Ready to learn Machine Learning? Browse courses like Machine Learning Foundations: Supervised Learning developed by industry thought leaders and Experfy in Harvard Innovation Lab.
Intuition based series of articles about Neural Networks dedicated to programmers who want to understand basic math behind the code and non-programmers who want to know how to turn math into code.
This is the 1st article of series “Coding Deep Learning for Beginners”.
If you read this article I assume you want to learn about one of the most promising technologies — Deep Learning. Statement AI is a new electricity becomes more and more popular lately. Scientists believe that as SteamEngine, later Electricity and finally Electronics have totally changed the industry later Artificial Intelligence is next to transform it again. In a few years, basics of Machine Learning will become must-have skills for any developer. Even now, we can observe increased popularity of programming languages that are used mainly in Machine Learning like Python and R.
Technology that is capable of magic
In the last years, applications of Deep Learning made huge advancements in many domains arousing astonishment in people that didn’t expect the technology and world to change so fast.
Let’s start from historical match between super-computer AlphaGo and one of the strongest Go players, 18-time world champion — Lee Sedol, in March 2016. The AI ended up victorious with the result of 4 to 1. This match had a huge influence on Go community as AlphaGo invented completely new moves which made people try to understand, reproduce them and created totally new perspective on how to play the game. But that’s not over, in 2017 DeepMind introduced AlphaGo Zero. The newer version of an already unbeatable machine was able to learn everything without any starting data or human help. All that with computational power 4 times less than it’s predecessor!

AlphaGo versus Ke Jie in May 2017 (source: The Independent)
Probably many of you have already heard about self-driving cars project that’s being developed for a few years, by companies like Waymo (Google), Tesla, Toyota, Volvo and more. There are also self-driving trucks that are already used on some highways in the US. Many countries slowly prepare for the introduction of autonomous cars on their roads, yet their peak is predicted for the next decade.
But how about autonomous flying car? Just recently Udacity announced their new Nanodegree programme where developers can learn how to become Flying Car Engineers and create autonomous flying cars!
Lately thanks to improvement in AI speech recognition, voice interfaces like Google Home or Google Assistant become totally new development branch.
Google Advertisement on Google Assistant product. https://youtu.be/-qCanuYrR0g
Future when AI will inform you to leave home earlier because of traffic, buy tickets to cinema, reschedule calendar meetings, control your home and more is closer than you think.
And of course this list could be longer: AI is capable of reproducing human speech with many dialects, AI being better at diagnosing cancer than humans, AI generating new chapter of Harry Potter…
The key point in mentioning in all of that is making you understand that each of those inventions is using Deep Learning technology. To summarise it Deep Learning is currently excelling in tasks like:
- Image recognition
- Autonomous Vehicles
- Games like Go, Chess, Poker, but lately also computer games
- Language Translation (but only a few languages)
- Speech recognition
- Analysis of handwritten texts
And this is only the beginning because technology gets democratized every day and as more people become capable of using it, the more research is being done and simple ideas tested.
So what is Deep Learning?
It’s a subset of Machine Learning algorithms, based on learning data representations, called Neural Networks. Basic idea is that such an algorithm is being shown a partial representation of reality in the form of numerical data. During this process, it’s gaining experience and trying to create it’s own understanding of given data. That understanding has hierarchical structure as algorithm has layers. First layer learns the simplest facts and is connected to the next layer that uses experiences from previous one to learn more complicated facts. Number of layers is called the depth of the model. The more layers, the more complicated data representations the model can learn.
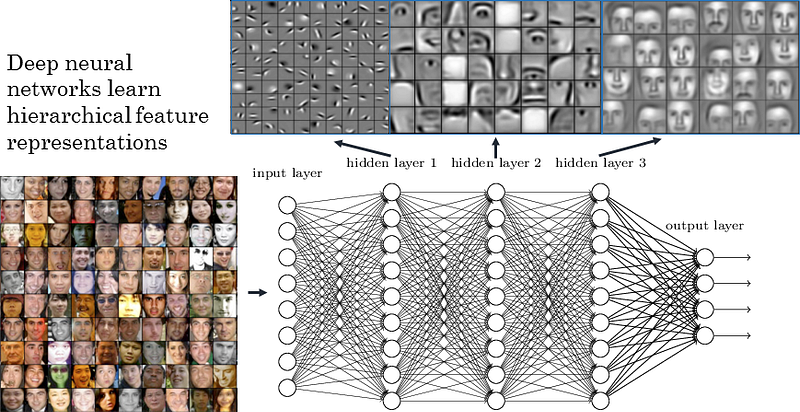
Neural Network that is used for face detection. It learns hierarchy of representations: corners in first layer, eyes and ears in the second layer, and faces in the third layer (source: strong.io)
Is Deep Learning really new technology?
Some of you might think that Deep Learning is technology that was developed lately. That’s not entirely true. Deep Learning had very rich history and had various names depending on philosophical viewpoint. People were dreaming about intelligent machines over a hundred years ago before first mathematical concepts were built. There have been three waves of development.
During the first wave, Deep Learning went by name Cybernetics. First predecessors of modern deep learning were linear models inspired by the study about the nervous system— Neuroscience. The first concept of the neuron (1943), the smallest piece of Neural Network, was proposed by McCulloch-Pitt that tried to implement brain function. A few years later Frank Rosenblatt turned that concept into the first trainable model —Mark 1 Perceptron

Mark 1 Perceptron (source: Wikipedia)
But people had problems to describe brain behaviors with theories available at that time. That’s why interest in them decreased for the next 20 years.
The second wave started in the 80s and went by name Connectionism but also term Neural Networks started to be used more often. The main idea was that neurons could achieve more intelligent behaviors when grouped together in large number. This concept was introduced by Hinton and is called distributed representation (1986). It’s still very central to today’s Deep Learning. Another great accomplishment of a second wave was the invention of back-propagation by Yann LeCun (1987)— core algorithm that is used until today for training Neural Network parameters. Also in year 1982 John Hopfield has invented Recurrent Neural Networks, which after additional introduction of LSTM in 1997, are used today for language translation. Those few years of big hype about Neural Networks has ended due large interest of the various investors which expectations towards implementing AI in products was not fulfilled.
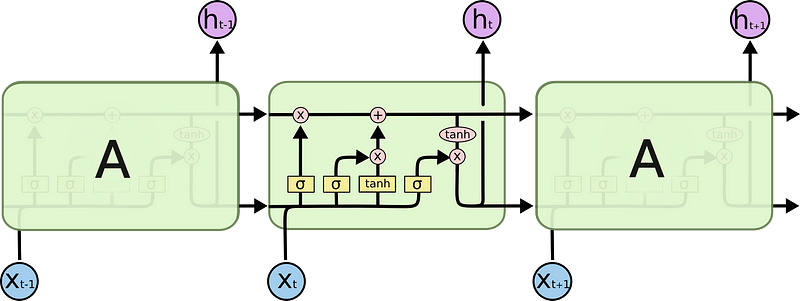
Image of LSTM cell based Recurrent neural Network (source: http://colah.github.io/posts/2015-08-Understanding-LSTMs/)
The third wave started in 2006. At that time computer became a more common thing that everyone could afford. Thanks to the various groups, e.g. gamers, has grown the market for powerful GPUs. Internet was available to everyone. Companies started paying more attention to analytics — gathering data in digital form. As a side effect researchers had more data, and computational power to perform experiments and validate theories. Consequently, there was another huge advancement, thanks to Geoffrey E. Hinton that managed to train Neural Network with many layers. From that moment a lot of different proposals for Neural Network architectures with many layers started to appear. Scientists referred to the number of layers in Neural Network as of “depth” — the more layers it had the deeper it was. Very important occurring was usage of Convolutional Neural Network AlexNet in image classification contest ILSVRC-2012. It has revolutionized a lot of industries by providing them with reliable image detection mechanism — allowing many machines to see e.g. autonomous cars.
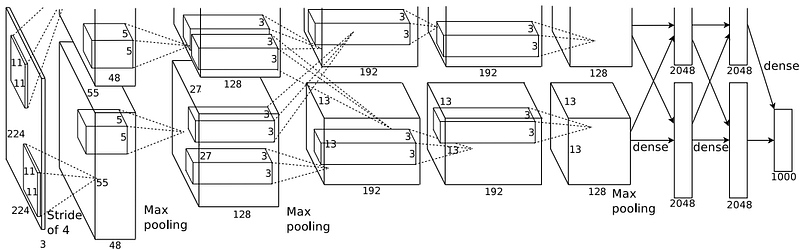
Structure of AlexNet CNN (source: Alex Krizhevsky, Ilya Sutskever, Geoffrey E. Hinton, “ImageNet Classification with Deep Convolutional Neural Networks”, 2012)
In 2014, Ian Goodfellow has introduced new type of Neural Networks called Generative Adversarial Networks. In this architecture two Neural Networks were competing against each other. First network tried to mimic some distribution of data. The role of a second network was to tell if the data it received is fake or real. The goal of first network is to trick the second network. Competition lead to increase in performance of first network and made generation of any kind of data — images, music, text, speech possible.

GAN used to transfer style of one image into another (source: https://github.com/lengstrom/fast-style-transfer)
And this is it I guess. Third wave continues until today and it depends on us how far it can go!
Why am I creating this series of articles?
I am really passionate about Machine Learning and especially Deep Learning. My dream is to become Machine Learning Expert — person who work with people to solve problems and democratize the knowledge. I am working hard every day to reach that goal and this blog is a part of it. So study with me!
In my opinion, the biggest problem with access to this technology is that it was developed at universities and in laboratories by highly qualified Ph. D scientists and still partially stays there. It’s understandable as everything is strongly based on Linear Algebra, Probability and Information Theory, Numerical Computing. But in order to become a driver, you don’t need to know the engine right? There is still conviction that in order to work in this field you need to be Ph. D but it is starting to change in terms of Software Engineering.
Demand for people with those skills will become so big it will simply become impossible for everyone to have Ph. D title. That’s why in order to make people use it, there must be someone who can translate that to others while skipping complicated proofs, scientific notation and adding more intuition.
What I hope to show to you
My goal is to provide strong understanding of most popular topics related to Deep Learning. I don’t want to be protective when it comes to picking content — I want to show you even more complicated stuff and at the same time, do my best to provide you with intuition to grasp it. My main priority is to allow you understand to how those algorithms work and teach you how to code them from scratch. Like Mark Daoust (Developer Programs Engineer for TensorFlow) once said to me:
Everyone should code Neural Network from scratch once… but only once…
So there will be a lot of code that I plan to carefully explain. Among the topics, you can expect mini-projects where I will show you how to use what we’ve learned. It’s really important for knowledge to be followed by practice.
The approach will be bottom-up then:
- low-level — basic (and explained) math turned into Python NumPy code,
- mid-level — TensorFlow (both tf.nn and tf.layer modules) where most of the stuff that I’ve already shown to you can be automated in a single line of code,
- high-level — very popular framework that allows you to create Neural Networks really fast — Keras.
This project will focus only on Multilayer Perceptrons. It’s already a lot of work to be done. If it succeeds I might consider doing an extension for Convolutional Neural Networks, Recurrent Neural Networks, and Generative Adversarial Neural Networks.


