The Undercurrent of Ongoing Research
2021 is here, and deep learning is as active as ever; research in the field is speeding up exponentially. There are obviously many more deep learning advancements that are fascinating and exciting. To me, though, the five presented demonstrate a central undercurrent in ongoing deep learning research: how necessary is the largeness of deep learning models?
1. GrowNet
tl;dr: GrowNet applies gradient boosting to shallow neural networks. It has been rising in popularity, yielding superior results in classification, regression, and ranking. It may indicate research supporting larger ensembles and shallower networks on non-specialized data (non-image or sequence).
Gradient boosting has proven to become very popular in recent years, rivalling that of a neural network. The idea is to have an ensemble of weak (simple) learners, where each corrects the mistake of the previous. For instance, an ideal 3-model gradient boosting ensemble may look like this, where the real label of the example is 1.
- Model 1 predicts
0.734. Current prediction is0.734. - Model 2 predicts
0.464. Current prediction is0.734+0.464=1.198. - Model 3 predicts
-0.199. Current prediction is1.198-0.199=0.999.
Each model is trained on the residual of the previous. Although each model may be individually weak, as a whole the ensemble can develop incredible complexity. Gradient boosting frameworks like XGBoost use gradient boosting on decision trees, which are one of the simplest machine learning algorithms.
There has been some discussion on neural networks not being weak enough for gradient boosting; because gradient boosting has so much capability for overfitting, it is crucial that each learner in the ensemble be weak.
However, recent work has shown that extremely deep neural networks can be decomposed into a collection of many smaller subnetworks. Therefore, massive neural networks may just be sophisticated ensembles of small neural networks. This challenges the idea that neural networks are too strong to be weak learners in gradient boosting.
The GrowNet ensemble consists of k models. Each model is fed the original features and the predictions of the previous model. The predictions of all the models are summed to produce a final output. Every model can be as simple as having only one hidden layer.
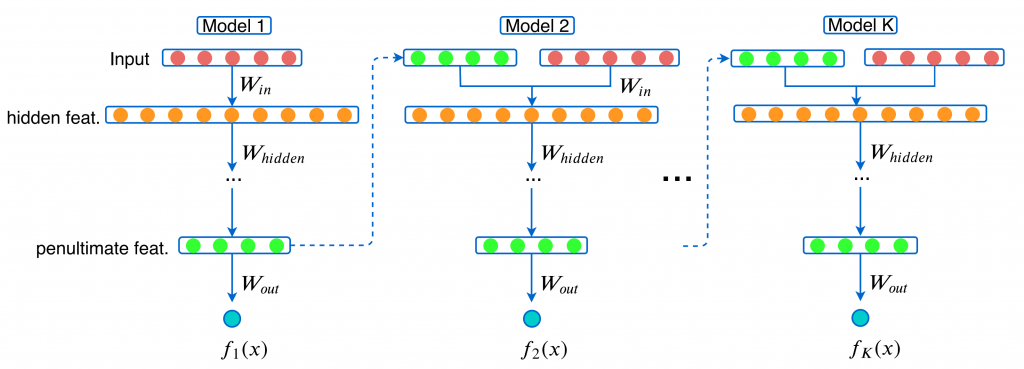
GrowNet is easy to tune and requires less computational cost and time to train, yet it outperforms deep neural networks in regression, classification, and ranking on multiple datasets. Data scientists have picked up on these benefits and it is growing in popularity.
2. TabNet
tl;dr: TabNet is a deep leaning model for tabular data, designed with the ability to represent hierarchical relationships and draws inspiration from decision tree models. It has yielded superior results on many real-world tabular datasets.
Neural networks are famously bad at modelling tabular data, and the accepted explanation is because their structure — very prone to overfitting — instead succeeds in recognizing the complex relationships of specialized data, like images or text.
Decision-tree models like XGBoost or Adaboost have instead been popular with real-world tabular data, because they split the feature space in simple perpendicular planes. This level of separation is usually fine for most real-world datasets; even though these models, regardless how complex, make assumptions about decision boundaries, overfitting is a worse problem.
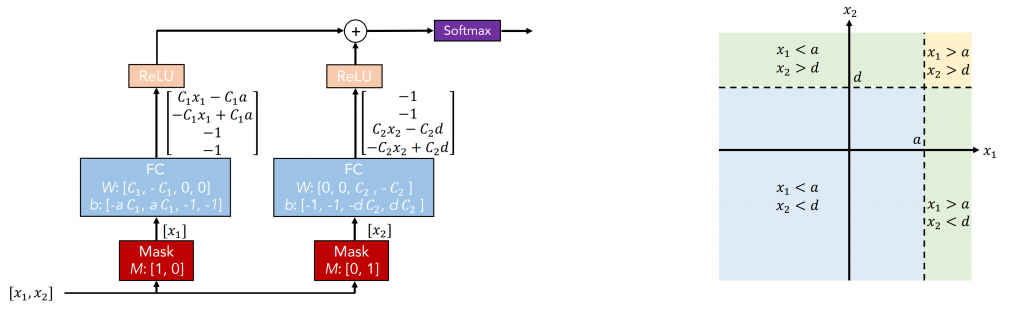
Yet for many real-world datasets, decision-tree models are not enough and neural networks are too much. TabNet was created by two Google researchers to address this problem. The model relies on a fundamental neural network design, which makes decisions like a more complex decision tree.
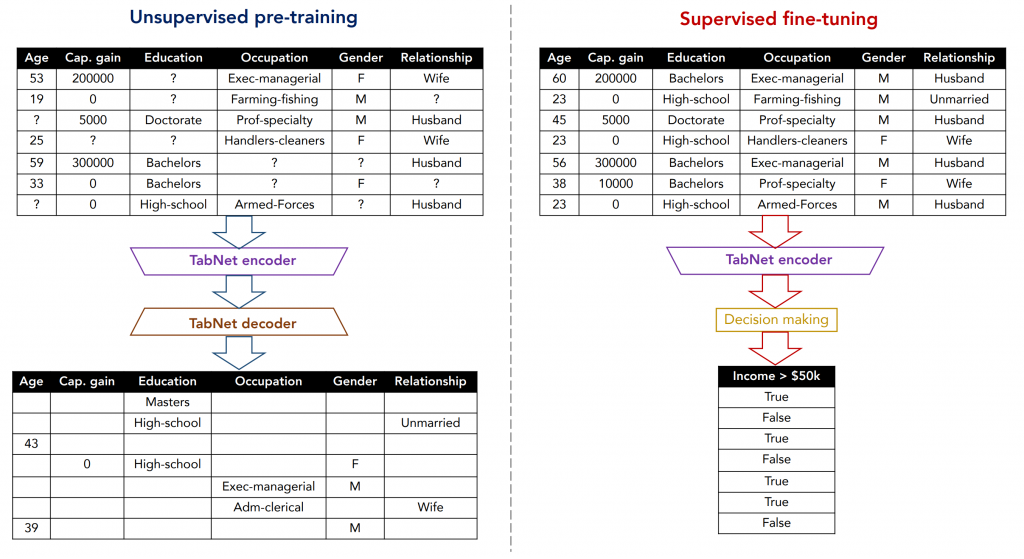
Furthermore, TabNet is trained in two stages. In the unsupervised pre-training stage, the model is trained to predict masked values in the data. Decision-making layers are then appended to the pretrained encoder and supervised fine-tuning takes place. This is one of first instance of incredibly successful unsupervised pre-training on tabular data.
Critically, the model uses attention, so it can choose which features it will make a decision from. This allows it to develop a strong representation of hierarchical structures often present in real-world data.
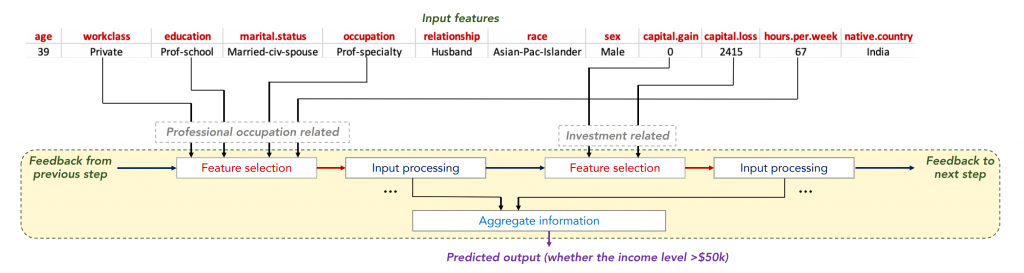
These mechanisms mean input data for TabNet need no processing whatsoever. TabNet is very quickly rising among data scientists; almost all of top-scoring competitors in the Mechanisms of Action Kaggle competition, for instance, incorporated TabNet into their solutions. Because of its popularity, it has been implemented in a very simple and usable API.
This represents a broadening of deep learning past extremely specialized data types, and reveals just how universal neural networks can be. [link]
Paper, Simple Pytorch API Implementation, Simple TensorFlow API Implementation
3. EfficientNet
tl;dr: Model scaling to improve deep CNNs can be unorganized. Compound scaling is a simple and effective method that uniformly scales the width, depth, and resolution of the network. EfficientNet is a simple network with compound scaling applied to it, and yields state of the art results. The model is incredibly popular in the image recognition work.
Deep convolutional neural networks have been growing larger in an attempt to make them more powerful. Exactly how they become bigger, though, is actually quite arbitrary. Sometimes, the resolution of the image is increased (more pixels). Other times, it may be the depth (# of layers) or the width (# of neurons in each layer) that are increased.
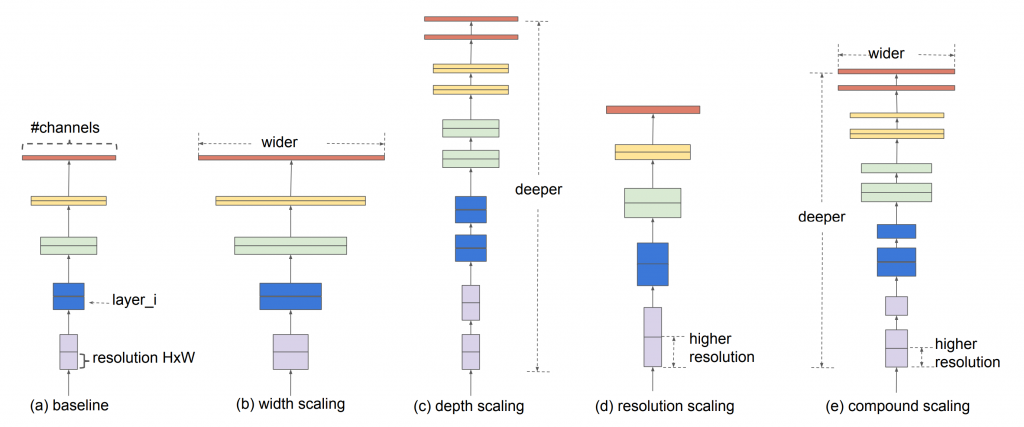
Compound scaling is a simple idea: instead of scaling them arbitrarily, scale the resolution, depth, and width of the network equally.
If one wants to use 2³ times more computational resources, for example;
- increase the network depth by α³ times
- increase the network width by β³ times
- increase the image size by γ³ times
The values of α, β, and γ can be found through a simple grid search. Compound scaling can be applied to any network, and compound-scaled versions of models like ResNet have consistently performed better than arbitrary scaled ones.
The authors of the paper developed a baseline model, EfficientNetB0, which consists of very standard convolutions. Then, using compound scaling, seven scaled models — EfficientNetB1 to EfficientNetB7 — were created.
The results are amazing — EfficientNets were able to perform better than models that required 4 to 7 times more parameters and 6 to 19 times more computational resources. It seems that compound scaling is one of the most efficient ways to utilize neural network space.
EfficientNet has been one of the most important recent contributions. It indicates a turn in research towards more powerful but also efficient and practical neural networks.
Paper, Simple Pytorch API Implementation, Simple TensorFlow Implementation
4. The Lottery Ticket Hypothesis
tl;dr: Neural networks are essentially giant lotteries; through random initialization, certain subnetworks are mathematically lucky and are recognized for their potential by the optimizer. These subnetworks (‘winning tickets’) emerge as doing most of the heavy lifting, while the rest of the network doesn’t do much. This hypothesis is groundbreaking in understanding how neural networks work.
Why don’t neural networks overfit? How do they generalize with so many parameters? Why do big neural networks work better than smaller ones when it is common statistics principle that more parameters = overfitting?
“Bah! Go away and shut up!” grumbles the deep learning community. “We don’t care about how neural networks work as long as they work.” Too long have these big questions been under-investigated.
One common answer is regularization. However, this doesn’t seem to be the case — in a study conducted by Zhang et al., an Inception architecture without various regularization methods didn’t perform much worse than one with. Thus, one cannot argue that regularization is the basis for generalization.
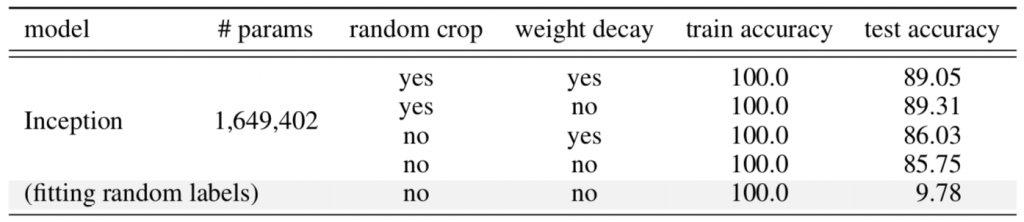
Neural network pruning offers a glimpse into one convincing answer.
With neural network pruning, over 90 percent — in some cases 95 or even 99 percent — of neural network weights and neurons can be eliminated with little to no loss on performance. How can this be?
Imagine you want to order a pen on Amazon. When the delivery package arrives, you find it is in a large cardboard box with lots of stuffing inside it. You finally find the pen after several minutes of searching.
After you find the pen, the stuffing doesn’t matter. But before you find it, the stuffing is part of the delivery. The cardboard box with the stuffing is the neural network, and the pen is the subnetwork doing all the real work. After you locate that subnetwork, you can ditch the rest of the neural network. However, there needs to be a network in the first place to find the subnetwork.
Lottery Ticket Hypothesis: In every sufficiently deep neural network, there is a smaller subnetwork that can perform just as well as the whole neural network.
Weights in the neural network begin randomly initialized. At this point, there are plenty of random subnetworks in the network, but some have more mathematical potential. That is, the optimizer thinks it is mathematically better to update this set of weights to lower the loss. Eventually, the optimizer has developed a subnetwork to do all the work; the other parts of the network do not serve much of a purpose.
Each subnetwork is a ‘lottery ticket’, with a random initialization. Favorable initializations are ‘winning tickets’ identified by the optimizer. The more random tickets you have, the higher probability one of them will be a winning ticket. This is why larger networks generally perform better.
This hypothesis is particularly important to proposing an explanation for the Deep Double Descent, in which after a certain threshold, more parameters yields a better generalization rather than less.
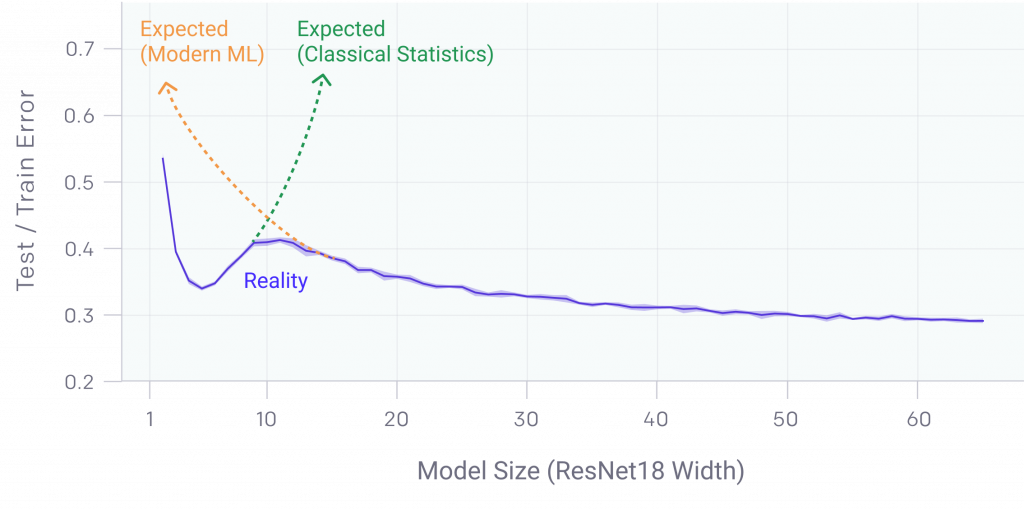
The Lottery Ticket Hypothesis is one giant step forward towards understanding truly how deep neural networks work. Although it’s still a hypothesis, there is convincing evidence for it, and such a discovery would transform how we approach innovation in deep learning.
5. The Top-Performing Model With Zero Training
tl;dr: Researchers developed a method to prune a completely randomly initialized network to achieve top performance with trained models.
In close relationship with the Lottery Ticket Hypothesis, this study explores just how much information can lie in a neural network. It’s common for data scientists to see “60 million parameters” and underestimate how much power 60 million parameters can really store.
In support of the Lottery Ticket Hypothesis, the authors of the paper developed the edge-popup algorithm, which assesses how ‘helpful’ an edge, or a connection, would be towards prediction. Only the k% more ‘helpful’ edges are retained; the remaining ones are pruned (removed).
Using the edge-popup algorithm on a sufficiently large random neural network yields results very close to, and sometimes better than, performance of the trained neural network with all of its weights intact.
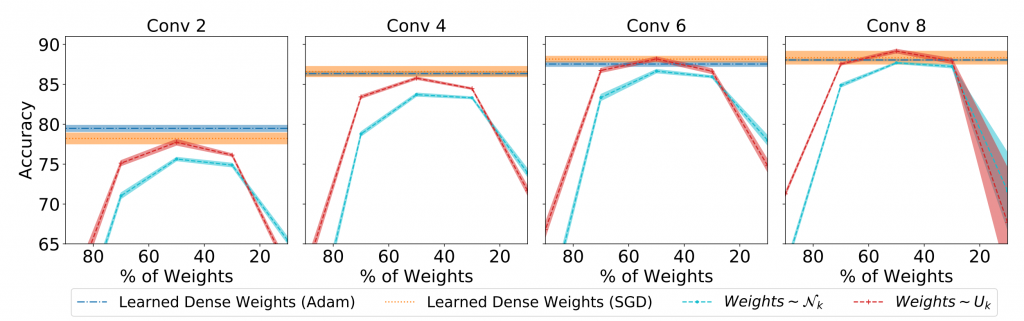
That’s amazing — within a completely untrained, randomly initialized neural network lies already a top-performing subnetwork. This is like being told that your name can be found in a pretty short sequence of random letters.
uqhoquiwhrpugtdfdsnaoidpufehiobnfjdopafwuhibdsofpabievniawo;jkjndjkn
ajsodijaiufhuiduisafidjohndoeojahsiudhuidbviubdiaiupdphquiwhpeuhqiuhdpueohdpqiuwhdpiashiudhjashdiuhasiuhdibcisviywqrpiuhopfdbscjasnkuipi
This study is more of a question than an answer. It points us in an area of new research: getting to the bottom of exactly how neural networks work. If these findings are universal, surely there must be a better training method that can take advantage of this fundamental axiom of deep learning waiting to be discovered.
Summary & Conclusion
- GrowNet. This application of ensemble methods to deep learning is one demonstration of harnessing simple subnetwork structures into a complex, sophisticated, and successful model.
- TabNet. Neural network structures are exceptionally versatile, and TabNet marks the true expansion of neural networks to all sorts of data types. It is a perfect balance between underfitting and overfitting.
- EfficientNet. Part of a growing trend of packing more predictive power into less space, EfficientNet is incredibly simplistic yet effective. It demonstrates that there is indeed a structure towards scaling models. This is something incredibly important to pay attention to going forward as models continually become larger and larger.
- The Lottery Ticket Hypothesis. A fascinating perspective towards how neural networks generalize, the Lottery Ticket Hypothesis is a golden key that will help us unlock greater deep learning achievements. Identifying the power of large networks coming not from the largeness itself but an increased number of ‘lottery tickets’ is groundbreaking.
- The Top-Performing Model with Zero Training. A vivid demonstration of just how much we underestimate the predictive power within a randomly initialized neural network.
There is no doubt 2021 will bring many more fascinating advancements in deep learning.



