The Four Lands of EKG Adoption
This blog is a metaphorical journey that many of us are taking toward the concept of building large enterprise-scale knowledge graphs (EKGs). We will look at the three transitions that teams need to make to go from problem-solving using flat representations of data to billion-vertex EKGs running on hardware-optimized graph servers.
To help teams make these transitions, we must understand the new cognitive styles teams must learn when promoting EKGs. We will show how people can transition from problem-solving styles using flat data representations, through small graphs, to large graphs, and finally, the problem-solving involving Hardware Optimized Graph (HOG) databases. We will focus on the three distinct transitions teams will make in looking for new patterns in business problems.
Teaching how to make these transitions is essential for EKG evangelists to be successful in large organizations. Our goal here is to create an entertaining roadmap for our stakeholders using vivid stories that are easy to recall. Our hypothesis is that these vivid stories can be retold when we are not around. Great stories help teams gain the confidence they can retell these stories and explain to other stakeholders why the EKG journey to HOG Heaven is worth it.
We will be using the Journey Map metaphor throughout this article. Each land will feature key inhabitants and its own set of monsters. Perhaps we can create a role-playing game out of this adventure. You are standing in an open field…let the journey begin!
Background on Cognitive Styles
In August of 1989, while I was working at NeXT Computer with Steve Jobs, I attended a presentation by Dr. Ed Barboni, who was then at Allegheny College. The innovative NeXT Computer was being marketed to education, and Ed had become one of the chief evangelists for teaching new problem-solving skills using advanced NeXT computers.
Ed introduced us to a concept he called a cognitive style, where people with specialized training develop a specific pattern of thinking and problem-solving. Ed strongly believed that using the NeXT computer to perform tasks such as creating and running simulations would change the way that students solved problems.
The impact of technology on problem-solving and knowledge mastery in computer-filled factories and offices was studied in depth by the Harvard writer Shoshana Zuboff in her 1988 book “In the Age of The Smart Machine.” For almost two years, I read, reread, and tried to apply the principles in her book to building a curriculum to teach GUI-based object-oriented programming using the NeXTStep Interface Builder tools. These fields have continued to evolve into what we now call “Computational Thinking.” These are abstract patterns we try to embed in all our online training in the CoderDojo programs.
For several years I tried to integrate these concepts into my connection-driven object-oriented programming courses at NeXT. I found merit in Zuboff’s ideas about different people with different backgrounds solving problems differently. Teaching new cognitive styles requires exposing students to new problem/solution patterns and finding out how to create a curriculum around these patterns.
Designing a high-quality curriculum to help students make the transition to these new styles was a non-trivial process. It required teaching the same course a large number of times with careful observations and testing of the individual lessons and multiple iterations to achieve good outcomes. This is something I am spending many hours on in the EKG space now.
Central to this process of helping people adopt new cognitive styles is to recognize and label different styles and learn strategies to help students gracefully transition to new cognitive styles without too much stress. We need to provide stepping stones to help them move in new directions. Here is my attempt to label and identify four distinct styles in the roadmap to adopting EKGs as the core of an organization’s central nervous system.
Assume a Positive Intent
We begin our journey across these four lands with an assumption of positive intent. We make the assumption that all our participants in this shared journey want to serve their customers well. They are not deliberately holding back services from their customers. They just don’t have the appropriate background and experiences to migrate from one land to another. We ask the question, “how can we help them on their journey.”
We make the assumption that if our participants deeply understood the pros and cons of each of the lands, they would make the best decision to build systems that serve their customers. But many of our teams are stuck in one land with a considerable investment in existing systems. Sometimes it is third-party software that only runs on legacy databases. Sometimes, it is believed that old ways will continue to work despite competitors continuing to leverage newer technologies. Whatever their biases are, it is the EKG evangelist’s job to help them make the transition to the next level of cognition when they are ready to do so.
The Four Lands of Enterprise Knowledge Graphs
To help us visualize the different cognitive styles on the roadmap to adopting EKGs, let’s create four distinct “lands of cognition” and give them labels. We will think of each of them as isolated islands of problem-solving patterns and look for the changes we need to make to get them to migrate to the next island of problem-solving. We begin with a place I call “Flatland,” named after the delightful 1884 satirical novella by Edwin Abbott. This book and the subsequent movies made from it deserve their own blog, but that is for another post.
Island 1: Flatland
Flatland is our starting point for data cognition. Flat tabular representations of knowledge characterize our Flatland. Everything we see in the world around us needs to fit neatly into rows and columns of a table. This flat representation of knowledge is very convenient. It really started 5,000 years ago when agriculture first became popular in the fertile crescent, and we started to write accounting records in clay. These clay tablets recorded agricultural transactions in rows and columns. Our accounting systems still do this today.
Flatland is a crowded place. My estimate is that 90% of non-Bay Area organizations live here. Many have lived here for most of their careers.
Flat knowledge representation evolved over the years from clay tablets to papyrus scrolls, paper ledgers, punchcards, COBOL flat files, and to tables in relational databases. One of the greatest inhabitants of Flatland is the spreadsheet.
For several years I worked at a firm that had a large accounting division. They typically hired accounting students directly out of college, and senior partners in the firm supervised their training. These senior partners used spreadsheets extensively. What was surprising to me was how clever they became at using spreadsheets for almost every task they did. Instead of using MS-Word, they would send me long text documents in cells of a spreadsheet. Instead of using PowerPoint, they flipped through spreadsheet tabs with new text and graphics. When they had a database problem, Excel became their database, when they had programming tasks, Excel macros because of their programming language.
What was clear was that they used the tools they had in clever ways, but when they were given a new task that didn’t fit well into rows and columns, they often struggled. When an item had relationships to many other items, they often crammed a cell with comma-separated values. When rows had many unknown values for cells, their spreadsheets were mostly empty (sparse).
Flat files then sprouted a new feature called an external reference. These were ways of comparing two columns in two tables to see if things were related to each other. If they were, then these tables could be JOINED, and a new table was born.
The challenge is that although JOIN operations worked well for joining two or three tables, the more tables that had to be JOINED, the slower the performance. Things with really complex relationships were hard to model and hard to scale. In truth, the data modelers all agree that they had to cut corners to keep the number of joins down. They were fighting JOIN monsters with dirty denormalization swords. These decisions dulled the precision of the models and clouded reality. Data elements were sometimes filled with data that didn’t belong there. Small lies about the true meaning of a column crept in and made reporting teams pull out their hair in anguish.
When these new relational models were being created, they were soft and squishy and were easy to mold. But as more and more data was loaded, they became hard and brittle — like concrete hardening. Things became harder with every report that was created. Eventually, even small changes required a lengthy journey up the mountains to visit the data modeling change control committee. Few people return from the mountaintop with smiles on their faces.
Users in Flatland require patience. Their web pages take tens of seconds to render, and they seem to always get slower as more data is loaded into their systems. Sometimes users stay up late at night when there are fewer other people on the systems.
Users in Flatland walk around with a large ball-and-chain called “ERP” wrapped around their legs. These systems were designed to manage the traditional accounting and financial systems of a company. But they don’t do well creating sub-50 millisecond recommendations for 20,000 concurrent users on your website.
The speed racers in Flatland drive cars powered by single large fact tables with only single level JOINS to shared dimensions. When teams can’t agree on the facts or dimensions, they quickly build new cars to optimized their JOINs. Flatland’s original goal was to have a single data warehouse where everyone would come to worship the analysis gods. Now there are hundreds of little datamarts driving around the island, each with their own version of the truth.
Cognitive Styles: What can we fit in this table, row, or cell? How can we keep models simple? How can we minimize JOINs?
Key Players: Spreadsheets Monsters, JOIN Monsters, Scale Monster, Fact Table Speed Racers
Island 2: Single Node Graph Land

On this second island live people that have vanquished the JOIN monsters forever. Instead of comparing columns when they traverse relationships, they simply jump through memory pointers. They are light and swift. But only about 5% of the teams I work with have ever ventured to Single Node Graph Land.
This land is rich in performance and insight. In this land, web screens all render in 1/100th of a second. The shores of Single Node Graphland are filled with beautifully complex shapes and many complex relationships that mirror the real world. There are no compromises on truthful models. Developers feel they are in paradise and sip piña coladas from the beach huts.
Single Node Graph Land is a relative paradise because people don’t live with the JOIN monsters’ fears. When complexity comes up, they just deal with it by adding new relationships at will. As a result, the data models are full of truth and beauty. Data models are gracefully displayed as public sculptures of the truth. No one has any oversimplification secrets to hide. Everyone shares a single data model because it is a truthful model of the world. Sharing helps drive down costs.
Everything is fine until the “new data load” tsunami hits them. Then the operations team starts to scramble. Because if those little pointers don’t fit in the available RAM, suddenly all the queries slow down, waiting for new data to get swapped in from SSDs or, worse, eternally slow spinning disks. Adding extra RAM helps for a bit, but the design is fundamentally unstable as data sizes grow. Response times become hard to predict. Pilot projects tend to stay isolated from real enterprise-scale problems, and graph teams focus on problems that fit the server’s RAM. Developers live in fear of new data loads and work hard to keep everything in RAM.
Cognitive Style: Precise models of the real world, shared models. But what can we fit in RAM?
Key Players: Developers in beach huts, Too Little RAM, Scale Monsters, Data Load Tusanmi, Sloth-like Slow Spinning Disks
Island 3: Distributed Graph Land
The third chapter of our journey is to a relatively new island: Distributed Graph Land. This island has only been around for most companies for three years, although Bay Area companies like Google, Facebook, and LinkedIn have lived on this island for over eight years. This island has many of the same wonders of single node graph land. The models are precise and can be shared by many business units. But there is one key difference. The dreadful RAM Monster has been left behind! No more fear of new data loads destroying performance!
On this island, when new data is loaded, new servers magically merge with the main island. Data transparently rebalances over the new land. No subregion of the island is under undue stress. All evenly share the work.
And no services are interrupted during periods of growth. Everything keeps humming along without a hitch. As big seasonal projects wrap up, these servers can be moved to other critical projects. The size of the island is fluid, and it grows and shrinks as demand changes.
But there is are still a few monsters here. The rents are still incredibly high. There is a lot of demand but not enough supply of connected data. The cost of importing many different data sources with complex Change Data Capture (CDC) systems is non-trivial. It takes time and effort to merge data together using simple deterministic rules.
The challenge here is to keep the cost of the system in check. RAM is now inexpensive, but the software layers can still run into six to seven figures per TB per year. Careful decisions need to be made about what data stays in the graph.
This land is not heavily populated yet. My guess is that less than 3% of companies are really building true scale-out enterprise knowledge graphs. However, there are many that are slowly realizing they should consider it as a way to lower cost, have integrated views of their customers, offer better recommendations and predictions, leverage machine learning, and create a faster time to insight.
Because the island is still new, there is simply not enough competition in the marketplace to keep the costs down. A few vendors dominate this island. The discussion is about RAM-ROI. What elements can we afford to keep in RAM? As a result, only data that has urgent needs by the business is permitted on the island. If the business is not willing to pay for a display or report, the data pushed off the island into the deep ocean of a blobstore, where the queryability drops by orders of magnitude.
On this island, how to grow the island is not based on the dreams of people seeking deep insights into apparently unrelated data. The decisions are based on the ruthless short-term cost-benefit analysis of the accounting department. Data that is more than a year old needs a wealthy patron, or the data retention rules kick in on a daily basis. That fraud data you were looking at yesterday — poof! It is gone today.
Fraud investigators that need five years of historical data to uncover patterns now stare at unconnected graphs. They know there are connections to be found, but they now must resort to grep-ing through old blob stores and S3 buckets. Their LED candles burn low late into the night.
Data scientists with brilliant hypotheses about new Baysian cause and effect models are left homeless in the slums of despair because their data is no longer in the EKG. They panhandle the streets with their steampunk machine learning models and their threadbare Jupyter Notebooks full of scrawls of equations where only they see the true beauty.
And teams that want to be notified if there is an unusual activity? Well, they have a few reports that run once a night. These reports are not a lot to go on, so they often miss key changes before they can put in countermeasures. Not all early interventions are feasible due to the high cost of operations.
Key Players: Ruthless accountants, disappearing data, fraud investigators with dead ends, discouraged data scientists, notification too late to take action.
Island 4: Hardware Optimized Graph Land (a.k.a. HOG Heaven)
Hog heaven: a state of great ease or happiness
Today we are standing on the Distributed Graph Land shores, looking across the sea of a new island just forming in the new volcanic eruptions. This island is not yet widely habitable, but many of us can see its potential. This is the land of Hardware Optimize Graph (HOG). We call it HOG Heaven because it has the promise to make our EKG as a true Central Nervous System are reality. In HOG heaven, we see a state of great ease and happiness.
We knew this land was there because of the legends told about the Cray Research Graph Engine performance back in 2014 (see 6.10 our NoSQL case study here). We knew graph systems could scale to the tens of thousands of GTEPS because we could see them in the Graph500 benchmarks. But could an average company put their ACID transactions in this database and get five-nines of high availability?
On this island, there are a huge number (tens or hundreds of thousands) of cores waiting for new tasks. A query arrives, and these threads immediately start traversing your graph, quickly traversing the links near the threads in memory. Our programs are small and precise and allow us to perform complex operations and look for deep patterns within complex structures.
In HOG Heaven, historical data is retained for years. Fraud investigators constantly are finding bad behavior and saving money.
The Embeddings Everywhere Movement is part of the religion of HOG Heaven. Machine language algorithms are constantly scanning subsets of the graph and rebuilding embedding for almost every vertex. Data stewards use these embedding to constantly monitor data quality and consistency on every new data import.
Data no longer needs to be sent over to a GPU cluster for training. We have plenty of CPU power here. Machine learning is done In Situ. Data does not needlessly move around, and the security team sleeps well at night.
And your data scientists? They are discovering new insights they have never imagined. They are constantly using real-time query and discovery processes to work in real-time with subject matter experts that constantly pose new questions. Billion vertex queries are only a moment away.
And those early warning systems you never could afford to put in place? There are thousands that constantly run in the background. They find anomalies while there is time to put in interventions. These are better than the pre-cogs in Minority Reports.
HOG Heaven is Deep Systems Thinking

HOG Heaven is not an accident. It is the result of deep Systems Thinking. This thinking goes all the way from the customer needs right down to the CPU instruction set and memory access hardware. It is a result of careful understanding of how we store connected knowledge to best serve our customers and empower our data scientists to become productive knowledge scientists. The component interactions are complex: labeled property graphs, index-free adjacency, distributed databases, fast pointer hopping, and clever hardware design that puts high core counts and fast memory lanes in cost-effective solutions all interact with each other.
Finding Allies and Identifying Reluctant Team Members
One of the lessons we have learned in our promotion of EKGs is that large strategic changes in direction need broad consensus. Getting an executive sponsor is just the first step. We need allies up and down the organization. Sometimes allies come from unusual places.
For example, are their leaders in Human Resources are that can help you find change agents in your organization? Are there team members from your enterprise security teams that are worried about the sprawl of hundreds of mini-datamarts? Are there people in marketing that want to promote your organization as being a leader in AI?
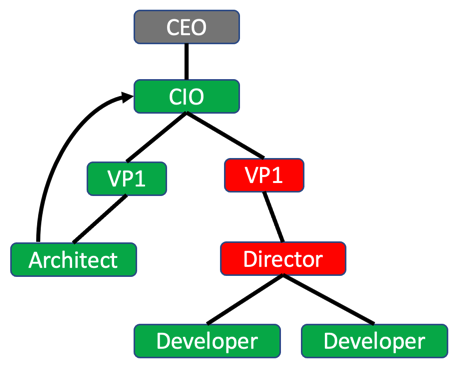
Building an organization chart influence diagram can be another “systems thinking” way to approach the problem of seeing who is on what island and what you need to do to move them to the next island.
Whatever your journey, don’t try to do it alone. We want you to seek out other members of our growing EKG community and share both your success stories and your defeats. We can all learn from each other in this shared journey.
Happy travels!



