
The Problem With Data & Statistics.
Data has a lot of power and authority in an argument. And this is the challenge: too often there is a made up a number underlining a bullshit story. But due to the authority of that number, we are much less suspicious if this number is really true. An actual example from an old Reebok campaign demonstrates this effect quite well:
By understanding some of the most common processes where misleading data and statistics are produced, we drastically reduce the chance of being trapped ourselves. With the correct deployment of data & statistics in a responsible, comprehensible and ethical way , we actively contribute to a better informed world — and doesn’t that sounds like an amazing mission for the future?
“It’s the shoe proven to work your hamstrings and calves up to 11% harder and tone your butt up to 28% more than regular sneakers … just by walking!”.
This just sounds so authoritative – based on data Reebok probably collected in very intense studies. Compare it to the following version formulated without concrete numbers:
“This shoe will make your hamstrings and calves harder and tone your butt just be walking.”
Truth is, the numbers were completely made up and the brand had to pay a significant penalty for the first statement. But how can you prevent yourself being trapped?
Understanding The Root Cause
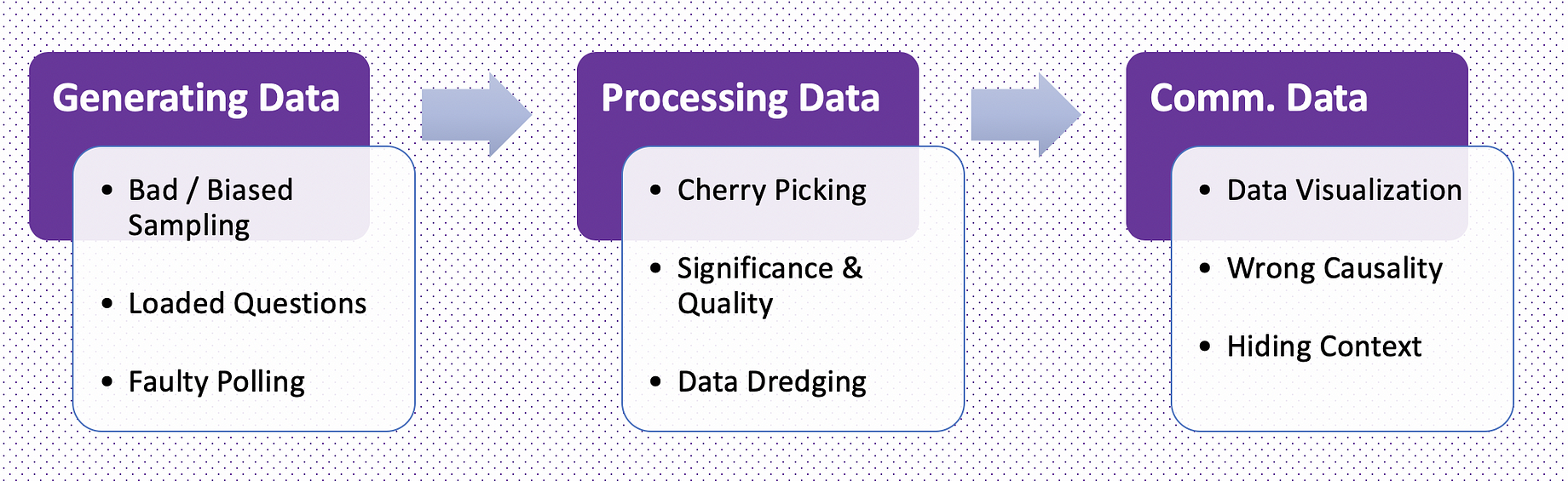
No matter if it is in business, science or your private environment — you can only avoid being mislead by “wrong” data, if you understand the root cause of it. Pitfalls can emerge in every step when working with data. Therefore this article sheds light in the most common pitfalls when it comes to working with data.
Pitfalls When Generating Data
Bad / Biased Sampling
Working with data from a non-random sample occurred many times in history It is the beginning of bad predictions and misleading with data. What happens in is that a significant mistake in the sample selection, excludes an essential factor to be truly representative.
Classic example is bad sampling of polls on the presidential elections. In 1948 the Chicago Tribune printed “Dewey defeats Truman”, which was based on a phone survey prior to the actual election. At this time phones were not the standard. They were predominantly available for the upper class. But when realizing that the sample was not random, already several thousand copies were printed. The picture above shows Truman as president laughing with one exemplar of the fake news in his hands.

Loaded Questions
Whenever it comes to generating data, this data has to come from a neutral resource. Loaded questions are exactly the opposite. They already contain an unjustified or controversial assumption with the objective to manipulated the output. A good example is product managers asking their users for feedback: “What do you love about the product we have build for you?” The question already implies that the user loves the product. It i is great if you want to collect some feedback and flatter yourself — but it has nothing to do with generating useful data or statistics.
Faulty Polling
Lorem ipsum dolor sit amet, consectetur adipiscing elit. Ut elit tellus, luc
Very much connected with loaded questions is faulty polling. It is often used to influence the answer of the respective sample.
“Do you think we should help unstable countries to keep freedom and have a democracy ?”
vs.
“Do you support our military fighting in other countries against their prevailing government?”
You clearly see the difference and the smear campaign in both questions. The first one trying to support countries interventions, the second one trying the opposite. In many cases it makes a lot of sense to look at the polls — you often get more insights than with the answers itself.
Pitfalls In Processing Data
As soon as data generation and acquisition is accomplished, data is processed. Data transforming, cleansing, slicing and dicing can produce many misleading results . In the following you find the three most frequent ones:

Cherry Picking / Discarding Unfavourable Data
It is quite common in research that you get a big dataset and have to work with that. The research question is already defined in best case and the researcher has a certain pressure to produce results. But what if the found results are not very interesting. And what if you have that much data, that interesting results can be produced, although they are simply a confidence. The temptation to use interesting results created by discarding unfavourable data, or by picking bits and pieces of that data set is high.

A good example is climate change: to underline the claim that climate change was always the same and does not change, the data time frame is very often limited from 2000 to 2013. If looking at this specific extract it may look like temperature anomalies were always the same.
Only within the big picture including the complete dataframe, the intense and rapid change of positive temperature anomalies gets visible.

Significance & Quality
We see quite often that experiments are conducted and results presented, without statistical significance. Within business context this happens quite often in so-called A/B Tests.
Statistical significance in the context of A/B testing is how likely it is that the difference between your experiment’s original version and test version isn’t due to an error or random chance. For example, a conversion rate of 7% in a test version with a green button does not necessarily mean it performs better than the alternative sample with a conversion rate of 5% if you only have a sample size of 200 visitors. There are several options to ensure significance for your hypothesis either via standardized software or by calculating it ourself. Here you can find a calculator to check the significance of your last A/B test.

Data Dredging
Data dredging, also called p-Hacking, describes the process of analyzing a dataset without any focus and hypothesis. By looking and testing for different combinations of significant variables, a huge amount of hypothesis will be tested. If you are testing a lot of hypothesis with the help of the p-value, it is very likely that you have a type 1 (or type 2 error). Simply because there are so many tests and the statistic probability of rejecting or accepting a hypothesis incorrectly increases. But let’s have a look at an actual example you may experienced from business live.
In a previous article we have predicted if a customer is likely to churn or not with statistical significance. But let’s assume that you have a bad data set and your test shows no statistical significance. You then start creating a hypothesis for each and every customer feature. And boom — finally your testing says that one of your hypothesis is significant: “Customers with blonde hair are more likely to churn after two years.”
By running so many tests a random hypothesis may appear significant, simply because so many tests were conducted. But in fact the conclusion is “false positive” — which means the testing falls into the 5% (significance level of 95%) chance of being wrong.
Pitfalls In Communicating Data
Whenever statistics and data is used to back up the creator’s intention, it is recommended to have a critical look at it from time to time.
Data Visualisation
Especially when it comes to data visualisation, people love to apply some small adjustments with great consequences for the eye of the information consumer. There are tons of methods to mislead with grahps, charts and diagrams. In the following you find an excerpt of the most common ones.
- Truncated y-Axis: when comparing data without having the baseline at zero, a data visualisation as seen below can make a much more dramatic story than before.

- Leaving out data, often referred as “omitting data”, describes the absence of several data point in the chart, for example displaying only each data point of the second year. Interpretation and decision-making is based on half the information.
- Inappropriate scaling: This method is often use in time series or changes over time and work in both directions: Either the y-Axis is inappropriately increased, so the change seems to be not less intensive. Or the y-Axis is inappropriately lowered in order to make the effects look more determinative than before.
Wrong Causality / Conclusions
While finding statistical significant insights in data is the beginning of adding value, but you also have to be able to interpret the results correctly. A very good example how to not interpret results is the story of Abraham Wald and the missing bullet holes. Long story short he was part of the Statistical Research Group during World War II. The Airforce approached Wald with a problem: Too many planes are shot down, while simply increasing the armpur overall would make it too heavy. They asked how they can add armour in an efficient way.

Wald investigated planes returning from war, collecting statistics and analysing it. He found areas with a lot and ares with less bullet wholes. First it was intuitively assumed to place more armour where more bullet wholes are. But that was the wrong conclusion. As the statistic sample were planes that returned, the areas with less bullet wholes are the important ones and probably targets hit at the planes that did not make it back.
“Gentlemen, you need to put more armour-plate where the holes aren’t, because that’s where the holes were on the planes that didn’t return.” — Abraham Wald
Hiding Context
Useful data visualisations make large amounts of data easy to understand and interpret. The audience should be able to look at the presented data and quickly find the important information. If there is presented too much or irrelevant data, the audience may not see the relevant information. The more data is displayed at once, the harder it gets to detect specific trends. Misleading with too much data is often used to mislead the audience from the small but relevant insights.
Conclusion
By understanding some of the most common processes where misleading data and statistics are produced, we drastically reduce the chance of being trapped ourselves. With the correct deployment of data & statistics in a responsible, comprehensible and ethical way , we actively contribute to a better informed world — and doesn’t that sounds like an amazing mission for the future?



