Graph Database Continue to Grow in Popularity
Interest continues to grow in EKGs. We can see from the DB-Engines popularity change chart below that Graph Databases still outpace interest growth of all other database types by a wide margin.
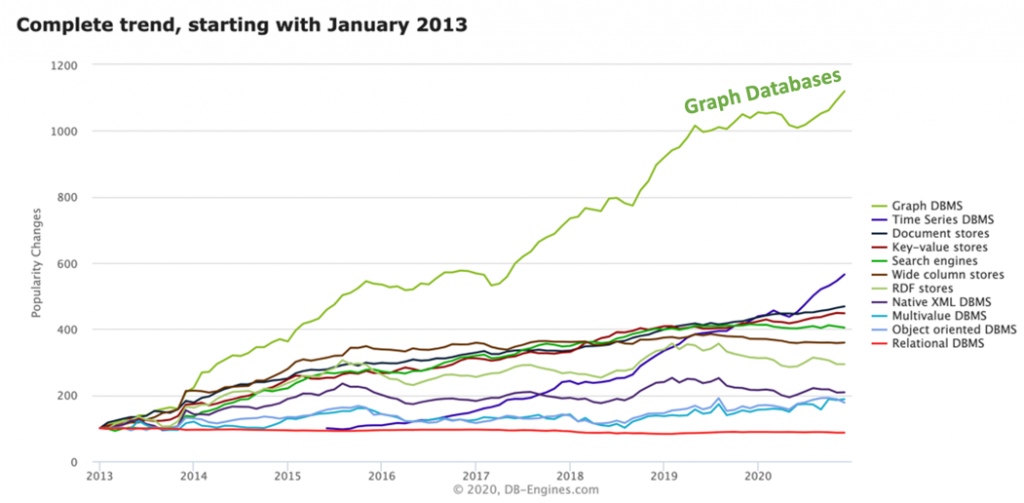
In the DB-Engine taxonomy, the Graph DBMS trend lines exclude RDF stores that are tracked separately. RDF stores (triple stores) are not experiencing the same growth in interest as the graph database industry.
The continued industry-wide acceptance of graph databases as an option to traditional relational databases has been gratifying for me. Like me, other senior solution architects believe that relational databases have had a good run but are no longer giving organizations a competitive advantage in the marketplace. There are enough solid use cases of real cost-saving at large organizations that EKGs are now Crossing the Chasm to be used not just by innovators and early adopters, but by customers in the early majority that purchase based on references of documented cost-savings and increased agility.
Alongside the growth in graph databases, we have also seen a growth in the term “Enterprise Knowledge Graph,” with many writers and organizations weighing how they define EKGs. Since my background is in scale-out NoSQL architectures, you can guess that I am somewhat biased in this area. My definitions of what defines an EKGs are all centered around the scalability of graph databases. In summary, if your graph database can’t scale to meet the enterprise-scale needs of a Fortune-500 company, you don’t really have an EKG. We should call these systems “project knowledge graphs” or “departmental knowledge graphs.” So here is my working definition of a true EKG:
An Enterprise Knowledge Graph (EKG) is a type of graph database designed to scale-out to meet large organizations’ demanding requirements to store diverse forms of connected knowledge.
Note that there are no requirements in this definition that any Semantic Web Stack components must be used to qualify as an EKG. We can still use the phrase “semantic knowledge graphs” for these systems. However, in my book, if a system can’t meet most of the six key criteria for scale-out, like the ability to automatically rebalance a cluster, I don’t classify them as true EKGs.
Words are important, and I will address these definitions again in future blogs and give precise definitions of the term “scale-out” for people who are not familiar with this concept. Our book “Making Sense of NoSQL” (co-authored by Ann Kelly) is a good starting point if you are not familiar with terms such as auto-sharding and automatically rebalancing a graph cluster as it grows.
First Public GQL Working Draft
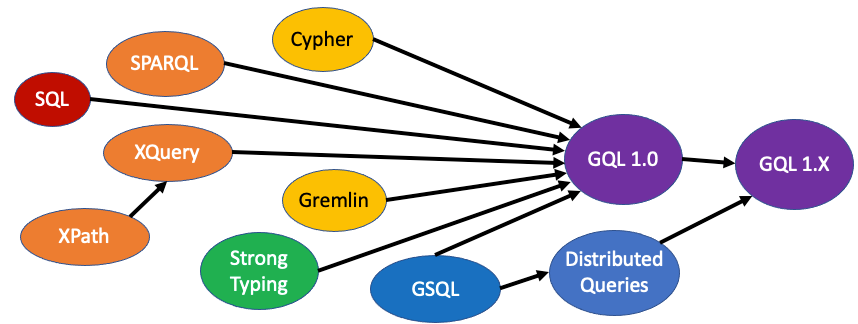
In 2021, we will see the first public working draft of the new GQL standard to query labeled property graphs. I have been meeting almost every other week with over 30 other people working on this standard. It is exciting to see the document take shape.
Although I am not an expert on query language standards, I am continually impressed with the incredible experience and dedication of the GQL standards committee. These unpaid volunteers have a common vision of how GQL can transform the database industry. I have a renewed respect for the level of detail this group is going through to create a new standard that could unite a very fragmented graph community. I hope that the GQL standard brings the best of what we have learned from SPARQL, Cypher, Gremlin, and GSQL into a new standard that allows us to express complex graph queries and graph algorithms in ways that make them 10x to 100x more accessible then what they are today.
Getting an ISO-standard graph query language that supports Labeled Property Graphs (LPGs) is one of the key trigger-points that will accelerate EKGs’ adoption. CIOs will have the confidence their server-side logic and algorithms will be portable to multiple back-end databases. Third-party software developers will jump into the market and provide turn-key solutions for enterprise-class problems that are more cost-efficient than older relational models and far more scalable.
You can see me and a panel of GQL experts talking about this topic at the GQL panel at the Graph+AI World Conference.
The Rise of Graph-Tuned Full Custom Silicon Hardware
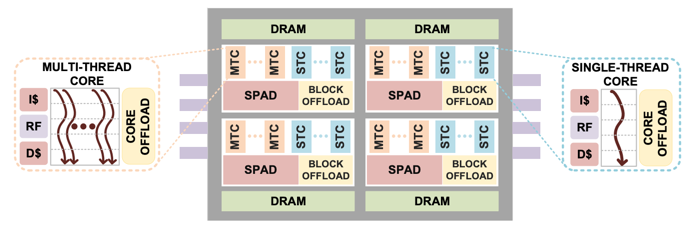
Because of the increased attention that graph databases are getting, we also are starting to see innovation at the hardware level. For the past 1.5 years, I have been predicting the rise of the Hardware Graph built on EKGs’ foundations. The need for custom graph hardware becomes obvious if you realized that most graph algorithms are doing simple pointer-hopping and don’t need 90% of the instructions in today’s CISC hardware. Using a RISC instruction set tuned to optimize pointer-hoping, we could fit 10x more cores on a chip and get a 10x performance boost in query performance.
Although innovative companies like Graphcore have produced innovative custom silicon hardware that has been optimized for graph traversal, their hardware requires us to rewrite our algorithms in low-level C code. And as you can guess, most enterprises want to keep their algorithms independent from a specific hardware architecture. Besides a few large organizations with C developers handy, there has not yet been widespread adoption of custom graph hardware by graph database developers.
But in 2021, I think this will all start to change.
The key turning point happened in October 2020 when Intel published their landmark paper on their new PIUMA hardware architecture that is custom designed for fast graph traversal. Much of this work was driven by the DARPA HIVE project. We all need to appreciate the DARPA team’s groundbreaking work and their willingness to allow commercial organizations to benefit from their research. I have written extensively about the fantastic work that Intel has done to deeply understand the need for a RISC instruction set and the need to radically redesign the memory subsystems to keep the RISC cores feed with data.
Redesigning memory hardware was one of the key insights that Cray and DataVortex had many years ago. Still, it was only available in custom-built high-performance supercomputing systems at incredible costs. The PIUMA architecture could prove a 10x to a 100x additional speedup for some graph algorithms on top of the 10x core speedup. My sincere hope is that the Intel PIUMA hardware could be much more affordable than a Cray Graph Engine.
If you are interested in learning more, I co-presented with the incredible Nikhil Deshpande from the Intel PIUMA team at the Graph+AI World conference.
Machine Learning in Graphs
No topic consumed me more in 2020 than the role of machine learning in graph databases. Although were are not there yet, in the next few years, LPG graph databases will have their own “AlexNet Moment” in the AI community.
For those who have not been following AI closely, AlexNet was one of the first algorithms to utilize parallel processing and GPUs to train deep neural networks to classify images. At an image recognition contest in 2012, AlexNet achieved an incredible 10.8 percentage points lower error rate than the competition. When a 1 or 2 point annual improvement was the norm, you can see that this stunned the AI community and proved beyond any doubt that deep neural networks had many advantages over traditional machine learning algorithms.
There has been a similar rush to use deep neural networks to create predictions from data in graph databases. In December, at NeurIPS 2020, one of the world’s largest AI conferences, over 136 papers had the word “graph” in their titles. Many other papers discussed how knowledge from different domains could be analyzed by using graph representations of knowledge. In 2021 we expect to see continued innovations combining machine learning with data stored EKGs.
Embeddings Everywhere
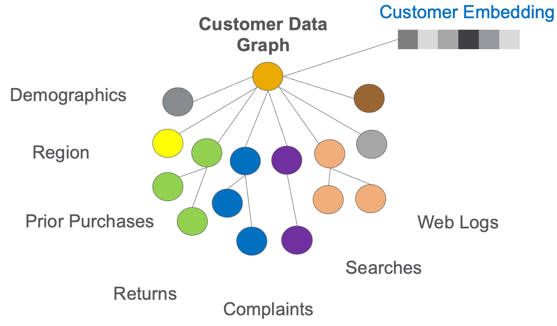
One of the chief tasks of deep learning is to help us classify items and find representations that can be used for fast, real-time processing, such as finding similar items. Last year, I mentioned that similarity algorithms are some of the most critical algorithms for EKGs. Similarity is at the heart of recommendation systems. Although there are many different graph algorithms to find similar items in a graph, the most common is an algorithm called Cosine Similarity. Although there are many manual ways to find the key features for building ML models, these methods are slow and require constant tuning of each feature’s weights.
What has been happening is that we are starting to use the knowledge gains in natural language processing (NLP), data science, and machine learning to help us automatically find embedding for complex LPG knowledge graph structures.
We are essentially telling a query to “randomly walk” around each vertex and determine what makes this vertex unique. Just like NLP has learned to build word embedding from the unlabeled text, we use random walk algorithms to build sentences that describe a vertex.
To learn more, I wrote a detailed blog on Understanding Graph Embeddings in November of 2020.
Once we have these Embeddings, we can use custom Field Programmable Gate Arrays (FPGA) hardware to find similar items using efficient parallel processing techniques quickly. Given high-quality embeddings produced by machine learning, a typical FPGA can find the 100 most similar items in a set of 10 million items in under 50 milliseconds! You can learn more about using FPGAs to find similar items in an EKG at the talk I did with the fantastic Kumar Deepak from Xilinx at the Graph+AI World Conference.
Using an FPGA to quickly find hundreds of similar items among millions in 1/20th of a second is not just a one-time trick. FPGAs are universal tools for doing many parallel computations in graphs. Everyone building EKGs should have a deep appreciation of when algorithms are serial and when they can be done in parallel. The question “Can we speed this up by using an FPGA” should be top of mind when real-time graph queries are needed. I will be writing more about how FPGAs are used in graphs in 2021.
Vertex-level Role-Based Access Controls
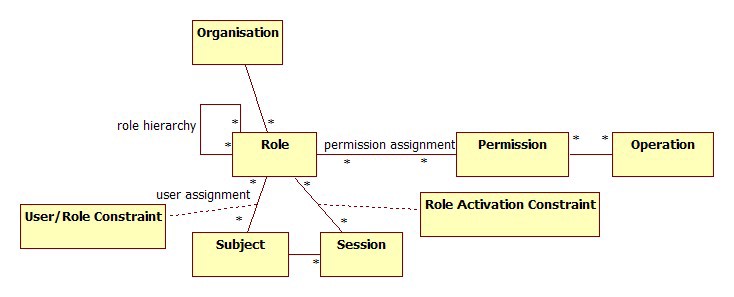
One of the defining features of enterprise knowledge graphs is their ability to give many developers (hundreds to thousands of concurrent developers) direct query-level access to the graph database. The challenge with many other technologies such as Data Lakes is that they don’t allow fine-grain access to individual vertices and edges. In 2020 we saw the first introduction of vertex-level role-based access control (RBAC) rules by enterprise graph vendors.
This means that we no longer need to restrict graph database access to only certified application queries. Using only certified application queries was a way to provide access control to sensitive data in an enterprise graph in the application layer. However, that restricted an entire class of users that wanted to use our EKGs for ad-hoc data discovery. Discovery has been one of the big cost-savings driving the adoption of EKGs.
The addition of vertex-level RBAC feature is critical for the continued growth of the EKG industry. Many EKG projects have been held back because they didn’t offer RBAC commonly available in RDBMS systems, although at the row-level of a table, not a graph’s vertex-level. Now that this feature is available in commercial graph databases, it raises the entry barrier for other graph database startups. Vertex-level RBAC is difficult to implement at scale without a significant drop in performance.
Growth in Cloud and LPG Companies, Downsizing at Semantic Web Product Companies
Although 2020 was a banner year for many graph companies, it was sadly not a great year for all of them.
Major cloud providers continued to promote their graph-based products. Although many cloud vendors are constrained by their use of Gremlin for enterprise-scale projects, they continue to push forward, building smaller project and department-level graphs. These smaller projects can still be a good training ground for organizations to experience graph databases’ power and flexibility and build graph query skills in their employees. They are essentially boot camps for teams building EKGs in the next few years.
Around mid-year, we became aware of layoffs and downsizing at some companies that remain focused on the older semantic-web stacks. Although these products still have merit for managing smaller glossaries, vocabularies, taxonomies, and ontologies, I think the COVID-pandemic struck them hard. This is also a mature space, and there is plenty of competition. Fortunately, I am already aware that a few people laid off from these firms have gone on to other graph-related projects and wish them all the best of luck. Hang in there, everyone! 2021 is going to be a lot better!
Natural Language Processing (NLP) and EKGs

Of all the fields closely related to EKGs, the field that has seen the most excitement has been NLP. This has been building since the BERT paper was published in October of 2018. BERT created an “AlexNet Moment” for NLP in 2018, and there have been dozens of related projects that use unsupervised learning and Transformer models since the BERT paper was published.
The hype around a revolution in NLP and AI started to almost go out of control with the announcement of GPT-3 by OpenAI in June of 2020. This was a bit of a “show off” stunt by OpenAI to show how these language models can scale to the 175B parameter level at the cost of about $10M in training the models. The image in the figure above shows what I think is an impressive example of how GPT-3 works. I give the largest GPT-3 Davinci model a prompt of:
“The reason that enterprise knowledge graphs will continue to grow in popularity is because”
and it returned a pretty impressive 200-word response and cost about a penny.
Tools like BERT and GPT will slowly become a “bridge” that connects the world of documents and text with the world of EKGs. NLP services built on BERT and GPT will cost-effectively ingest millions of documents and return precisely coded concept graphs for each document linking documents that both discuss the same concept in a materialized and queryable edge between the concept graphs for each document.
Why is this important? Today, 80% of the “Knowledge” in large companies is tied up in documents like MS-Word, PDF, FAX, and HTML web pages. We know that EKGs can be useful for integrating these documents if we can extract the precise facts from the documents. Then we can encode and connect these facts as vertices in our knowledge graph. Once the facts are extracted and linked, then we can use the power of graph-machine learning to calculate embedding and find similar documents and similar concepts quickly by combining both deterministic rules and embeddings. This capability will continue to expand EKG projects’ scope and push the need for more cost-effective EKG hardware.
EKG Virtual Conferences and Communities
Despite the complete shutdown of most face-to-face in-person graph-related conferences, many virtual conferences did go forward with increased attendance from a growing worldwide audience interested in EKG topics.
The biggest new conference was the Graph+AI World conference that combined not just case studies of large enterprise knowledge graph rollouts. Still, it also had several expert panel discussion on EKG related topics. For me, it was the best conference of the year that combined sessions on EKGs mixed with a focus on GQL standards, machine learning, and NLP technologies.
I was also happy to see that the Knowledge Connections conference successfully made the leap to a fully virtual format and hosted many interesting presentations on knowledge graphs.
EKG Books, EKG Maturity Models, and EKGs Blogs and More!
I think that 2021 will be another high-growth year for EKGs, continuing to add innovation that will launch new products through 2022. Combining the GQL language, custom EKG hardware, Graph-Machine learning, NLP, and a growing library of blogs, case studies, books, and more scalable and robust EKG software customized to the needs of large organizations will continue to transform the database industry.
Conclusion: Invest Now!
Last year, we continued to see that enterprise knowledge can act like an invisible force that binds organizational data together in a consistent way. Just like gravity and magnetism, connected knowledge can pull more knowledge into the EKG. Network effects apply. EKGs have driven innovation, new insight, and clear cost savings for organizations that have implemented them.
If you are thinking about starting up a new company that leverages EKGs’ power, I think 2021 would be an ideal year to launch your company. If you are VC or angel investor, you should be looking for small startups in the graph space that combine ML, NLP with EKG technologies. These firms will quickly grow around the new GQL standards and 1,000x graph hardware accelerations we will be seeing in 2021 and beyond.
Happy New Year, everyone!



