This post is part of a series of articles about the GraphTech ecosystem. This is the second part. It covers the graph analytics landscape. The first part was about graph databases and the third part will list the existing graph visualization tools.
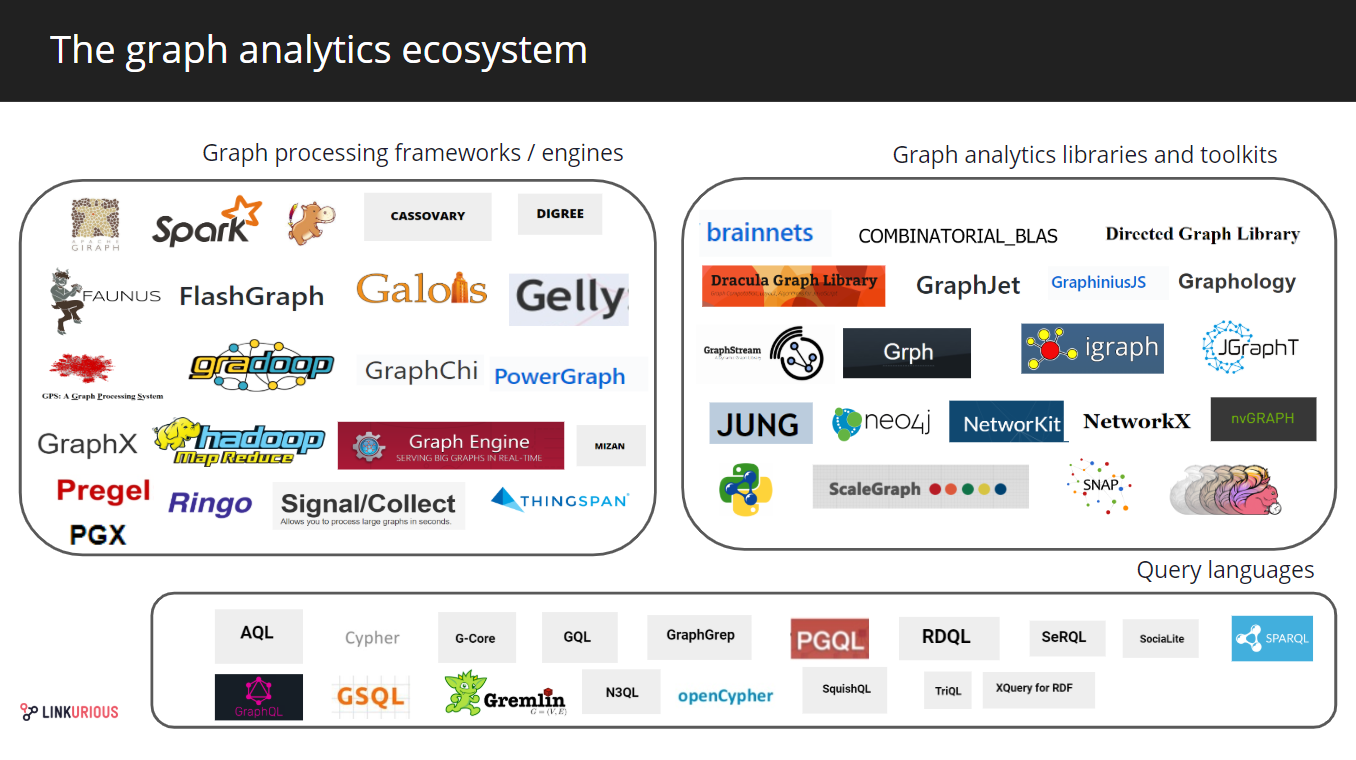
Actors of the graph analytics landscape in 2019
This second layer is another back-end layer: graph analytics, or computing, frameworks. They consist of a set of tools and methods developed to extract knowledge from data modeled as a graph. They are crucial for many applications because processing large datasets of complex connected data is computationally challenging.
A need for analytics at scale
The field of graph theory has spawned multiple algorithms on which analysts can rely on to find insights hidden in graph data. From Google’s famous PageRank algorithm to traversal and path-finding algorithms or community detection algorithms, there are plenty of calculations available to get insights from graphs.
The graph database storage systems we mentioned in the previous article are good at storing data as graphs, or at managing operations such as data retrieval, writing real-time queries or at local analysis. But they might fall short on graph analytics processing at scale. That’s where graph analytics frameworks step in. Shipping with common graph algorithms, processing engines and, sometimes, query languages, they handle online analytical processing and persist the results back into databases.
Graph processing engines
The graph processing ecosystem offers various approaches to answer the challenges of graph analytics, and historical players occupy a large part of the market.

Main graph engine processing and framework vendors
In 2010, Google led the way with the release of Pregel, a “large-scale graph processing” framework. Several solutions followed, such as Apache Giraph, an open source graph processing system developed in 2012 by the Apache foundation. It leverages MapReduce implementation to process graphs and is the system used by Facebook to traverse its social graph. Other open source systems iterated on Google’s, for example, Mizan or GPS.
Other systems, like GraphChi or PowerGraph Create, were launched following GraphLab’s release in 2009. This system started as an open-source project at Carnegie Mellon University and is now known as Turi.
Oracle Lab developed PGX (Parallel Graph AnalytiX), a graph analysis framework including an analytics processing engine powering Oracle Big Data Spatial and Graph.
The distributed open source graph engine Trinity, presented in 2013 by Microsoft, is now known as Microsoft Graph Engine. GraphX, introduced in 2014, is the embedded graph processing framework built on top of Apache Spark for parallel computed. Some other systems have since been introduced, for example, Signal/Collect.
Graph analytics libraries and toolkits
In the graph analytics landscape, there are also single-user systems dedicated to graph analytics. Graph analytics libraries and toolkit provide implementations of numbers of algorithms from graph theory.

Some libraries and toolkits offering graph analytics capabilities
There are standalone libraries such as NetworkX and NetworKit, python libraries for large-scale graph analysis, or iGraph, a graph library written in C and available as Python and R packages, and library provided by graph database vendors such as Neo4j with its Graph Algorithms Library.
Other technology vendors offer graph analytics libraries for high performance graph analytics. It is the case of the GPU technology provider NVIDIA with its NVGraph library. The geographic information software QGIS also built its own library for network analysis.
Some of these libraries also propose graph visualization tools to help users build graph data exploration interfaces, but this is a topic for the third post of this series.
Graph query languages
Finally, one important piece of analytics frameworks that was not mentioned yet: graph query languages.
As for any storage system, query languages are an essential element for graph databases. These languages make it possible to model the data as a graph, and their logic is very close to the graph data model. In addition to the data modeling process, graph query languages are used to query data. Depending on their nature they can be used against databases systems and as domain-specific analytics language. Most of the high-level computing engines allow users to write using these query languages.
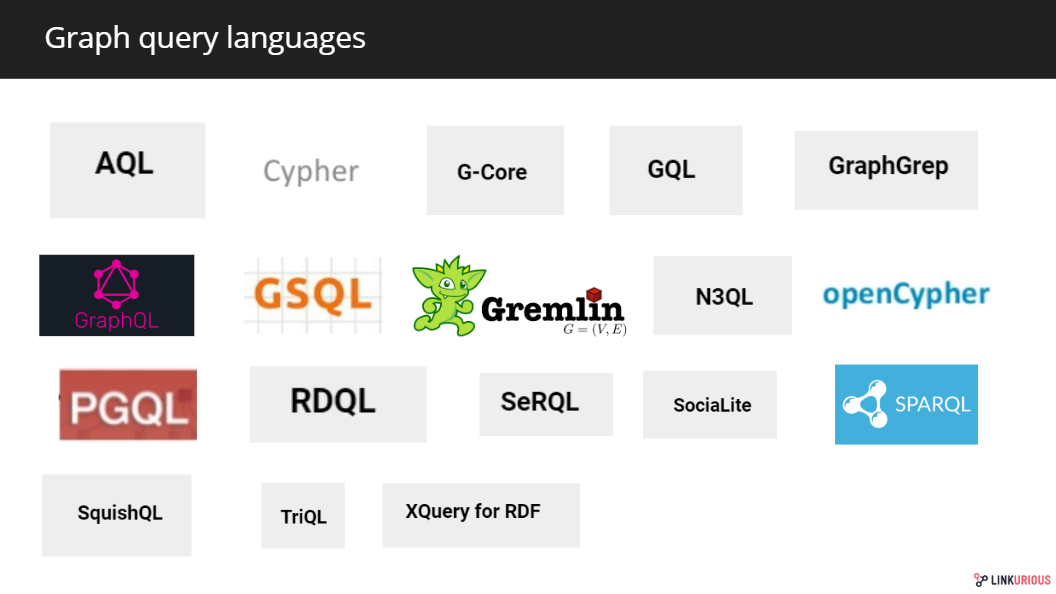
Some of the existing graph query languages and similar projects
Cypher was created in 2011 by Neo4j to use on their own database. It has been open-sourced in 2015 as a separate project named OpenCypher. Other notable graph query languages are: Gremlin the graph traversal language of Apache TinkerPop query language created in 2009 or SPARQL, the SQL-like language created by the W3C to query RDF graphs in 2008. More recently, TigerGraph developed its own graph query language name GSQL and Oracle created PGQL, both SQL-like graph query languages. G-Core was proposed by the Linked Data Benchmark Council (LDBC) in 2018 as a language bridging the academic and industrial worlds. Other vendors such as OrientDB went for the relational query language SQL.
Last year, Neo4j launched an initiative to unify Cypher, PGQL and G-Core under a single standard graph query language: GQL (Graph Query Language). The initiative will be discussed during a W3C workshop in March 2019. Some other query languages are especially dedicated to graph analysis such as SociaLite.
While not originally a graph query language, Facebook’s GraphQL is worth mentioning. This API language has been extended by graph database vendors to use as a graph query language. Dgraph uses it nativelyas its query language, Prisma is planning to extend it to various graph databases and Neo4j has been pushing it into GRANDstack and its query execution layer neo4j-graphql.js.
I listed and presented a vast majority of graph analytics actors in the following presentation.
In the next post, I’ll look at the actors of the third and last layer of the GraphTech landscape: the graph visualization tools.


