How do they compare to data scientist tech skills?
Data Engineer is the fastest growing job title according to a 2019 analysis. Data engineers play a vital role for organizations by creating and maintaining pipelines and databases for injesting, transforming, and storing data.
Which tech skills are most in demand for data engineers? How do they compare to the most in demand tech skills for data scientists? Read on to find out!

I analyzed job listings for data engineers in January 2020 to see which technology skills are most in demand. I compared the results to data scientist job listings and uncovered some interesting differences.
Without further ado, here are the top 10 technologies from data engineer job listings as of January 2020.
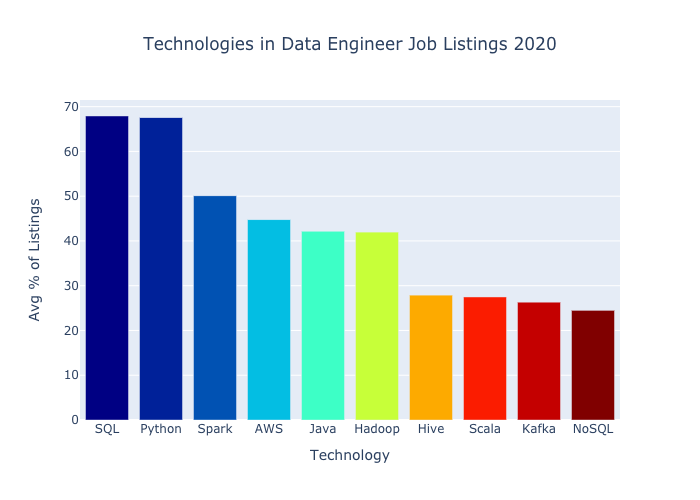
Let’s jump in!
Data Engineer Role
Data engineers have a vital role to play in today’s organizations. They are responsible for storing and making data usable by others.
Data engineers set up pipelines to injest streaming and batch data from many sources. Then the pipelines perform extract, transform, and load (ETL) processes to make the data more usable. The data is then made available to data scientists and data analysts for further processing. Eventually the data finds its way into dashboards, reports, and machine learning models.
I searched for data to determine which technologies are most in demand for data engineers in 2020.
Method
I scraped information from SimplyHired, Indeed, and Monster, to see which keywords appeared with “Data Engineer” in job listings in the United States. I used the Requests and Beautiful Soup Python libraries.



I included keywords from my analysis of data scientist job listings and from reading data engineer job listings. LinkedIn was not searched due to previously locking me out of my account after scraping.
For each job search website, I calculated the percentage of total data engineer job listings for that site that each keyword appeared in. Then I averaged those percentages across the three sites for each keyword.
Results
Here are the thirty highest scoring data engineer technology terms from the job listing search results.
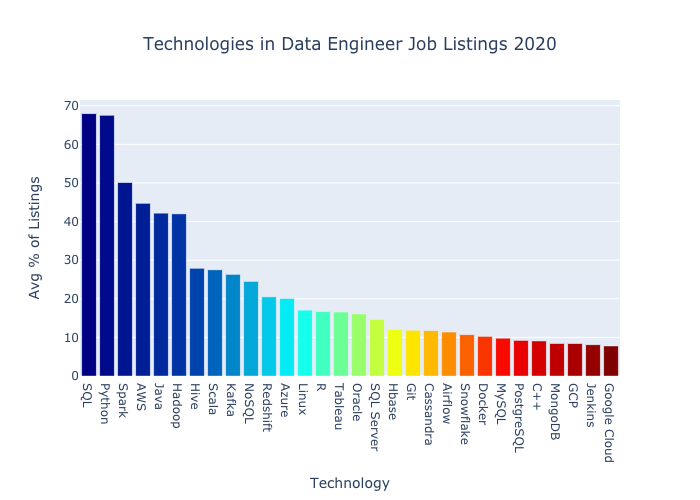
Below is the same percentage data in tabular form.

Let’s break this down.
Discussion


SQL and Python both appear in over two-thirds of job listings. They are the top two technologies to know.
Python is a very popular programming language for working with data, websites, and scripting.
SQL stands for Structured Query Language. SQL is a standard implemented by a family of languages and is used for getting data out of relational databases. It has been around for ages and has shown its resiliency.

Spark appears in about half of all listings. Apache Spark is “a unified analytics engine for big data processing, with built-in modules for streaming, SQL, machine learning and graph processing”. It’s particularly popular with really big datasets.

AWS is in about 45% of listings. AWS is Amazon’s cloud computing platform. It has the largest marketshare of any cloud platform.
Then come Java and Hadoop, each in just over 40% of listings.
Java is a commonly used, battle-tested language that was the 10th most dreaded in Stack Overflow’s 2019 Developer Survey. In contrast, Python was the second most loved language. Oracle controls Java and this website home page, from January 2020, tells you all you need to know about it.

It’s like a time machine.
Apache Hadoop uses the MapReduce programming model with sever clusters for big data. The MapReduce model is falling out of favor.
Then come Hive, Scala, Kafka, and NoSQL, each in about a quarter of data engineer listings.
Apache Hive is data warehouse software that “facilitates reading, writing, and managing large datasets residing in distributed storage using SQL”.
Scala is programming language popular with big data. Spark was built with Scala. Scala is the 11th most dreaded language in Stack Overflow’s 2019 Developer Survey results.
Apache Kafka is a distributed streaming platform. It’s very popular for injesting streaming data.
NoSQL databases stand in opposition to SQL. NoSQL databases are non-relational, unstructured, and horizontally scalable. NoSQL is quite popular, but previous hype of it displacing SQL as the dominant storage paradigm seems to overblown.
Comparison with Data Scientist Terms
Here are top 30 data scientist job listing technology terms, arrived at through the same methodology as the data engineer terms.
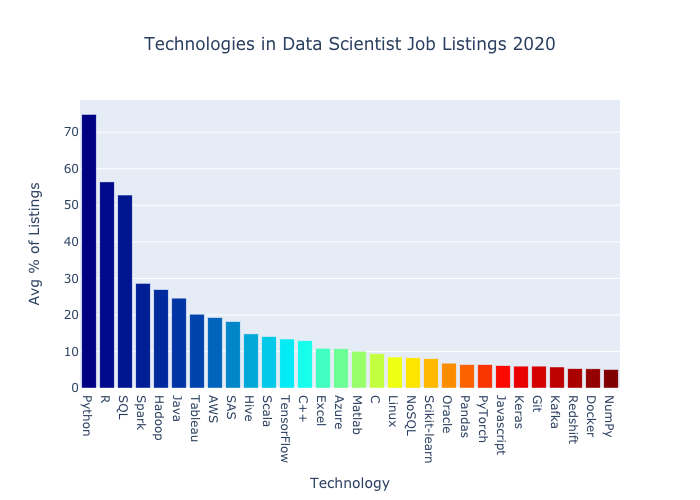
In terms of total listings, there were about 28% more data scientist listings than data engineer listings (12,013 vs. 9,396).
Let’s see which terms were more common in data engineer listings than data scientist listings.
More common for data engineers
The chart below shows the keywords with average differences greater than 10% and less than -10%.
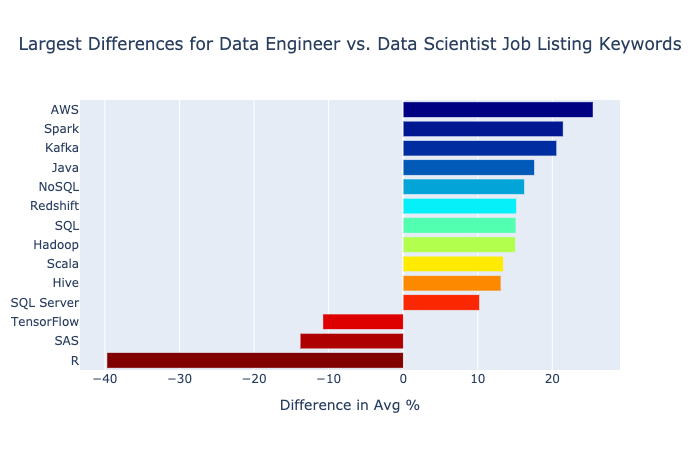
AWS had the largest increase, appearing in about 25% more listings for data engineers than data scientists. It showed up in about 45% of data engineer listings and about 20% of data scientist listings. That’s quite a difference!
Here’s another look at the same data that shows the results for data engineer and data scientist job listings side by side:
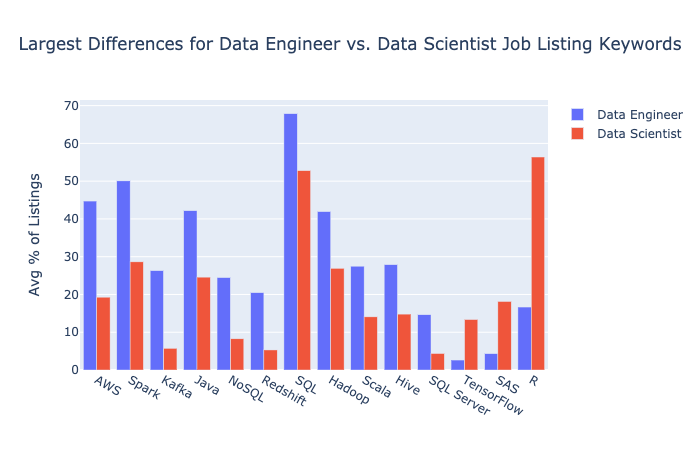
Spark showed the second largest increase. Data engineers are often dealing with big data.
Kafka saw an increase of 20%, too. That’s about four times the percentage data scientist listings. Injesting data is a core job for data engineers.
Java, NoSQL, Redshift, SQL, and Hadoop appeared in about 15% more data engineer listings.
Less common for data engineers
Now let’s look at which skills are less popular in data engineer job listings.
R saw the largest drop from data scientist to data engineer listings. It was in about 17% of listings, instead of about 56%. Wow. R is a programming language popular with academics and statisticians. It was Stack Overflow Survey respondent’s 8th most dreaded language.
SAS is also much less common in data engineer listings, with a difference of about 14%. SAS is a proprietary language for statistics and data. Interestingly, my recent analysis of data scientist job listings showed that SAS fell more than any other technology.
Important for both data engineers and data scientists
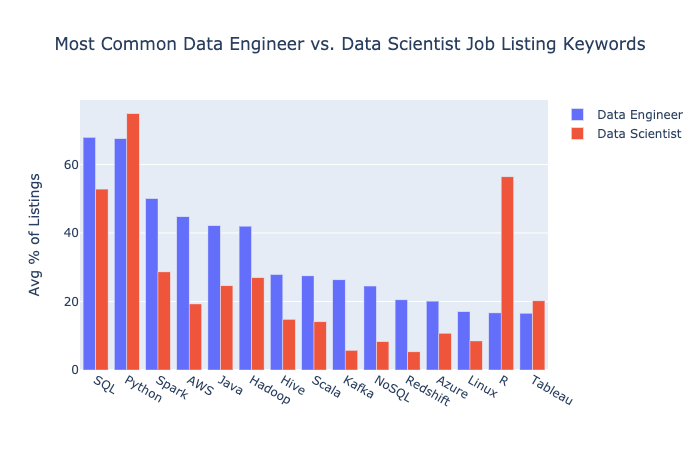
It’s worth noting that eight of the top ten technologies were shared between data scientist and data engineer job listings. SQL, Python, Spark, AWS, Java, Hadoop, Hive, and Scala were on both top 10 lists.
Here are the 15 most common data engineer terms, along with their prevalence in data scientist listings.
Advice
If you want to be a data engineer, I suggest you learn the following technologies, roughly in order of priority.
Learn SQL. I suggest you learn PostgreSQL because it’s open source, popular, and growing. My Memorable SQL book shows you how to use PostgreSQL and is available in pre-release here.
Learn vanilla Python. My Memorable Python book is designed for Python newbies. It’s available for Kindle and hard copy from Amazon and in .epub and .pdf form here.

Once you know basic Python, learn pandas, a Python library for cleaning and manipulating data. If you are looking for a data job that requires Python, and most do, you can expect the organization is expecting you to have pandas skills, too. I’m finishing up an introductory pandas book, so join my Data Awesome newsletter to make sure you don’t miss it.

Pandas snacking
Learn AWS. If you want to be a data engineer, you need a cloud platform under your belt and AWS is the most popular. I found Linux Academy online courses helpful when learning Google Cloud Data Engineering skills, and expect they would be helpful for AWS.
If you know all those technologies and want to become more in demand as a data engineer, I suggest you learn Apache Spark for big data. Although my research on data scientist job listings shows it’s falling in popularity, it’s still in nearly half of all data engineer job listings.

Spark
Wrap
I hope you found this guide to the most in demand technologies for data engineers useful.


