Ready to learn Data Science? Browse Data Science Training and Certification courses developed by industry thought leaders and Experfy in Harvard Innovation Lab.
Many people ask me, what is data science? If you ask this question to different data scientists, you’ll probably get a range of different answers. Not only is the field so interdisciplinary, but the job market is also demanding different sets of skills from the data scientist in different job roles. Depending on the nature of their work, you could find a data scientist whose most time is spent on researching and coming up with new theories for the existing tasks, or even those who would come up with a completely new theory (Convolutional/Recurrent Neural Nets, I’m sure someone out there is probably working towards coming up with X Neural Net that might someday blow away these existing models). On the other hand, you could find data scientists who work with CSV files daily, do data cleaning and visualization, and make insightful reports that could help drive high-stake decisions. In other sciences such as biology, physics, and chemistry, the definitions are rather clear as to what people are doing in the field. So what exactly is data science?
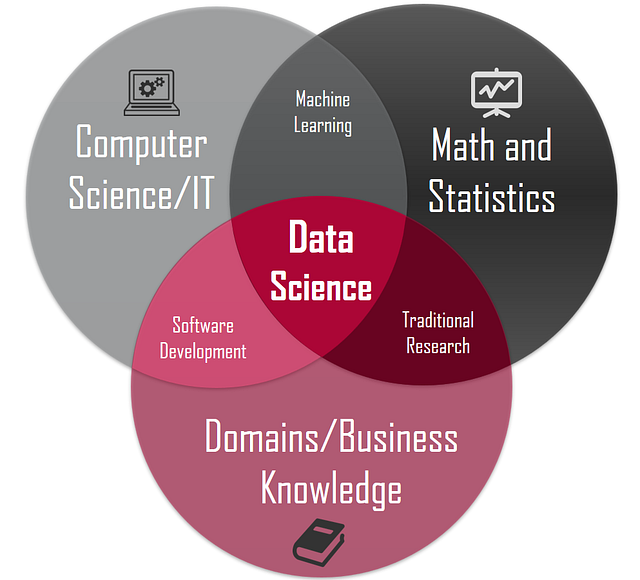
Data is to Data Science, as Elements are for Chemistry. When you’re dealing with chemistry, you identify the most basic building blocks, its properties, and build more complex models out of it, to understand and predict what would happen in a different scenario. If the model is correct and generalizable, then the model is valid. Otherwise, they construct new models. The same is for Data Science. The most basic thing you can have in Data Science is a data point. From data, data scientists can build a model to explain what is going on in the scenario we’re facing, validate it, and test it. But to do all this, we need a little bit of Computer Science, Math and Statistics, and Domains/Business Expertise.
Computer Science

Most algorithms concerning pattern recognition don’t simply have closed-form solutions. If you think about Linear Regression, you can simply use the nice geometric property of linearity to derive the Normal Equations, which allow you to get a formula to get the solution straight from all your inputs. Now that’s neat. But when you do advanced machine learning algorithms like the Kernelized SVM, Decision Trees, and Neural Networks, your best bet is to use numerical optimization (i.e. gradient descent algorithm) to find an optimum.
Large-scale machine learning requires a strong programming experience such as data parallelism, distributed computing, and memory management. For example, when you look at a toy example of training an image classifier on MNIST data, you can fit the whole dataset into memory. Let’s say you have 1 TB of image data. Simply assigning all the images as X in your python code would crash your program. Another example would be data vectorization. A naive method to training a neural network would be to write a nested bunch of for loops to update single elements in the weight matrix. In the Platonic world of mathematics, that would in theory be sufficient to obtaining a strong machine learning classifier, but in practice, that could take months or years to complete…(not to mention the bugs you’ll be discovering 2 months from now)!!! At my company (Datawow — a micro-task platform where human moderators label high volumes of data to train ML models for tasks automation), we train image classifiers with terabytes of data, and data parallelism on multiple GPUs is highly essential. These are just a few examples to start with, and you never know what problems you will face as a Data Scientist. So, a strong programming skill/experience would help a lot in Data Science.
Mathematics and Statistics
Machine Learning Cheat-Sheet
Machine Learning itself is a concept where agents learn from its environment/data to better perform at a given task. How does the algorithm learn? It’s pretty much statistical. Some machine learning algorithms (e.g. Linear/Quadratic Discriminant Analysis) are basically Bayesian Models, where we assume some parametric distributional structure of the data, and update the parameters algorithmically. Other classifiers such as Neural Networks maps real-valued vectors into a probability space (a number between 0 and 1) by a series of additions, multiplications, and output activations. The update to the weights are computed via gradient descent, where the calculations require the chain rule to model the flow of information from the output to the inner parts of the network. After all, we’re modelling numbers. So the better your math and stats foundation, the better your life will be.
Domains/Business Knowledge

People may imagine AI the way we see it in the movies: independent robots being able to set their own objectives, self-repair, and eventually take over the world. That may one day be true, but just not now (as the time of the writing). We are living in the age of vertical Artificial Intelligence. Robots that we build are trained for one specific task, and it’s only good at that task. For example, if you trained an image classifier to tell whether one image is a dog or a cat, and use that trained classifier to predict a picture of a car, it will output one of either dog or cat with very high probability (assuming you used softmax for your final layer activation). The model would find some features in the image of the car, whether it be edges, colors, blurriness, etc. and relate those to the images it’s seen in the trained images of dogs vs. cats.
What does this imply? Robots are vertically smart, but horizontally stupid! For a different task in the same domain (e.g. image classification), one can take advantage of transfer learning, which I discuss in detail here. That means that we still need domain expertise for whatever AI we’re building. For instance, if you’re in the medical field, then the machine learning model that you’re building would have to answer to the medical images (they’re much different from ImageNet images). If you’re training a text classifier for wikipedia, then word2vec may be a good starting point. But if you’re working with tweets, where people make spelling mistakes all the time, then you probably should consider character-level modelling.
Computer Science + Math&Stats + Domain Expertise

When you combine the three elements described above, you have an individual who’s very comfortable identifying what’s the problem, what’s at stake, what data should be used, what models are suitable, how to train it, and finally how to put it on production. With these skills, it is unquestionable whether you are ready to turn data into value.


