Bonus: Ordered target encoding proposed by Catboost

Introduction
In my experience with supervised learning, improving the model performance from decent to human-like requires creative feature engineering. Jumping from simple algorithms to complex ones does not always boost performance if the feature engineering is not done right. The goal of supervised learning is to extract all the juice from the relevant features and to do that, we generally have to enrich and transform features in order to make it easier for the algorithm to see how the target variable depends on given data. One type of features that do not easily give away the information they contain are categorical features. They keep on hiding the information until we transform them smartly. In this particular post, I am focussing on one particular categorical encoding technique called target encoding which works really well most of the times, but it has a risk of target leakage if not done correctly. Target leakage means using some information from target to predict the target itself (you see the issue here?). This leakage consequently increases the risk of overfitting on the training data, especially when the data is small. Similar target leakage also exists in standard gradient boosting algorithms. Catboost has implemented a technique called ordering principle which solves the problem of target leakage in both cases. Based on this technique plus numerous other small improvements, Catboost outperforms other publicly available gradient boosting libraries on a set of popular publicly available datasets. The comparison experiments done by Catboost are summarized in this paper — CatBoost: unbiased boosting with categorical features.
Standard Approches
One-hot Encoding — One common technique for dealing categorical features is one-hot-encoding, i.e. for each level of category, we create a binary feature. However, in the case of high cardinality (e.g. city ID , region ID, zip codes), this technique leads to infeasibly large number of features. Tree based models particularly suffer from such a large number of one-hot features because; 1) tree only grows in the direction of zeroes of one hot feature (shown in figure below), 2) if tree wants to split on one-hot (0,1) feature, it’s information gain will be low and thus tree will be unable to get splits from the feature near the root if other continuous features are also present.
Label Encoding — Another standard encoding technique is numerical encoding (aka label encoding) where we assign a random number to each category. This technique infuses some form of order in the data and that order generally doesn’t make sense and is random. We are required to maintain a mapping of category to number in order to later apply same mapping for test data. Maintaining the mapping can sometimes become hard for models in production. Tree based models suffer from this encoding too, as trees find best split based on values less than or greater than an optimum value. In case of random ordering, less than or greater than does not really make any sense.
Hash Encoding — This commonly used technique converts string type features into a fixed dimension vector using a hash function. The hash function employed in sklearn is the signed 32-bit version of Murmurhash3. A 32 dimensional vector can hold 2³² unique combinations. This becomes useful for high cardinality variables where one hot encoding will give huge number of features. I have recently noticed this technique to work really well, particularly for cases where categories have some information in their string pattern.
Pros of hashing: 1) No need to maintain a mapping of category to number mapping. Just need to use the same hash function to encode the test data; 2) Reduction of levels specially in case of high cardinality features, which consequently makes it easier for tree to split; 3) Can combine multiple features to create single hash. This helps in capturing feature interactions.
Cons of hashing: 1) Hash collisions. Different levels of categories can fall into the same bucket. If those categories do not affect target equally, then prediction score might suffer; 2) Need to tune another hyper parameter of number of hash vector dimensions.
Target Encoding — Another option, which is also the prime focus of this blogpost is target encoding (aka likelihood encoding). The idea is to replace each level of the categorical feature with a number and that number is calculated from the distribution of the target labels for that particular level of category. For example, if the levels of categorical feature are red, blue and green. Then replace red with some statistical aggregate (mean, median, variance etc.) of all the target labels where-ever the feature value is red in training data.
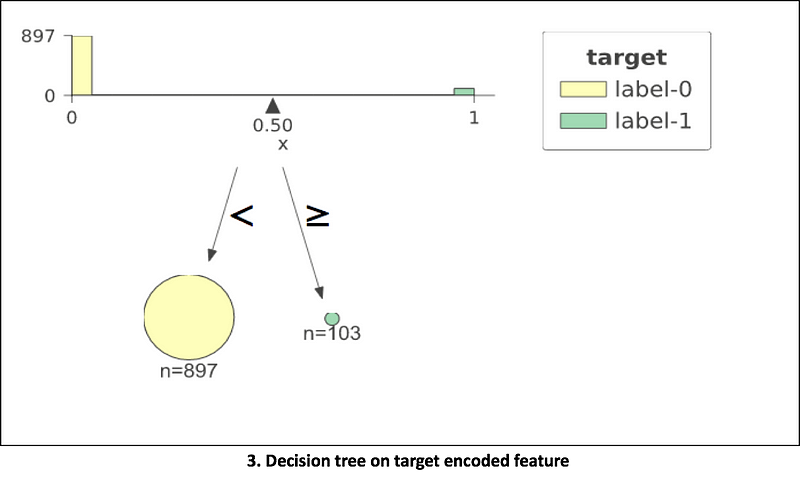
Below plots show how a decision tree gets constructed for a categorical feature when it is one-hot encoded vs. when it is numerical encoded (a random number for each category). The third plot shows the decision tree with target encoded feature. For all the plots, a simulated data of 1000 rows with only one categorical feature and a binary target is used. The categorical feature has high cardinality and has 100 different levels labelled from 0 to 99 (keep in mind order doesn’t make sense as we are treating it as nominal categorical feature). The target is dependent on the feature in such a way that categories that are multiple of 11 (0, 11,22,33 .. 99) have target value of 1 and 0 for all other cases. The data has 897 negative and 103 positive labels). The plots are constructed using dtreeviz library for decision tree visualizations with trees having a constraint of max depth 5. Jupyter notebook link for code to generate these plots.
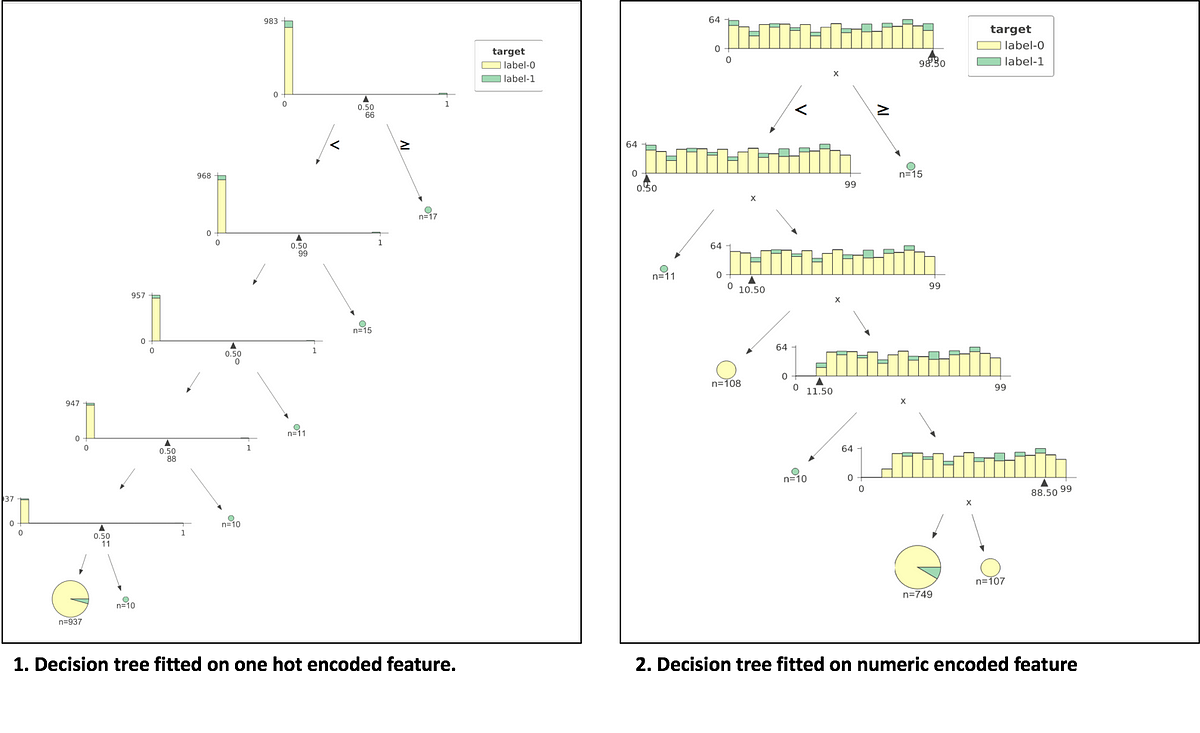
In the 1st plot, we can see that decision tree with one-hot encoded features creates many many splits and the tree is all left-sided. The tree is still getting the work done and is able to separate the data. We observe split values to be 66, 99, 0, 88, 11 respectively from root to leaf. At each split, information gain is low as split focuses only on one level of the categorical feature. If we introduce noisy continuous features, the tree might find more information gain in noise than some one-hot encoded feature and would give those up in feature importance plots, which is sometimes misleading. This issue is discussed in detail in this blogpost — Are categorical variables getting lost in your random forests? and this kaggle discussion page — Why one-hot-encoding gives worse scores?
In the 2nd plot, tree splits on 98.5, 0, 10.5, 11.5, 88.5 respectively from root to leaf. So this tree is also getting to the right answer and finding splits close to multiple of 11. It is assuming an order in the numbers assigned to categories, which in reality is random assignment. We see that the tree finds it difficult to get to a good decision boundary even for this perfect rule based data. In practice, I have noticed this technique to work well with random forest or gradient boosting techniques as long as cardinality is not high. If cardinality is high numerical encoding is likely to make your computational costs explode before you get any benefit. A workaround to this problem of computational cost is to assign number/rank based on the frequency of that level.
In the 3rd plot, tree with target mean encoding found the perfect division of data in just 1 decision stomp/split. We see that this encoding worked great in our toy example. Let’s dig into this further and limit the scope of this article to target encoding, target leakage/prediction shift, overfitting caused due to this type of encoding; and finally Catboost’s solution to this problem.
Target Encoding
Different types of target encoding
Target encoding is substituting the category of k-th training example with one numeric feature equal to some target statistic (e.g. mean, median or max of target).
- Greedy
- Holdout
- K-fold
- Ordered (the one proposed by Catboost)
Now let’s discuss pros and cons of each of these types.
Greedy target encoding
This is the most straightforward approach. Just substitute the category with the average value of target label over the training examples with the same category. We are only getting to see the labels of the training data. So, we find the mean encoding of all categories from the training data and map as it is to the test data. For the cases where some new category is found in test and not available in training data, we substitute values of that category with overall mean of the target. This works fine as long as we have large amount of training data, categorical features with low cardinality and the target distribution is in training and test data. But this fails to work in the other cases.
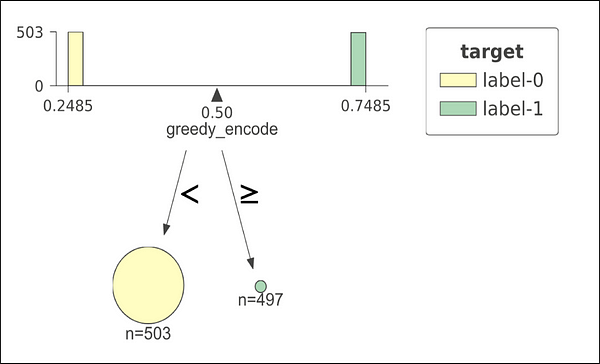
Decision tree on greedy target encoded feature
Let’s look at an extreme example to show failure of this encoding technique. On the left, we see a decision tree plot with perfect split at 0.5 threshold. The training data used for this model has 1000 observations with only one categorical feature having 1000 unique levels. Think of User ID as an example of such unique categorical feature. The labels (0,1) have been assigned randomly to the training data. That means that the target doesn’t have any relationship with the feature. But what decision tree shows us? The tree shows us a perfect split at the very first node, even though in reality the perfect split doesn’t exists. The model will show near perfect score on the training data. Is that true? No. Test data might have new User IDs not seen in training data and our model will suck on the test data. This is the case of “overfitting on the training data”. Later we will solve this issue.
K-fold target encoding
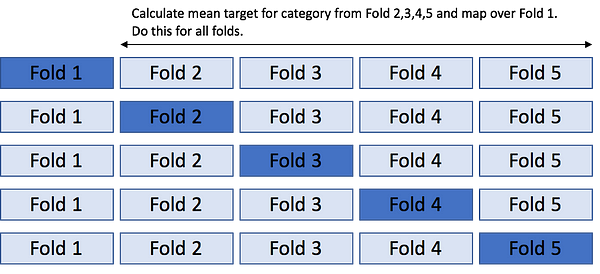
This is the most commonly used approach and solves the issue of overfitting on the training data (“mostly”, not always). The idea is similar to k-fold cross validation. We divide the data in K- stratified or random folds, replace the observations present in M-th fold with mean target of data from all others except M-th fold. We are basically trying to 1) Use all of the training data given to us, 2) Not leak the information from self-target label by allowing target information to flow from other fellow observations (same category but other folds). Most of the times, I personally use this approach with K=5 and so-far it has worked well for small to large datasets.
Holdout target encoding – special case of K-fold when K=2.
Another option is to partition the training dataset into 2 parts. First part to calculate target statistic and the second part to do model training. This way we are not leaking any information from the target of second part which is actually being used for training. But this technique leads to the problem of data reduction as we are basically using less training data than we actually have. With this approach we are not effectively using all the training data we have at our hand. Works when we have large amount of data, still not a great solution though.
Leave one out target encoding – special case of K-fold when K=length of training data.
This is particularly used when we have small dataset. We calculate target statistic for each observation by using labels from all except that particular observation. But this technique can also lead to overfitting in some cases. Let’s see one such failure example using the decision tree visualization.
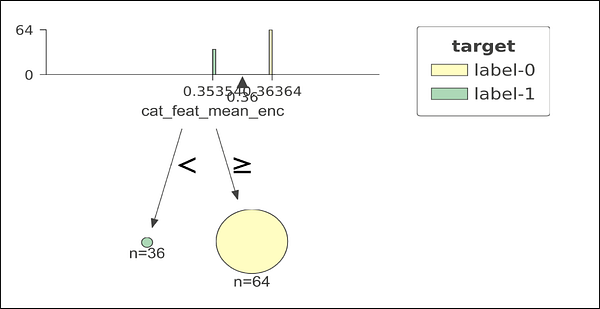
Decision tree on leave one out encoded feature
In this example our training data has 100 observations and only 1 feature; call it color and it is always red. It is obvious that this feature is useless. If we try to fit a decision tree with leave one out encoding on this feature, we might end up with a perfect split of the training data (as shown below). This is misleading as this perfect split doesn’t exists. The reason it gives this split is because when we use leave one out, it either leaves 0 out or leaves 1 out, giving us only two unique encodings. When we train model on this, it uses those two unique values to find perfect split.
Ordered target encoding
This is not a commonly used approach. But this is the core idea behind Catboost library, which works really well for categorical data as shown in thispaper. This technique is motivated from the validation techniques used to handle the time series data. When the distribution of target is not consistent with time, we need to take special care to not leak any information from the future while tuning hyper-parameters. Different ways to do hyper-parameter tuning or splitting validating set in time series data are discussed in this blogpost — Time Series Nested Cross-Validation. The basic idea is to use out of time validation approaches as traditional k-fold methods do not work well in such cases. Similar to that, ordered target encoding relies on the concept of artificial time dependency. We calculate target statistic for each example by only using the target from the history. To generate the proxy concept of time, we randomly shuffle the data. To simplify, we randomize the rows and take running average of target label grouped by each category.
But there is a problem in taking group-wise running averages. For the initial few rows in the randomized data, the mean encoding will have high variance as it only saw a few points from the history. But as it sees more data, the running average starts to get stable. This instability due to randomly chosen initial data points makes the initial part of dataset to have weak estimates. Catboost handles this problem by using more than one random permutations. It trains several models simultaneously, each one is trained on its own permutation. All the models share the same tree forest i.e the same tree structures. But leaf values of these models are different. Before building the next tree, CatBoost selects one of the models, which will be used to select tree structure. The structure is selected using this model, and is then used to calculate leaf values for all the models.
Let’s see if the ordered encoding solves the failure cases we discussed for the leave one out and greedy target encoding techniques.
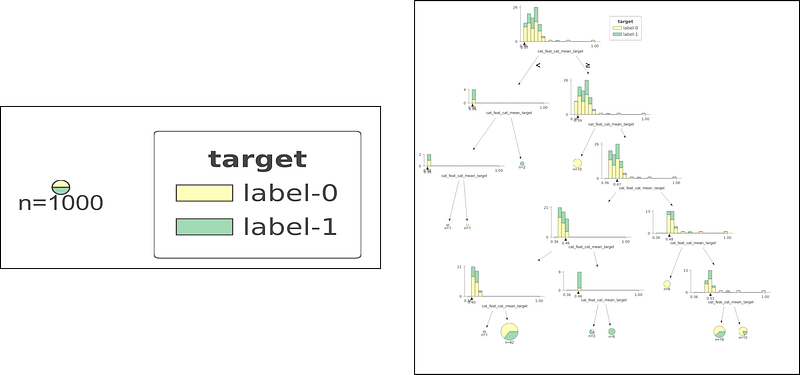
Left: No successful split in case of all unique categories. Right: Decision tree construction for case of all same category.
Case 1 (left plot). When we have all unique categories and greedy approach fails. We see that ordered encoding just can’t simply find any good split at the first place. Case 2 (right plot). When we have all same category. Leave one out fails in this by giving perfect split in the first node. But ordered encoding struggles to find a good model as it should be.
CatBoost also uses ordered target encoding for categorical feature combinations, which is useful for some datasets. The combinations are selected during training in a greedy fashion. We are not discussing the procedure here. But curious readers can read this paper to learn the procedure for combining features.
Leaderboard
Having seen different types of encodings, let’s do some fun stuff. Let’s compare performance of a Random Forest on a couple of datasets for all these encodings and see which comes to the top of the leaderboard. Also adding the performance of Catboost on each dataset.
Below experiments are run on the datasets:
1. Random Forest (500 trees, 10 max_depth) on One Hot Encoded feature
2. Random Forest (500 trees, 10 max_depth) on Numeric Labels
3. Random Forest (500 trees, 10 max_depth) on Hash Encoded feature
4. Random Forest (500 trees, 10 max_depth) on K-fold Target Encoding
5. Random Forest (500 trees, 10 max_depth) on Ordered/Catboost Target Encoding
6. Catboost (500 iterations, 20 early stopping rounds); categorical indexes
Dataset 1.
Simulated dataset with just one categorical feature. 10,000 data points, 100 level cardinality. The feature is creating using random string generator. Each string is of length 5 and 100 such unique strings are generated. These 100 strings are resampled with replacement to give 10,000 data points. Strings starting with vowel have target label 1 and others have target label 0. Around 20% of data has positive labels.
Results
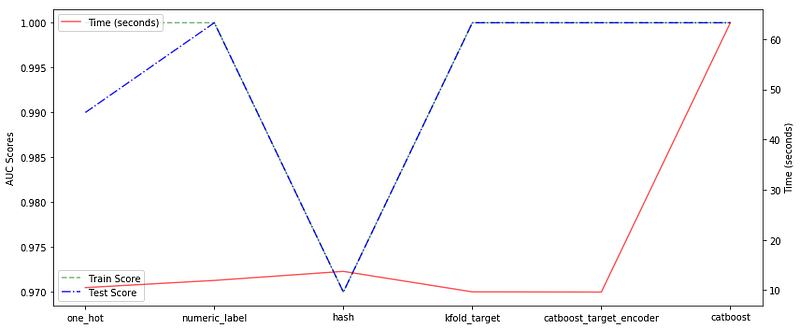
Left to right. 1–5 are categorical encodings on RF. 6 is Catboost GBM.
We see that target encodings and number encodings give perfect scores on test data. The trees in all the cases have been regularized to maximum depth of 10. One hot encoding and hash encodings do not give perfect scores on the test data. The hash encoding must have encountered some collisions and would have put some words starting with vowel in same bucket as words starting with consonants, which is why we see some score reduction. In terms of time, 500 iterations in Catboost take a lot more time as compared to 500 trees of Random Forest. The best way to efficiently use a gradient boosting algorithm is to use early stopping rounds and better learning rate.
Dataset 2.
Kaggle data. Amazon.com — Employee Access Challenge. This dataset has 8 features and all are categorical features with cardinalities ranging from low to high values. (0.2% to 22% unique categories).
Results
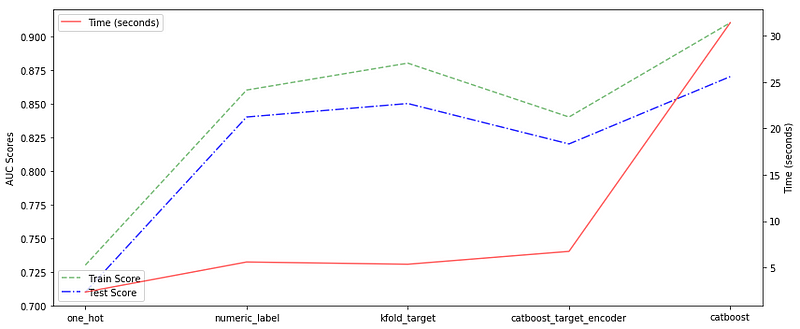
Left to right. 1–4 are categorical encodings on RF. 5 is Catboost GBM.
We see that the catboost outperforms the random forest in terms of performance but is relatively slower. The best random forest model is attained when we used K-fold target encoding, following by number and ordered/catboost target encodings. There is no string type feature in the dataset, so we haven’t used hash encoding. The one hot encoding doesn’t give good performance with fixed depth RF.
Conclusion
By experiments we learnt that in practice, numeric encoded features do pretty well with random forests. Target encoding gives a little bit of improvement on top of numerical encoding. In terms of time efficiency, target encoded features help trees to find solution with much lesser splits. Traditional greedy and leave one out target encodings have a risk of overfitting. Such overfitting
can be solved by either using 5/10-fold target encoding or ordered target encoding. The ordered target encoding introduces an artificial concept of time in data by random permutation of rows. Catboost creates multiple trees with different random permutations to generate a strong model without any target leakage.
Link to code repository
Recommended Readings
- Transforming categorical features to numerical features – Catboost
- Paper that motivated this post: CatBoost: unbiased boosting with categorical features
- Another great post on visualization of trees for categorical features: Visiting: Categorical Features and Encoding in Decision Trees
- Chapter of ML book by Terence Parr and Jeremy Howard: Categorically Speaking
- If don’t know about gradient boosting, read this simple to understand post: Gradient Boosting from scratch
- Let’s Write a Decision Tree Classifier from Scratch — Machine Learning Recipes #8
- One-Hot Encoding is making your Tree-Based Ensembles worse, here’s why?
This article was originally published in TDS.


