Reviewing challenges, methods and opportunities in deep anomaly detection
This post summarizes a comprehensive survey paper on deep learning for anomaly detection — “Deep Learning for Anomaly Detection: A Review” [1], discussing challenges, methods and opportunities in this direction.
Anomaly detection, a.k.a. outlier detection, has been an active research area for several decades, due to its broad applications in a large number of key domains such as risk management, compliance, security, financial surveillance, health and medical risk, and AI safety. Although it is a problem widely studied in various communities including data mining, machine learning, computer vision and statistics, there are still some unique problem complexities and challenges that require advanced approaches. In recent years, deep learning enabled anomaly detection has emerged as a critical direction towards addressing these challenges. However, there is a lack of systematic review and discussion of the research progress in this direction. We aim to present a comprehensive review of this direction to discuss the main challenges, a large number of state-of-the-art methods, how they address the challenges, as well as future opportunities.
Largely Unsolved Challenges in Anomaly Detection
Although anomaly detection is a lasting active research area for years, there are still a number of largely unsolved challenges due to some unique and complex nature of anomalies, e.g., unknownness (they remain unknown until actually occur), heterogeneity (different anomalies demonstrate completely different abnormal characteristics), rareness (anomalies are rarely occurred data instances), diverse form of anomalies (point anomaly, contextual anomaly, and group anomaly).
One of the most challenging issues is the difficulty to achieve high anomaly detection recall rate (Challenge #1). Since anomalies are highly rare and heterogeneous, it is difficult to identify all of the anomalies. Many normal instances are wrongly reported as anomalies while true yet sophisticated anomalies are missed.
Anomaly detection in high-dimensional and/or not-independent data (Challenge #2) is also a significant challenge. Anomalies often exhibit evident abnormal characteristics in a low-dimensional space yet become hidden and unnoticeable in a high-dimensional space. High-dimensional anomaly detection has been a long-standing problem. Subspace/feature selection-based methods may be a straightforward solution. However, identifying intricate (e.g., high-order, nonlinear and heterogeneous) feature interactions and couplings may be essential in high-dimensional data yet remains a major challenge for anomaly detection.
Due to the difficulty and cost of collecting large-scale labeled anomaly data, it is important to have data-efficient learning of normality/abnormality (Challenge #3). wo major challenges are how to learn expressive normality/abnormality representations with a small amount of labeled anomaly data and how to learn detection models that are generalized to novel anomalies uncovered by the given labeled anomaly data.
Many weakly/semi-supervised anomaly detection methods assume the given labeled training data is clean, which can be highly vulnerable to noisy instances that are mistakenly labeled as an opposite class label. One main challenge here is how to develop noise-resilient anomaly detection (Challenge #4).
Most of existing methods are for point anomalies, which cannot be used for conditional anomaly and group anomaly since they exhibit completely different behaviors from point anomalies. One main challenge here is to incorporate the concept of conditional/group anomalies into anomaly measures/models for the detection of those complex anomalies (Challenge #5).
In many critical domains there may be some major risks if anomaly detection models are directly used as black-box models. For example, the rare data instances reported as anomalies may lead to possible algorithmic bias against the minority groups presented in the data, such as under-represented groups in fraud detection and crime detection systems. An effective approach to mitigate this type of risk is to have anomaly explanation (Challenge #6) algorithms that provide straightforward clues about why a specific data instance is identified as anomaly. Providing such explanation can be as important as detection accuracy in some applications. To derive anomaly explanation from specific detection methods is still a largely unsolved problem, especially for complex models. Developing inherently interpretable anomaly detection models is also crucial, but it remains a main challenge to well balance the model’s interpretability and effectiveness.
Addressing the Challenges with Deep Anomaly Detection
In a nutshell deep anomaly detection aims at learning feature representations or anomaly scores via neural networks for the sake of anomaly detection. In recent years, a large number of deep anomaly detection methods have been introduced, demonstrating significantly better performance than conventional anomaly detection on addressing challenging detection problems in a variety of real-world applications. We systematically review the current deep anomaly detection methods and their capabilities in addressing the aforementioned challenges.
To have a thorough understanding of the area, we introduce a hierarchical taxonomy to classify existing deep anomaly detection methods into three main categories and 11 fine-grained categories from the modeling perspective. An overview of the taxonomy of the methods, together with the challenges they address, is shown in Figure 1. Specifically, deep anomaly detection consists of three conceptual paradigms — Deep Learning for Feature Extraction, Learning Feature Representations of Normality, and End-to-end Anomaly Score Learning.
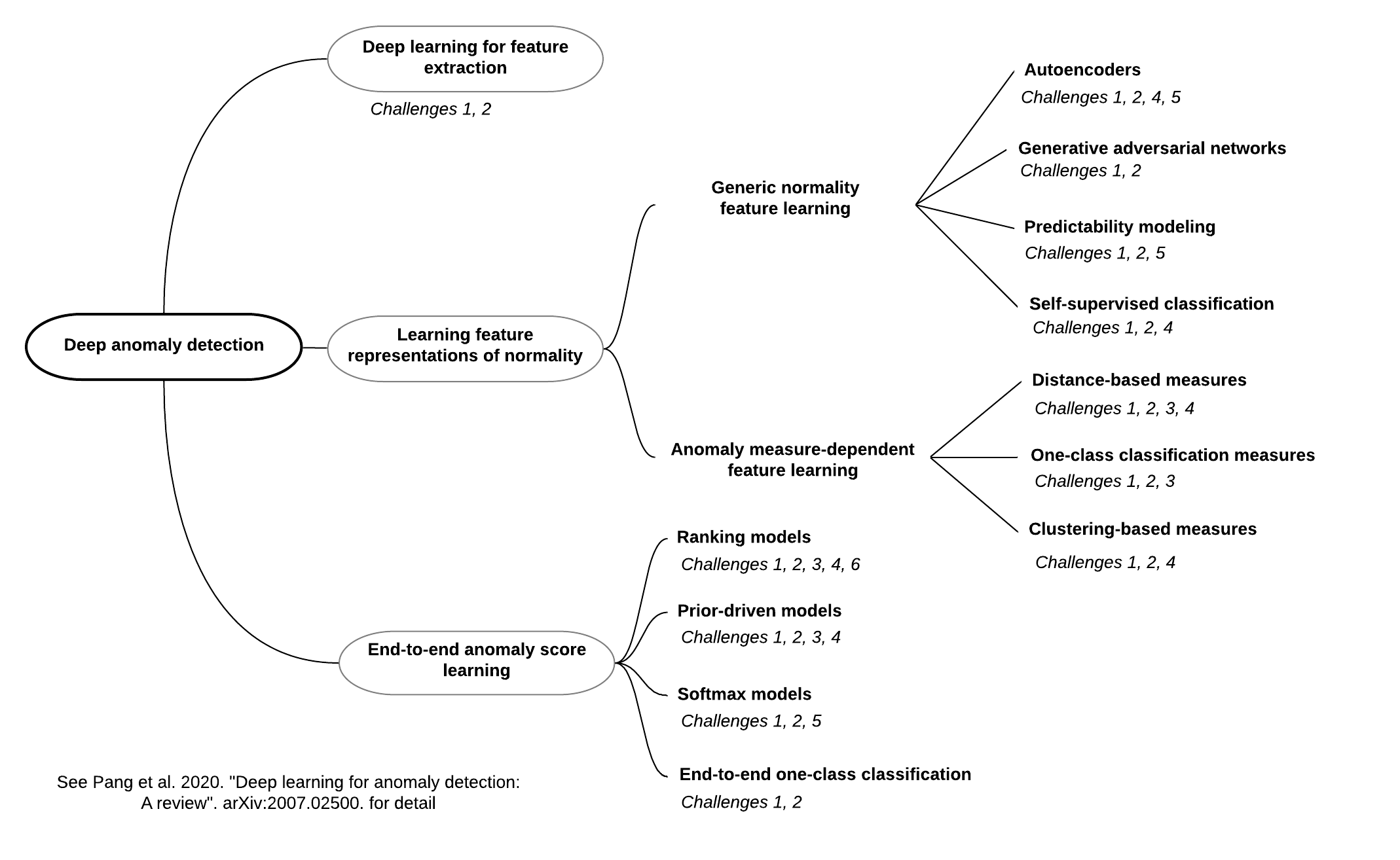
In the Deep Learning for Feature Extraction framework, deep learning and anomaly detection are fully separated in the first main category, so deep learning techniques are used as some independent feature extractors only. The two modules are dependent on each other in some form in the second main category — Learning Feature Representations of Normality, with an objective of learning expressive representations of normality. This category of methods can be further divided into two subcategories based on whether traditional anomaly measures are incorporated into their objective functions. These two subcategories encompass seven fine-grained categories of methods, with each category taking a different approach to formulate its objective function. The two modules are fully unified in the third main category — End-to-end Anomaly Score Learning, in which the methods are dedicated to learning anomaly scores via neural networks in an end-to-end fashion. These methods are further grouped into four categories based on the formulation of neural network-enabled anomaly scoring.
For each category of methods, we review detailed methodology and algorithms, covering their key intuitions, objective functions, underlying assumptions, advantages and disadvantages, and discuss how they address the aforementioned challenges. The full details are difficult to demonstrate here. See the full paper below for detail.



