Ready to learn Big Data? Browse Big Data Training and Certification Courses developed by industry thought leaders and Experfy in Harvard Innovation Lab.
Learn how to build killer datasets by avoiding the most frequent mistakes in Data Science, plus tips, tricks and kittens.

Introduction
If you haven’t heard it already, let me tell you a truth that you should, as a data scientist, always keep in a corner of your head:
“Your results are only as good as your data.”
Many people make the mistake of trying to compensate for their ugly datasetby improving their model. This is the equivalent of buying a supercarbecause your old car doesn’t perform well with cheap gasoline. It makes much more sense to refine the oil instead of upgrading the car. In this article, I will explain how you can easily improve your results by enhancing your dataset.
Note: I will take the task of image classification as an example, but these tips can be applied to all sorts of datasets.
The 6 Most frequent mistakes, and how to fix them.

1. Not enough data.
If your dataset is too small, your model doesn’t have enough examples to find discriminative features that will be used to generalize. It will then overfityour data, resulting in a low training error but a high test error.
Solution #1: gather more data. You can try to find more from the same sourceas your original dataset, or from another source if the images are quite similar or if you absolutely want to generalize.
Caveats: This is usually not an easy thing to do, at least without investing time and money. Also, you might want to do an analysis to determine how much additional data you need. Compare your results with different dataset sizes, and try to extrapolate.

In this case, it seems that we would need 500k samples to reach our target error. That would mean gathering 50 times as much data as we have for the moment. It is probably more efficient to work on other aspects of the data, or on the model.
Solution #2: augment your data by creating multiple copies of the same image with slight variations. This technique works wonders and it produces tons of additional images at a really low cost. You can try to crop, rotate, translate or scale your image. You can add noise, blur it, change its colors or obstruct parts of it. In all cases, you need to make sure the data is still representing the same class

All this images still represent the “cat” category
This can be extremely powerful, as stacking these effects gives exponentially numerous samples for your dataset. Note that this is still usually inferior to collecting more raw data.

Combined data augmentation techniques. The class is still “cat” and should be recognized as such.
Caveats: all augmentations techniques might not be usable for your problem. For example, if you want to classify Lemons and Limes, don’t play with the hue, as it would make sense that color is important for the classification.


2. Low quality classes
It’s an easy one, but take time to go through your dataset if possible, and verify the label of each sample. This might take a while, but having counter-examples in your dataset will be detrimental to the learning process.
Also, choose the right level of granularity for your classes. Depending on the problem, you might need more or less classes. For example, you can classify the image of a kitten with a global classifier to determine it’s an animal, then run it through an animal classifier to determine it’s a kitten. A huge model could do both, but it would be much harder.
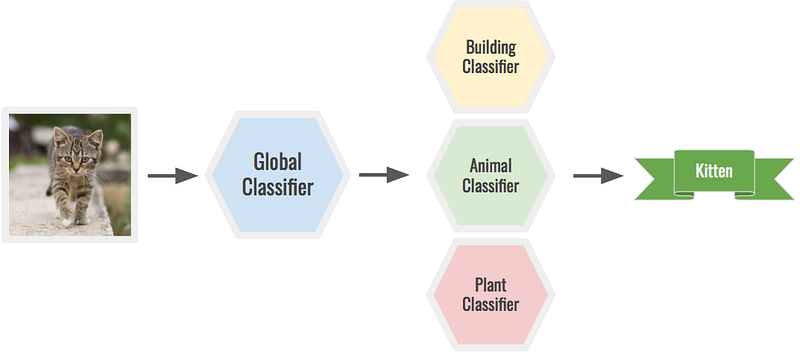
Two stage prediction with specialized classifiers.

3. Low quality data
As said in the introduction, low quality data will only lead to low quality results.
You might have samples in your dataset f your dataset that are too far from what you want to use. These might be more confusing for the model than helpful.
Solution: remove the worst images. This is a lengthy process, but will improve your results.

Sure, these three images represent cats, but the model might not be able to work with it.
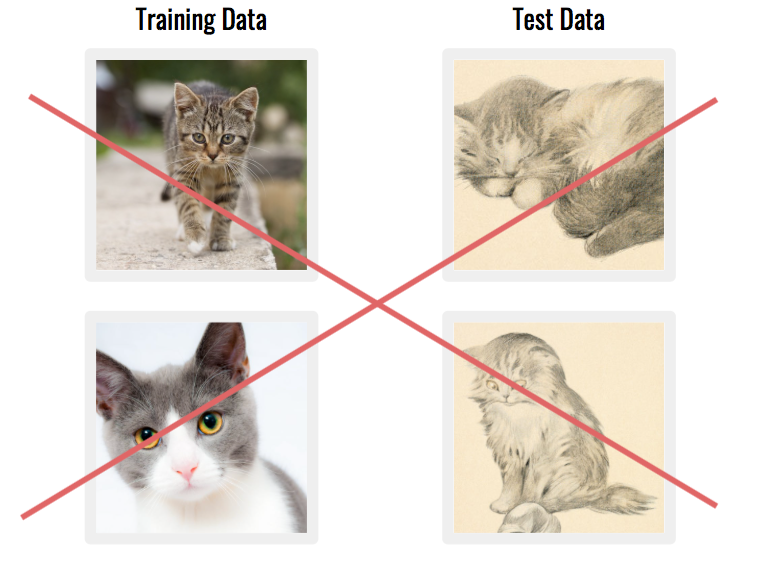
Another common issue is when your dataset is made of data that doesn’tmatch the real world application. For instance if the images are taken from completely different sources.
Solution: think about the long term application of your technology, and which means will be used to acquire data in production. If possible, try to find/build a dataset with the same tools.

4. Unbalanced classes
If the number of sample per class isn’t roughly the same for all classes, the model might have a tendency to favor the dominant class, as it results in a lower error. We say that the model is biased because the class distribution is skewed. This is a serious issue, and also why you need to take a look at precision, recall or confusion matrixes.
Solution #1: gather more samples of the underrepresented classes. However, this is often costly in time and money, or simply not feasible.
Solution #2: over/under-sample your data. This means that you removesome samples from the over-represented classes, and/or duplicate samples from the under-represented classes. Better than duplication, use data augmentation as seen previously.


5. Unbalanced data
If your data doesn’t have a specific format, or if the values don’t lie in the certain range, your model might have trouble dealing with it. You will have better results with image that are in aspect ratio and pixel values.
Solution #1: Crop or stretch the data so that it has the same aspect or formatas the other samples.

Two possibilities to improve a badly formatted image.
Solution #2: normalize the data so that every sample has its data in the samevalue range.


6. No validation or testing
Once your dataset has been cleaned, augmented and properly labelled, you need to split it. Many people split it the following way: 80% for training, and 20% for testing, which allow you to easily spot overfitting. However, if you are trying multiple models on the same testing set, something else happens. By picking the model giving the best test accuracy, you are in fact overfitting the testing set. This happens because you are manually selecting a model notfor its intrinsic value, but for its performance on a specific set of data.
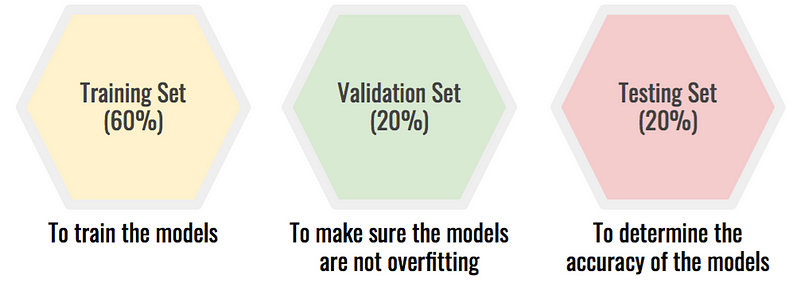
Solution: split the dataset in three: training, validation and testing. This shields your testing set from being overfitted by the choice of the model. The selection process becomes:
- Train your models on the training set.
- Test them on the validation set to make sure you aren’t overfitting.
- Pick the most promising model. Test it on the testing set, this will give you the true accuracy of your model.
Note: Once you have chosen your model for production, don’t forget to train it on the whole dataset! The more data the better!
Conclusion
I hope by now you are convinced that you must pay attention to your datasetbefore even thinking about your model. You now know the biggest mistakes of working with data, how to avoid the pitfalls, plus tips and tricks on how to build killer datasets! In case of doubt, remember:
“The winner is not the one with the best model, it’s the one with the best data.”.


