Language models in NLP(Natural Language Processing) Systems are Machine Learning based models which are trained to learn and understand Natural Languages like how humans do. A simple example of a trained language model will predict the occurrence of the next word in a sentence

Mainframe Modernization entails the process of migrating or improving the IT operations to reduce IT spending efficiently.
- Language Translation
- Text Classification
- Sentiment Extraction
- Reading Comprehension
- Named Entity Recognition
- Question Answer Systems
- News Article Generation, etc
Traditionally there have been 2 major Language models, which are statistical and Neural network based Language models .

Figure 2 Language Model Techniques
Statistical Language models typically predict based on probabilistic distribution of a word given preceding ones using techniques such as N-Gram, Hidden Markov model etc.
Neural Net based models are little more sophisticated than statistical, as they use neural nets to model the language.
The challenges
The challenge with both these traditional models are
Lack of Agility : The time and effort required to collect vast amount of data, pre-process, creating sequence , encoding the sequence , splitting the data for training and validation, deploying the model and inferencing it is so huge
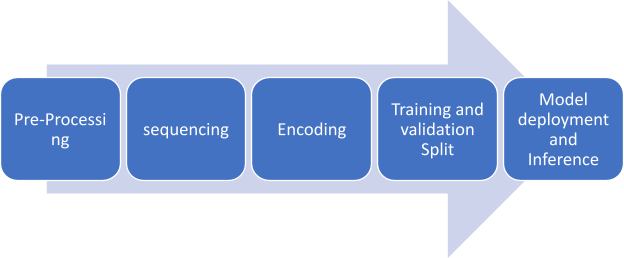
Figure 3 Stages of Language Model training
Domain specific : Models trained against data from one domain cannot predict the data from another domain. Ex. Cloud based Q&A , chatbot applications are trained to answer questions from set of pre-defined document collection. If you rephrase the question it might give you a diff answer. If you train the Language model by feeding it with the Reuters financial news feed , then the prediction of the next word is as follows
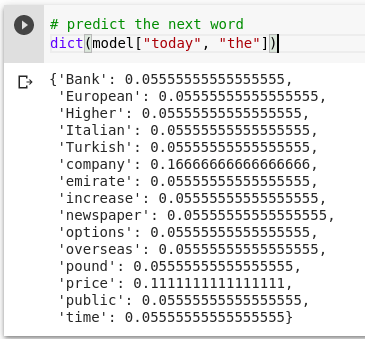
Figure 4 Model trained against finance news feeds data
Transfer Learning is a Machine learning technique by storing knowledge gained while solving one problem and applying it to a different but related problem.
In 2018 the concept of pre-trained transformer models became popular after Google’s BERT (Bidirectional Encoder Representations from Transformers ) paper , which falls into the above mentioned Transfer Learning technique which is basically pre-training the model against vast amount of data and transferring the model’s learning to do relevant tasks.
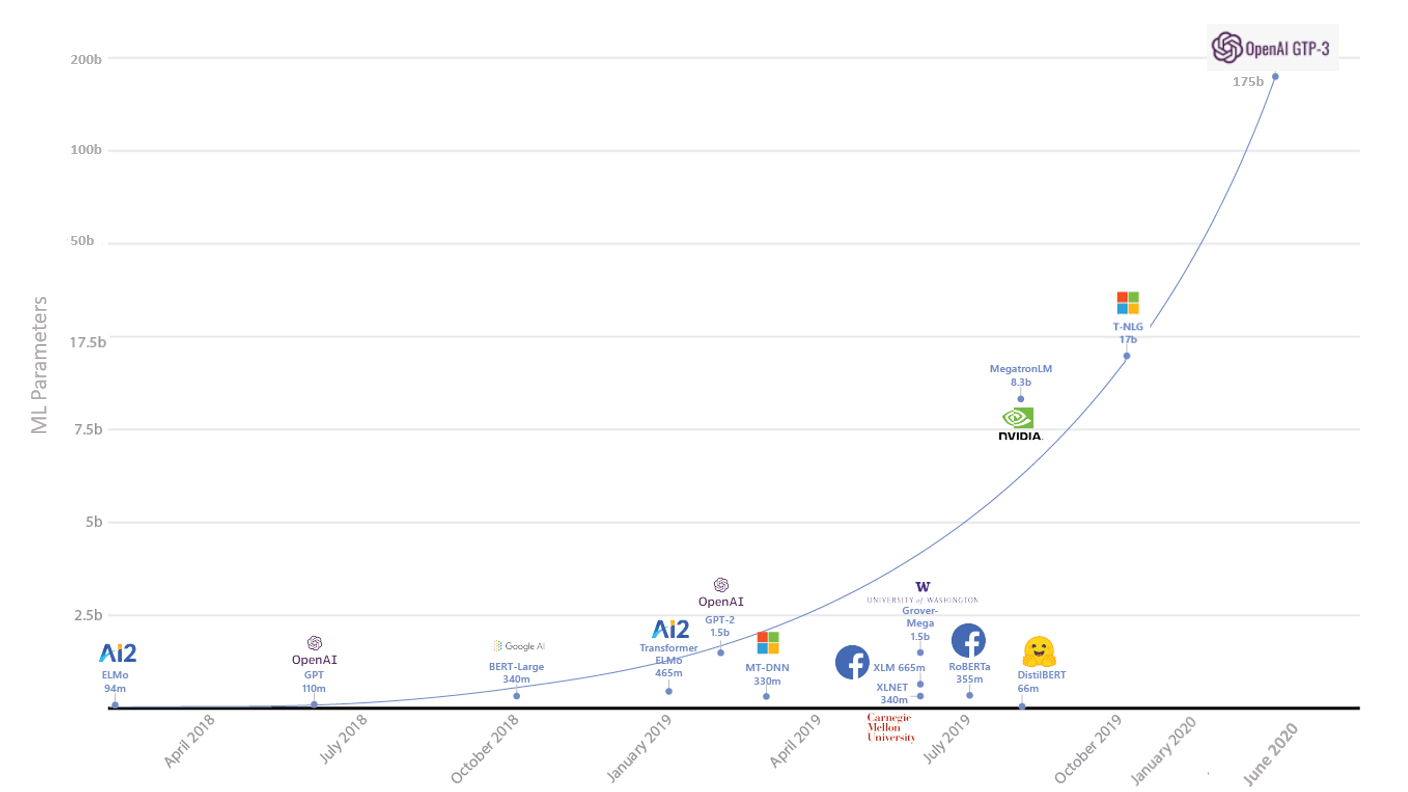
Figure 5 Evolution of Language Models
Google’s BERT model was originally trained with 340 million parameters against Wikipedia and millions of book corpus data to build simple Q&A application, the model accuracy was by far the best at that time. Facebook and microsoft also created BERT based models such as RoBERTa and codeBERT( NL-PL conversion) respectively . Following the trend that larger natural language models lead to better results, Microsoft Project Turing introduced Turing Natural Language Generation (T-NLG), the largest model ever trained using 17 billion parameters as of Jan’2020 . NLP tasks such as Writing news articles, generating code etc. became lot simpler with these transformer models without needing to have much processing headache for NLP engineers.
Around Jun’2020 OpenAI released their Beta version of GPT-3 model, which was trained against 175 billion parameters, which is almost all of the internet is the most sophisticated Language model ever built with such large parameter set. More parameters the model is trained against, better the predictions would be.
OpenAI : GPT-3( Generative Pre-Trained Transformer model 3rd version) released by San Francisco based AI research company called OpenAI , which was founded in 2015 by Sam Altman and Elon Musk , Microsoft invested $1bn in 2019 became an exclusive Cloud provider and the GPT-3 models are trained against the Microsoft’s AI super computer.
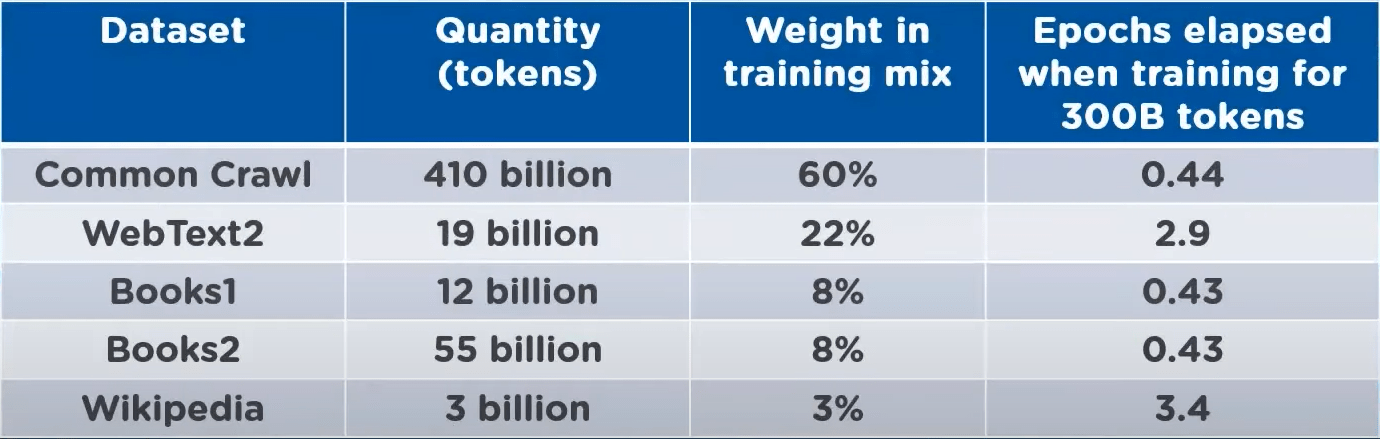
Figure 6 Stats about the data used to train GPT-3
Working with GPT-3
Before start working with GPT-3 API, lets first understand some key concepts.
Prompt: The text input given to the API
Completion: The resultant text that the API generates as a result of processing text input prompt
Token: The number of tokens( chopped sentence into pieces)
Let’s look at how powerful the model is at some NLP tasks
Example 1: SQL Generator prompt is a simple English sentence to get the count of total employees in HR department
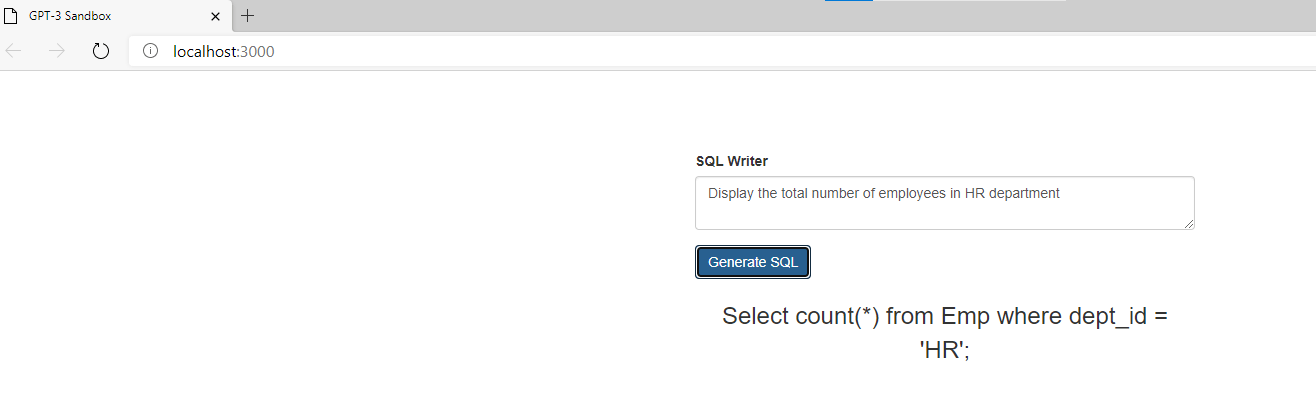
Figure 7 GPT-3 model converting Natural language to SQL
With couple of examples to prime the model, the GPT-3 model is able to produce the SQL statements accurately.
Example 2: Email message generator – I prompted the model to generate email message for a typical hotel booking
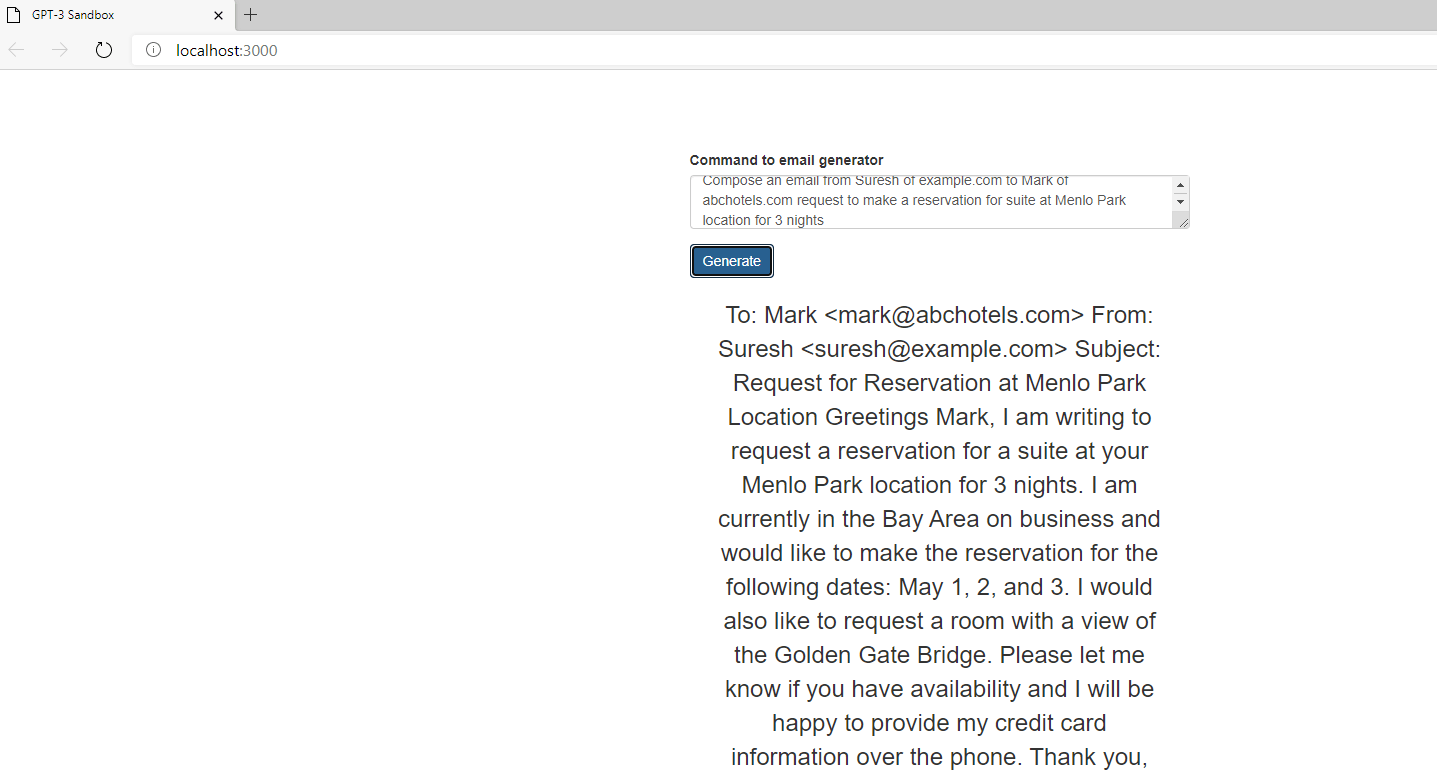
Figure 8 GPT-3 model able to write email message on my behalf 🙂
Sample code for both the above examples can be found here
There are a lot of examples provided by OpenAI in their playground.
Though the model performs to a greater extent, researchers fear it can heavily pose a threat to disinformation, where it can be used by bad actors to create an endless amount of fake news, spread misinformation etc. Here is the tweet by the Sam Altman , the CEO of OpenAI

Based on my years of experience dealing with Financial Services Industries customers, I certainly believe there are some valuable use cases which are best suited for GPT-3 model.
FSI Use Cases
- Automated Named Entity Extraction
- Sales trader- Client Meeting notes summarization
- Financial statement summarization
- Financial sentiment analyzer
- Domain specific speech to text translators, robotic form filling based on user voice inputs
References:
- FinBERT : FinBERT: A Pre-trained Financial Language Representation Model for Financial Text Mining (ijcai.org)
- Cool Projects built on GPT-3 : 15 Interesting Ways OpenAI’s GPT-3 Has Been Put To Use (analyticsindiamag.com)
- OpenAI’s Beta playground : OpenAI API
Disclaimer:
This is completely my personal view on GPT-3 model, The opinions expressed here represent my own and not those of my employer. In addition, my thoughts and opinions change from time to time I consider this a necessary consequence of having an open mind.



