This post is part of a series of 3 articles about the GraphTech ecosystem, as of 2019. This is the first part. It covers the graph database landscape. The second part will be about graph analytics frameworks and the third part will list the existing graph visualization tools.

The graph database landscape in 2019
A dynamic ecosystem
The traction for graph storage systems is stronger than ever, with interest steadily growing since 2013.
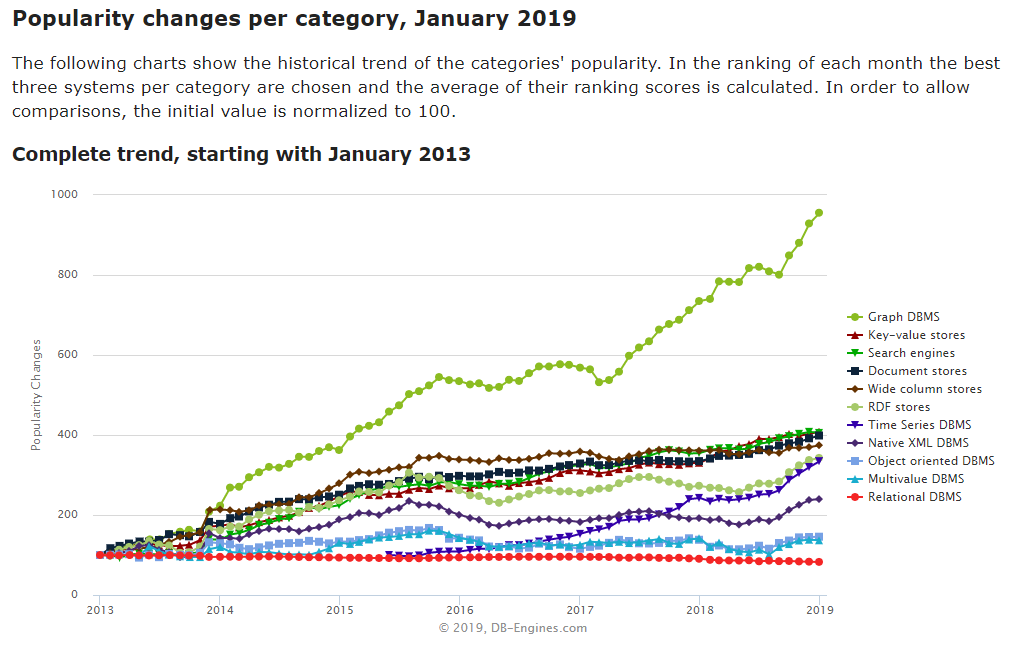
DBMS popularity trend by database model between 2013 and 2019 — Source: DB-Engine
The market shares of graph databases keep increasing, as well as the number of products on the market, with seven times more vendors than 5 years ago. New market studies with ever-larger financial projections are published every semester. Some say that the graph database market represented 39 million USD in 2017, other 660 million USD, and the projections range from 445 USD million in 2024 to 2.4 billion USD by 2023.
Although it seems difficult to agree on exact figures, all reports identify the same growth drivers:
- Need for speed and improved performances to reduce cost and time to discover new data correlations
- Limitations of current technology to handle multi-dimensional data in real-time
- Development of graph-based AI and machine learning tools and services
- In specific fields such as financial crimes, fraud, and security: a critical need to better address existing risks faster and leverage connected data.
In summary, we have an increasing number of applications relying on connected data to generate insights and urgent technological problems to handle growing data volumes and complexity, that are driving the graph market up.
It can be hard to keep track. In this article, I propose to present the current market, if not exhaustively, at least as well as possible. I divided the graph ecosystem into three main layers, even though the reality is more complex and these stratum are often permeable.
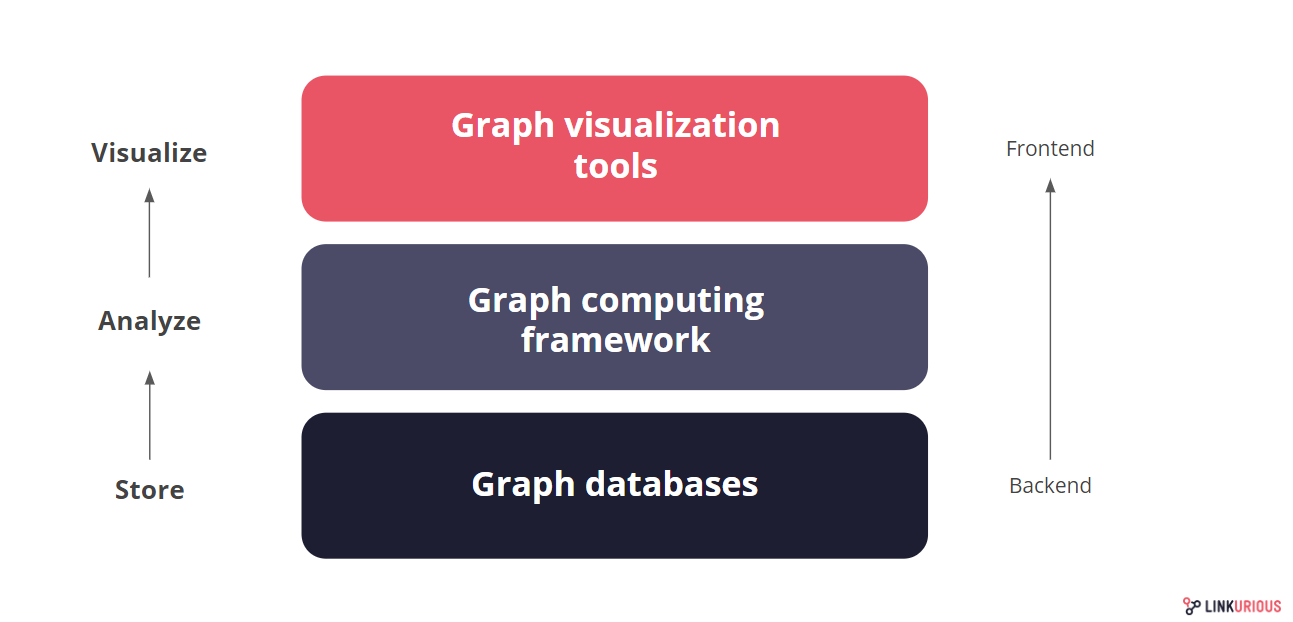
The GraphTech ecosystem layers
Graph databases landscape
GraphTech’s first layer plays a key role in the ecosystem growth. The graph database management systems (GDBMS) are driving the ecosystem. They are its main actors. These systems help organizations tackle the technical challenges of storing complex connected data and extracting insights from very large datasets.
Shaping the market
Since the 1960s, network models have existed in the world of databases, but the use of graph structures remained confined to the academic world. The performances and the models were not yet optimal, and we had to wait until the 2000s and the introduction of ACID graph databases to see a larger-scale adoption. From then, graph databases started to appear as a legit business solution to address some of the shortcomings of relational systems.
Native systems, built specifically for storing graph-like data, and non-native systems, with a different primary data-model (for example relational or other NoSQL databases), compose the market. On both sides, we find commercial and open source systems, as well as property graph and RDF triple store that are the two main models to store graph data.
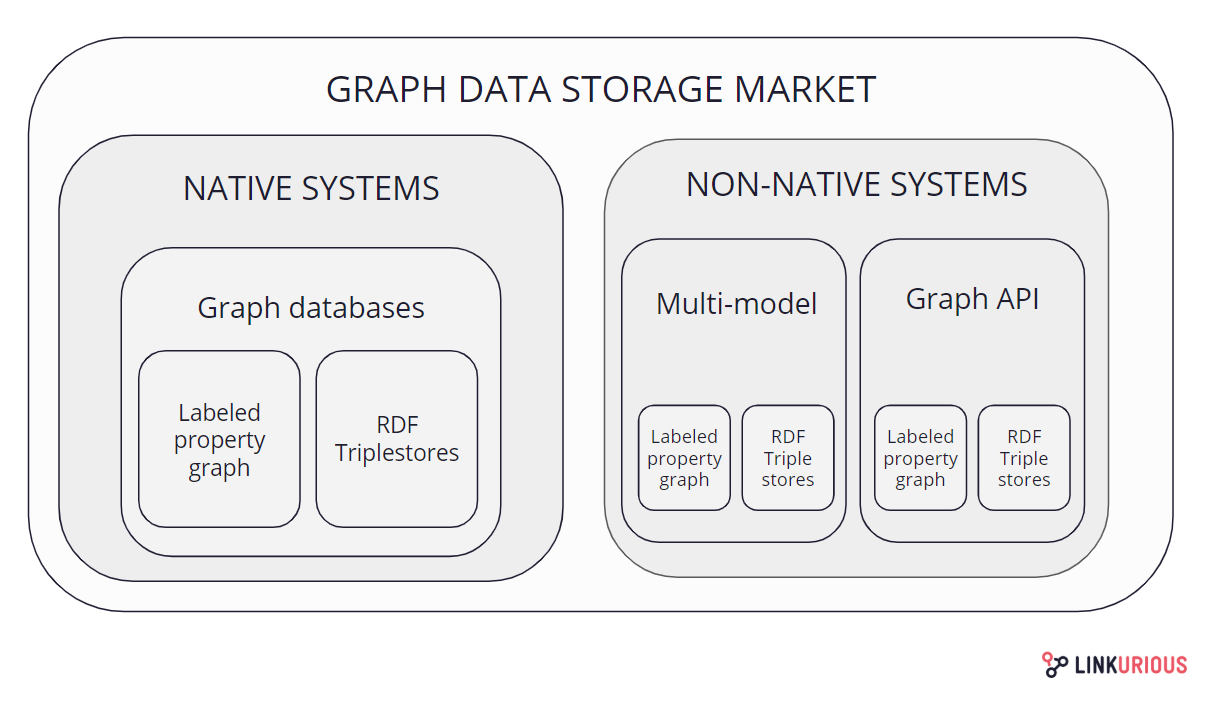
Type of storage for graph-like data
Native systems
Among the main native systems, which models are entirely optimized to work with graph-like data, Neo4j is the market leader. The first version of the native graph database was launched in 2010, proposing a dual commercial and open source edition for developers to experiment with graphs. The company has since gained a lot of customers and raised more than $150 million.
In the open-source community, JanusGraph took over the Titan project,whose parent company was acquired in 2015 by DataStax. The JanusGraph project now proposes a distributed, open-source graph database that has been gaining a lot of interest lately. DGraph is another open source project, written in Go, that released a production-ready version in 2017 while raising $3 million in seed funding.
Other solutions include Stardog, the RDF triple store for knowledge graph, or the recently launched TigerGraph (formerly known as GraphSQL). The commercial systems InfiniteGraph and Sparksee have now been around for a while. Other open source systems such as HypergraphDB propose databases based on directed hypergraphs.
Multi-model databases and hybrid systems
Following the success of NoSQL models, multi-model databases emerged as an answer to the complexity that the multiplication of siloed systems was creating. These databases are designed to support various data types, handling in one single data store various models such as document, key-value, RDF and graphs. They are particularly convenient if you need to work with multiple data types but want to avoid the operational complexity of managing various silos.
Among the native multi-model databases that include graph as a supported model, we can name ArangoDB. This open-source multi-model database was released in 2011 and supports three data models: key/value, documents and graphs. Cosmos DB is Microsoft Azure’s latest addition to the multi-model landscape. Launched in 2017, this distributed cloud database supports four data types: key-value, document, column family and graph. DataStax Enterprise is also a distributed cloud database, built on top of the open source NoSQL Apache Cassandra system. The system supports column family, documents, key-value, and graph since the addition of DataStax Enterprise Graph in 2016. Finally MarkLogic is a historical stakeholder who added RDF triples support to its existing supported document model back in 2013.
Another strong signal of market traction was the evolution of the database main players’ strategy. Over the last few years, we saw traditional relational store heavyweights add graph capabilities to their systems through dedicated APIs. In 2012, IBM added a NoSQL graph store, DB2-RDF to its database. One year later, Oracle rebranded its database graph option to Oracle Spatial and Graph, known today as Oracle Big Data Spatial and Graph. More recently in 2016, SAP Hana announced the released of SAP HANA Graph, expanding the capabilities of its relational DBMS with support for graphs.
I listed and presented a vast majority of storage systems for graph-like data in the following presentation.
In the next post, I’ll look over the second layer: graph analytics framework.
This article was initially published on Linkurious blog.


