This is Part 3 of this series. Here is Part 1: How to Become a (Good) Data Scientist – Beginner Guide and Part 2: A Layman’s Guide to Data Science. How to Build a Data Project .
By now, you have already gained enough knowledge and skills about Data Science and have built your first (or even your second and third) project. At this point, it is time to improve your workflow to facilitate further development process.
There is no specific template for solving any data science problem (otherwise you’d see it in the first textbook you come across). Each new dataset and each new problem will lead to a different roadmap. However, there are similar high-level steps in many different projects.
In this post, we offer a clean workflow that can be used as a basis for data science projects. Every stage and step in it, of course, can be addressed on its own and can even be implemented by different specialists in larger-scale projects.
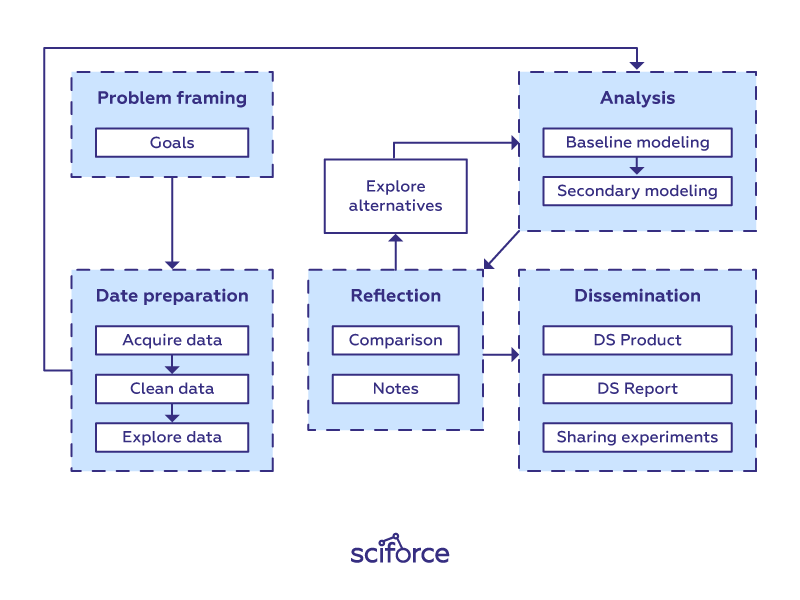
Framing the problem and the goals
As you already know, at the starting point, you’re asking questions and trying to get a handle on what data you need. Therefore, think of the problem you are trying to solve. What do you want to learn more about? For now, forget about modeling, evaluation metrics, and data science-related things. Clearly stating your problem and defining goals are the first step to providing a good solution. Without it, you could lose the track in the data-science forest.
Data Preparation Phase
In any Data Science project, getting the right kind of data is critical. Before any analysis can be done, you must acquire the relevant data, reformat it into a form that is amenable to computation and clean it.

The first step in any data science workflow is to acquire the data to analyze. Data can come from a variety of sources:
- imported from CSV files from your local machine;
- queried from SQL servers;
- stripped from online repositories such as public websites;
- streamed on-demand from online sources via an API;
- automatically generated by physical apparatus, such as scientific lab equipment attached to computers;
- generated by computer software, such as logs from a webserver.
In many cases, collecting data can become messy, especially if the data isn’t something people have been collecting in an organized fashion. You’ll have to work with different sources and apply a variety of tools and methods to collect a dataset.
There are several key points to remember while collecting data:
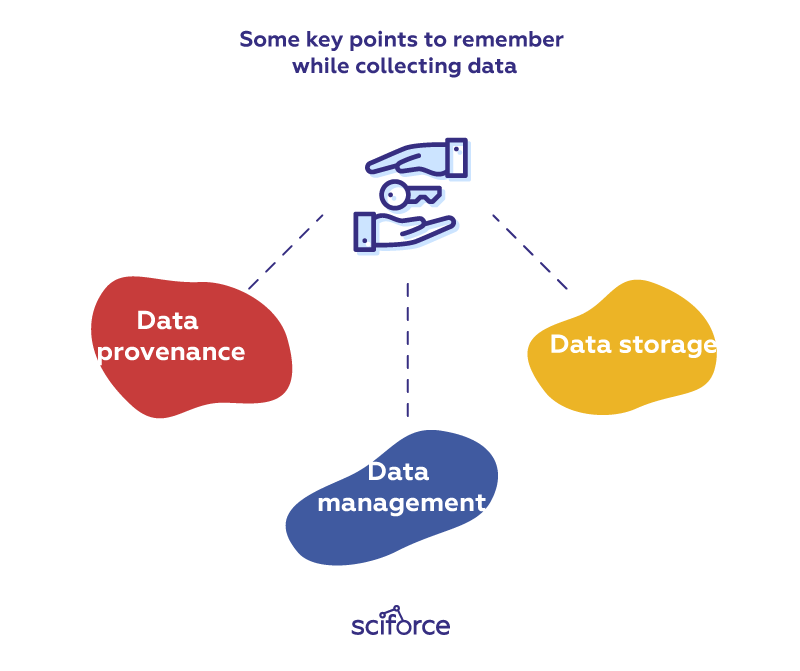
Data provenance: It is important to accurately track provenance, i.e. where each piece of data comes from and whether it is still up-to-date, since data often needs to be re-acquired later to run new experiments. Re-acquisition can be helpful if the original data sources get updated or if researchers want to test alternate hypotheses. Besides, we can use provenance to trace back downstream analysis errors to the original data sources.
Data management: To avoid data duplication and confusion between different versions, it is critical to assign proper names to data files that they create or download and then organize those files into directories. When new versions of those files are created, corresponding names should be assigned to all versions to be able to keep track of their differences. For instance, scientific lab equipment can generate hundreds or thousands of data files that scientists must name and organize before running computational analyses on them.
Data storage: With modern almost limitless access to data, it often happens that there is so much data that it cannot fit on a hard drive, so it must be stored on remote servers. While cloud services are gaining popularity, a significant amount of data analysis is still done on desktop machines with data sets that fit on modern hard drives (i.e., less than a terabyte).

Raw data is usually not in a convenient format to run an analysis, since it was formatted by somebody else without that analysis in mind. Moreover, raw data often contains semantic errors, missing entries, or inconsistent formatting, so it needs to be “cleaned” prior to analysis.
Data wrangling (munging) is the process of cleaning data, putting everything together into one workspace, and making sure your data has no faults in it. It is possible to reformat and clean the data either manually or by writing scripts. Getting all of the values in the correct format can involve stripping characters from strings, converting integers to floats, or many other things. Afterwards, it is necessary to deal with missing values and null values that are common in sparse matrices. The process of handling them is called missing data imputation where the missing data are replaced with substituted data.
Data integration is a related challenge, since data from all sources needs to be integrated into a central MySQL relational database, which serves as the master data source for his analyses.
Usually it consumes a lot of time and cannot be fully automated, but at the same time, it can provide insights into the data structure and quality as well as the models and analyses that might be optimal to apply.

Here’s where you’ll start getting summary-level insights of what you’re looking at, and extracting the large trends. At this step, there are three dimensions to explore: whether the data imply supervised learning or unsupervised learning? Is this a classification problem or is it a regression problem? Is this a prediction problem or an inference problem? These three sets of questions can offer a lot of guidance when solving your data science problem.
There are many tools that help you understand your data quickly. You can start with checking out the first few rows of the data frame to get the initial impression of the data organization. Automatic tools incorporated in multiple libraries, such as Pandas’ .describe(), can quickly give you the mean, count, standard deviation and you might already see things worth diving deeper into. With this information you’ll be able to determine which variable is our target and which features we think are important.
Analysis Phase
Analysis is the core phase of data science that includes writing, executing, and refining computer programs to analyze and obtain insights from the data prepared at the previous phase. Though there are many programming languages for data science projects ranging from interpreted “scripting” languages such as Python, Perl, R, and MATLAB to compiled ones such as Java, C, C++, or even Fortran, the workflow for writing analysis software is similar across the languages.
As you can see, analysis is a repeated iteration cycle of editing scripts or programs, executing to produce output files, inspecting the output files to gain insights and discover mistakes, debugging, and re-editing.

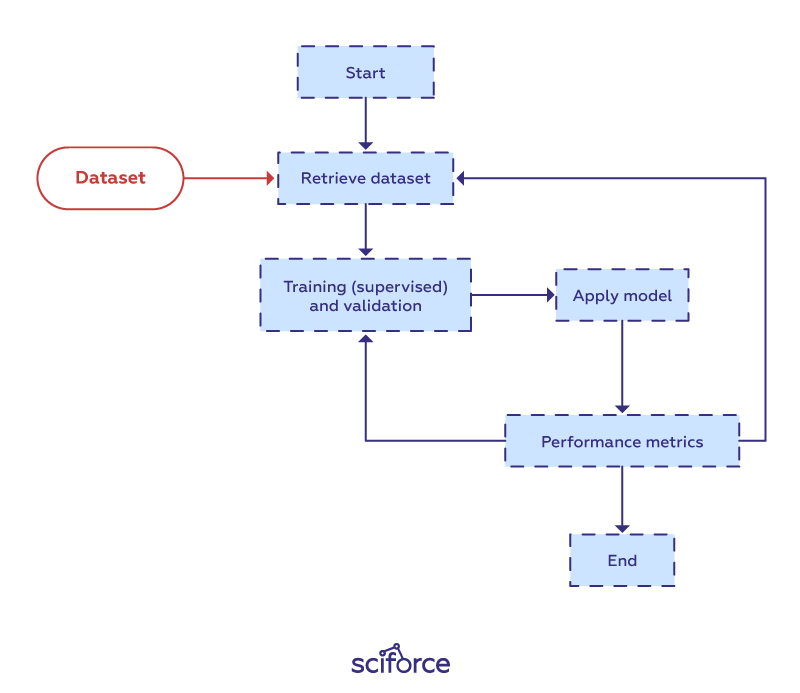
As a data scientist, you will build a lot of models with a variety of algorithms to perform different tasks. At the first approach to the task, it is worthwhile to avoid advanced complicated models, but to stick to simpler and more traditional linear regression for regression problems and logistic regression for classification problems as a baseline upon which you can improve.
At the model preprocessing stage you can separate out features from dependent variables, scale the data, and use a train-test-split or cross validation to prevent overfitting of the model — the problem when a model too closely tracks the training data and doesn’t perform well with new data.
With the model ready, it can be fitted on the training data and tested by having it predict y values for the X_test data. Finally, the model is evaluated with the help of metrics that are appropriate for the task, such as R-squared for regression problems and accuracy or ROC-AUC scores for classification tasks.

Now it is time to go into a deeper analysis and, if necessary, use more advanced models, such as, for example neural networks, XGBoost, or Random Forests. It is important to remember that such models can initially render worse results than simple and easy-to-understand models due to a small dataset that cannot provide enough data or to the collinearity problem with features providing similar information.
Therefore, the key task of the secondary modeling step is parameter tuning. Each algorithm has a set of parameters you can optimize. Parameters are the variables that a machine learning technique uses to adjust to the data. Hyperparameters that arethe variables that govern the training process itself, such as the number of nodes or hidden layers in a neural network, are tuned by running the whole training job, looking at the aggregate accuracy, and adjusting.
Reflection Phase
Data scientists frequently alternate between the analysis and reflection phases: whereas the analysis phase focuses on programming, the reflection phase involves thinking and communicating about the outputs of analyses. After inspecting a set of output files, a data scientist, or a group of data scientists can make comparisons between output variants and explore alternative paths by adjusting script code and/or execution parameters. Much of the data analysis process is trial-and-error: a scientist runs tests, graphs the output, reruns them, graphs the output and so on. Therefore, graphs are the central comparison tool that can be displayed side-by-side on monitors to visually compare and contrast their characteristics. A supplementary tool is taking notes, both physical and digital to keep track of the line of thought and experiments.
Communication Phase
The final phase of data science is disseminating results either in the form of a data science product or as written reports such as internal memos, slideshow presentations, business/policy white papers, or academic research publications.
A data science product implies getting your model into production. In most companies, data scientists will be working with the software engineering team to write the production code. The software can be used both to reproduce the experiments or play with the prototype systems and as an independent solution to tackle a known issue on the market, like, for example, assessing the risk of financial fraud.
Alternatively to the data product, you can create a data science report. You can showcase your results with a presentation and offer a technical overview on the process. Remember to keep your audience in mind: go into more detail if presenting to fellow data scientists or focus on the findings if you address the sales team or executives. If your company allows publishing the results, it is also a good opportunity to have feedback from other specialists. Additionally, you can write a blog post and push your code to GitHub so the data science community can learn from your success. Communicating your results is an important part of the scientific process, so this phase should not be overlooked.



