What Google AI’s PlaNet AI means for reinforcement learning research and how transfer learning plays a key role.

Learning to walk before we can run
Transfer learning is all the rage in the machine learning community these days.
Transfer learning serves as the basis for many of the managed AutoML services that Google, Salesforce, IBM, and Azure provide. It now figures prominently in the latest NLP research — appearing in Google’s Bidirectional Encoder Representations from Transformers (BERT) model and in Sebastian Ruder and Jeremy Howard’s Universal Language Model Fine-tuning for Text Classification (ULMFIT).
As Sebastian writes in his blog post, ‘NLP’s ImageNet moment has arrived’:
These works made headlines by demonstrating that pretrained language models can be used to achieve state-of-the-art results on a wide range of NLP tasks. Such methods herald a watershed moment: they may have the same wide-ranging impact on NLP as pretrained ImageNet models had on computer vision.
We’re also starting to see examples of neural networks that can handle multiple tasks using transfer learning across domains. Paras Chopra has an excellent tutorial for one PyTorch network that can conduct an image search based on a textual description, search for similar images and words, and write captions for images (link to his post below).
The main question at hand is: could transfer learning have applications within reinforcement learning?
Compared to other machine learning methods, deep reinforcement learning has a reputation for being data hungry, subject to instability in its learning process (see Deepmind’s paper on RL with neural networks), and a laggard in terms of performance. There’s a reason why the main areas and use cases where we‘ve seen reinforcement learning being applied to are games or robotics — namely, scenarios that can generate significant amounts of simulated data.
At the same time, many believe that reinforcement learning is still the most viable approach for achieving Artificial General Intelligence (AGI). Yet reinforcement learning continually bumps up against the ability to generalize to many tasks in diverse settings — a key attribute of intelligence.
After all, learning is not an easy task. These reinforcement learning agents must process and derive efficient representations of their environment when these environments have both high-dimensional sensory inputs and either no notion of or an extremely delayed notion of progress, reward, or success. On top of that, they have to use this information to generalize past experiences to new situations.
Up to this point, reinforcement learning techniques and research has primarily focused on mastery of individual tasks. I was interested to see if transfer learning could aid reinforcement learning research achieve generality — so I was very excited when the Google AI team released the Deep Planning Network (PlaNet) agent earlier this year.
Behind PlaNet
For the project, the PlaNet agent was tasked with ‘planning’ a sequence of actions to achieve a goal like pole balancing, teaching a virtual entity (human or cheetah) to walk, or keeping a box rotating by hitting it in a specific location.

Overview of the six tasks that the Deep Planning Network (PlaNet) agent had to perform. See the longer video
From the original Google AI blog post introducing PlaNet, here are the six tasks (plus the challenges associated with that task):
- Cartpole Balance: starting from a balancing position, the agent must quickly recognize to keep the pole up
- Cartpole Swingup: with a fixed camera, so the cart can move out of sight. The agent thus must absorb and remember information over multiple frames.
- Finger Spin: requires predicting two separate objects, as well as the interactions between them.
- Cheetah Run: includes contacts with the ground that are difficult to predict precisely, calling for a model that can predict multiple possible futures.
- Cup Catch: only provides a sparse reward signal once a ball is caught. This demands accurate predictions far into the future to plan a precise sequence of actions.
- Walker Walk: where a simulated robot starts off by lying on the ground, and must first learn to stand up and then walk.
There are a few common goals between these tasks that the PlaNet needed to achieve:
- The Agent needs to predict a variety of possible futures (for robust planning)
- The Agent needs to update the plan based on the outcomes/rewards of a recent action
- The Agent needs to retain information over many time steps
So how did the Google AI team achieve these goals?
PlaNet AI…and the rest?
PlaNet AI marked a departure from traditional reinforcement learning in three distinct ways:
- Learning with a latent dynamics model — PlaNet learns from a series of hidden or latent states instead of images to predict the latent state moving forward.
- Model-based planning — PlaNet works without a policy network and instead makes decisions based on continuous planning.
- Transfer learning — The Google AI team trained a single PlaNet agent to solve all six different tasks.
Let’s dig into each one of these differentiators and see how they impact model performance.
#1 Latent Dynamics Model
The authors’ main decision here was whether to use compact latent states or original sensory inputs from the environment.
There are a few trade-offs here. Using a compact latent space means an extra difficulty bump because now the agent not only has to learn to defeat the game but also has to build an understanding of the visual concepts within the game — this encoding and decoding of images requires significant computation.
The key benefits to using compact latent state spaces are that it allows the agent to learn more abstract representations like the objects’ positions and velocities and also avoid having to generate images. This means that the actual planning is much faster because the agent only needs to predict future rewards and not images or the scenario.
Latent dynamics models are being more commonly used now since researchers argue that “the simultaneous training of a latent dynamics model in conjunction with a provided reward will create a latent embedding sensitive to factors of variation relevant the reward signal and insensitive to extraneous factors of the simulated environment used during training.”
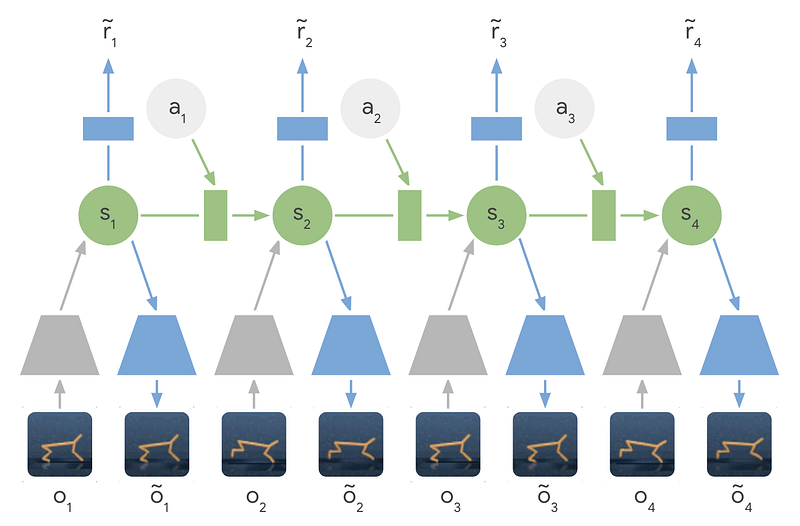
Learned Latent Dynamics Model — Instead of using the input images directly, the encoder networks (gray trapezoids) compress the images’ information into hidden states (green circles). These hidden states are then used to predict future images (blue trapezoids) and rewards (blue rectangle).
Check out this excellent paper ‘On the use of Deep Autoencoders for Efficient Embedded Reinforcement Learning’, where they state:
In autonomous embedded systems, it is often vital to reduce the amount of actions taken in the real world and energy required to learn a policy. Training reinforcement learning agents from high dimensional image representations can be very expensive and time consuming. Autoencoders are deep neural network used to compress high dimensional data such as pixelated images into small latent representations.
#2 Model-based Planning vs. Model-free

Great diagram from Jonathan Hui showing the spectrum of reinforcement learning approaches
Model-based reinforcement learning attempts to have agents learn how the world behaves in general. Instead of directly mapping observations to actions, this allows an agent to explicitly plan ahead, to more carefully select actions by “imagining” their long-term outcomes. The benefit of taking a model-based approach is that it’s much more sample efficient — meaning that it doesn’t learn each new task from scratch.
One way to look at the difference between model-free and model-based reinforcement learning is to see whether we’re optimizing for maximum rewards or least cost (model-free = max rewards while model-based = least cost).
Model-free reinforcement learning techniques like using Policy Gradients can be brute force solutions, where the correct actions are eventually discovered and internalized into a policy. Policy Gradients have to actually experience a positive reward, and experience it very often in order to eventually and slowly shift the policy parameters towards repeating moves that give high rewards.
One interesting note is how the type of task affects which approach you might choose to take. In Andrej Kaparthy’s awesome post ‘Deep Reinforcement Learning: Pong from Pixels’, he describes games/tasks where Policy Gradients can beat humans:
“There are many games where Policy Gradients would quite easily defeat a human. In particular, anything with frequent reward signals that requires precise play, fast reflexes, and not too much long-term planning would be ideal, as these short-term correlations between rewards and actions can be easily “noticed” by the approach, and the execution meticulously perfected by the policy. You can see hints of this already happening in our Pong agent: it develops a strategy where it waits for the ball and then rapidly dashes to catch it just at the edge, which launches it quickly and with high vertical velocity. The agent scores several points in a row repeating this strategy. There are many ATARI games where Deep Q Learning destroys human baseline performance in this fashion — e.g. Pinball, Breakout, etc.”
#3 Transfer Learning
After the first game, the PlaNet agent already had a rudimentary understanding of gravity and dynamics and was able to re-use knowledge in next games. As a result, PlaNet was often 50 times more efficient than previous techniques that learned from scratch. This meant that the agent only need to look at five frames of an animation (literally a 1/5 of second of footage) to be able to predict how the sequence will continue with remarkably high accuracy. Implementation-wise, it means that the team did not have to train six separate models to achieve solid performance on the tasks.
From the paper: “PlaNet solves a variety of image-based control tasks, competing with advanced model-free agents in terms of final performance while being 5000% more data efficient on average…These learned dynamics can be independent of any specific task and thus have the potential to transfer well to other tasks in the environment”
Check out the stunning data efficiency gain that PlaNet had over D4PG with only 2,000 episodes:
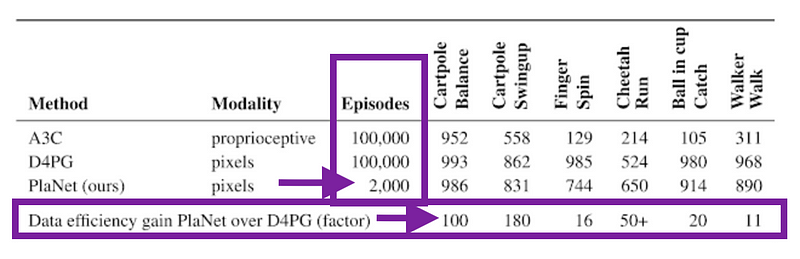
From the paper: PlaNet clearly outperforms A3C on all tasks and reaches final performance close to D4PG while, using 5000% less interaction with the environment on average.
As well as these plots of the test performance against the number of collected episodes (PlaNet is in blue):
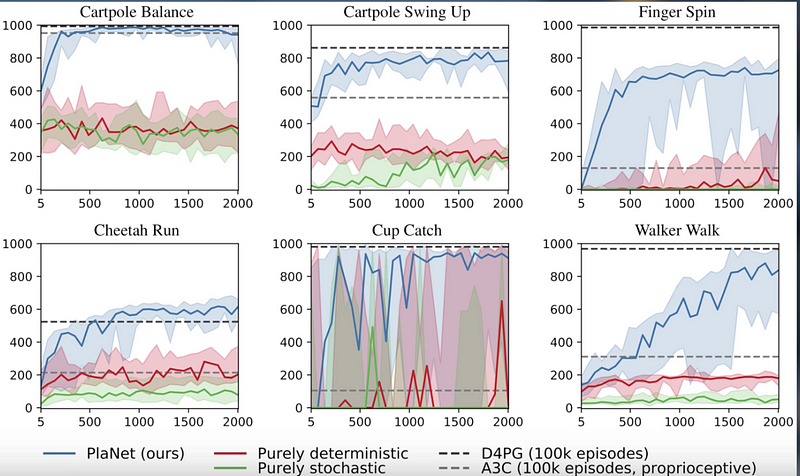
Figure 4 from the PlaNet paper comparing PlaNet against model-free algorithms.
These are incredibly exciting results that mean a new era for data efficient and generalizable reinforcement learning. Keep your eye on this space!
Want to learn more? Here are some other great resources on reinforcement learning:
- TOPBOTS’ Most Important AI Reinforcement Learning Research
- Open AI’s Spinning Up in Deep RL tutorial
- DeepMind’s David Silver’s RL Course (Lectures 1–10)
- Skymind.ai’s Deep Reinforcement Learning
- Andrej Karparthy’s Deep Reinforcement Learning: Pong from Pixels
- [Plus a fun Transfer Learning resource ] Dipanjan (DJ) Sarkar’s Transfer Learning Guide
Originally published at Towards Data Science.


