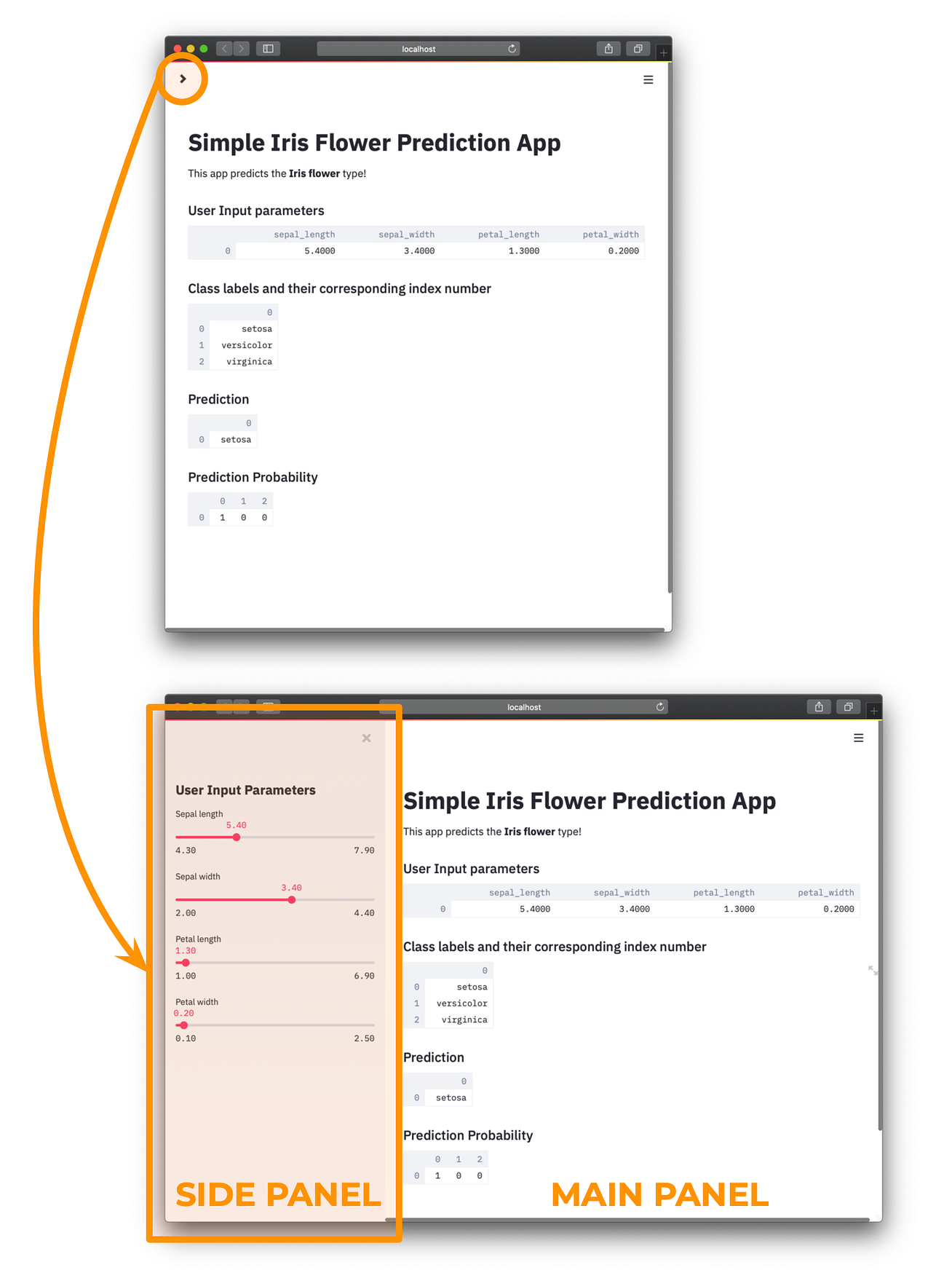
Congratulations! You have created your ML-powered web app in Python!
Now, it’s time to give yourself a pat on the back as you have now created a machine learning-powered web app. It’s now time to showcase this in your data science portfolio and website (i.e. you might want to customize the web app by using a dataset that interests you). Make sure to check out these videos on pointers and advice (Building your Data Science Portfolio with GitHub and How to Build a Data Science Portfolio Website with Hugo & Github Pages [feat. Data Professor]).



