Demystifying some of the main concepts and terminologies associated with Reinforcement Learning and their association with other fields of AI
Introduction
Today, Artificial Intelligence (AI) has undergone impressive advancements. AI can be subdivided into three different levels according to the ability of machines to perform intellectual tasks logically and independently:
- Narrow AI: machines are more efficient than humans in performing very specific tasks (but not trying to perform other types of tasks).
- General AI: machines are as intelligent as human beings.
- Strong AI: machines perform better than humans in different ambit (in tasks that we might or not be able to perform at all).
Right now, thanks to Machine Learning, we have been able to achieve good competency at the Narrow AI level. There are three main types of machine learning algorithms used:
- Supervised Learning: using a labelled training set to train a model, to then make predictions on unlabelled data.
- Unsupervised Learning: giving a model an unlabelled data-set, the model has then to try to find patterns in the data to make predictions.
- Reinforcement Learning: training a model trough a reward mechanism to encourage positive behaviours in case of good performance (particularly used in agent-based simulations, gaming and robotics).
Reinforcement Learning, is now considered to be the most promising technique in order to move to the next level in the AI paradigm (Figure 1).
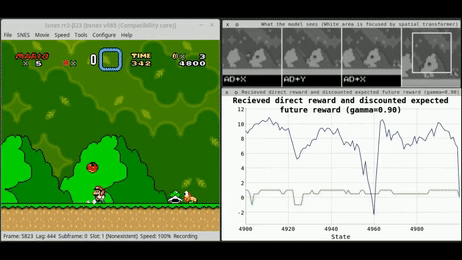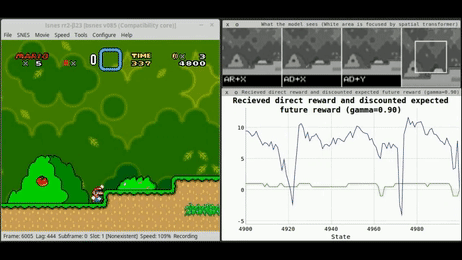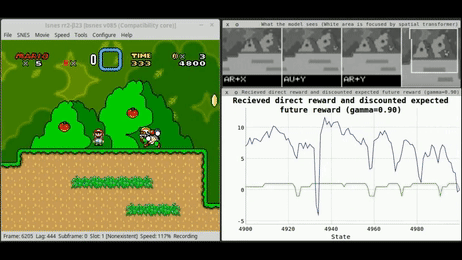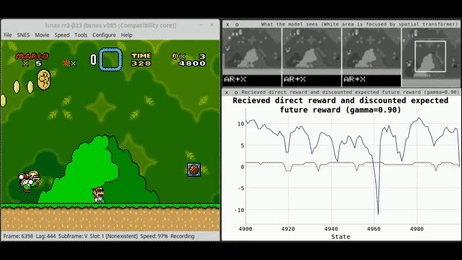
Reinforcement Learning (RL)
One of the reasons why Reinforcement Learning has gained so much interest today, is its interdisciplinarity. The core concepts of this area, follow in fact basic game theory, evolutionary and neuroscience principles.
Compared to all the other forms of Machine Learning, RL can, in fact, be considered to be the closest approximation in trying to replicate how humans and animals learn throughout time.
Reinforcement Learning advocates that the main way which humans most commonly use in order to learn is by using their sensors and interacting with an environment (therefore without necessarily external guidance, like in supervised learning, but by a trial and error process).
On a daily basis, we try to accomplish new tasks and depending on the results of our attempts we affect the environment around us. By assessing our attempts we can then learn through experience to identify which actions gave us greater benefits (and therefore are most convenient to repeat) and which ones should instead be best to avoid. This iterative process is summarized in Figure 2 and represents the main workflow of most Reinforcement Learning based algorithms.
An agent (eg. software bot, robot) is placed in an environment and by interacting with it can learn, receive new stimulus and create new states (eg. unlock a new scenarios or modify the structure of the exstisting ones). Every action of our agent is then associated with a reward value assessing its efficacy towards achieving a predefined goal.
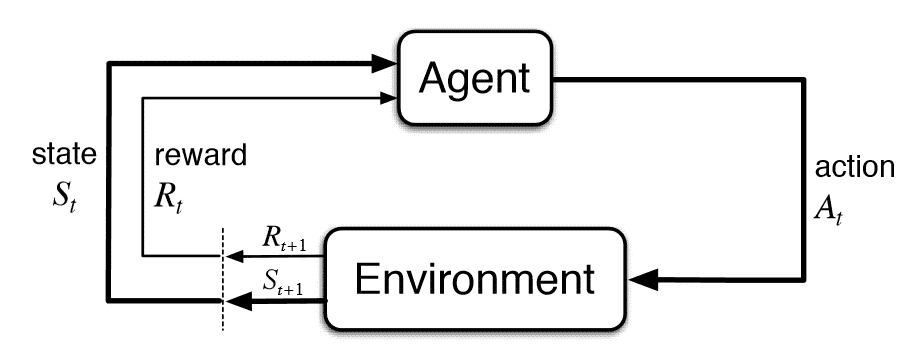
Two main challenges which characterize Reinforcement Learning systems are:
- The exploration-exploitation dilemma: if an agent finds an action which can give him a moderately high reward might be tempted to not try any other available action because afraid it might be less successful. At the same time, if the agent doesn’t even attempt to try a different action it might never find out that better rewards were possible to be achieved.
- Processing of delayed rewards: agents are not told what actions to try, but should instead come up with different solutions, test them and finally evaluate them based on the received reward. Agents should not evaluate their actions just on their immediate rewards. Choosing some type of actions might, in fact, provide greater rewards not immediately but in the long run.
Core Components
According to Richard S. Sutton et al. [3], Reinforcement Learning algorithms are formed by 4 main key components: Policy, Reward, Value Function, Environment Model.
- Policy: defines the agent behaviour (maps the different states to actions). Policies are most likely to be stochastic since each specific action is associated with a probability to be selected.
- Reward: is a signal used to alert the agent how should be best to modify its policy in order to achieve the defined objectives (in the short time period). A reward is received to the agent from the environment each time an action is performed.
- Value Function: is used in order to get a feeling of what actions can bring a greater return in the long run. It works by assigning values to the different states to asses what kind of reward should an agent expect if starting from any specific state.
- Environment Model: simulates the dynamics of the environment the agent is placed in and how the environment should respond to the different actions taken by the agent. Depending on the application, some RL algorithms do not necessarily require an environment model (model-free approach) since they can be approached using a trial-error approach. Although, model-based approaches can enable RL algorithms to tackle more complicated tasks which require planning.
Conclusion
In case you are interested in finding out more about Reinforcement Learning, “Reinforcement Learning: An Introduction” by Richard S. Sutton and Andrew G. Barto and Open AI Gym (as discussed in my next article!) are two great places where to start.
I hope you enjoyed this article, thank you for read



