Lorem ipsum dolor sit amet, consectetur adipiscing elit. Ut elit tellus, luctus nec ullamcorper mattis, pulvinar dapibus leo.
While there have been many articles on new, exciting machine learning algorithms, there isn’t as many on productizing machine learning models. There has been upcoming interest in the engineering of these systems, such as the ScaledML conference, and the birth of MLOps. However, productionizing machine learning models is a skill that is still in short supply.
In my career so far, I’ve gotten a few hard-earned lessons in productionizing machine learning models. Here are some of them.
Build or Buy?
Twitter recently has been all abuzz about GPT-3. Primed with the right seed, it turns out that GPT-3 can generate do many amazing things such as generating buttons on webpages and React code. Spurred by these exciting developments, your stakeholder has an idea: what if you build a GPT-3 equivalent to help speed up the development of the frontend of the company you work at using GPT-3?
Should you train your own GPT-3 model?
Well, no! GPT-3 is a 175 billion parameter model that requires the resources most companies outside of the likes of Google and Microsoft would be hard-pressed to develop. Since OpenAI is trialling a beta for its GPT-3 API, it would be more prudent to try it out, and see if the model solves your use case, and the API scales to your use case.
So then, to buy (more like rent) or build? It depends.
It may look like a cop-out answer, but it is an age-old question in the software industry. It is also such a large and complicated topic, that it deserves a post of its own.
However, here I can offer some guidelines that can help you discuss buying vs. building question with a stakeholder. The first is
Is this use case not a core competence? Is it generic enough for an existing/potential AWS¹ offering?
The underlying principle of this question is to ask yourself if what you’re about to work on is part of the company’s core competence. If your stakeholders can afford it, it may be worth buying an off-the-shelf solution.
Are resources besides data available? E.g., talent and infrastructure?
At its heart, building and deploying a reliable machine learning system is still mostly software engineering, with an added twist: data management. If the team doesn’t have experience building models as service APIs, with collecting, cleaning, labelling and storing data, then the amount of time needed can be prohibitive, say about 1 to 2 years (or even more). Instead, deploying a third party solution could take 3 to 6 months since it’s mostly about integrating the solution into the product. Business owners would find this savings of time and cost extremely attractive.
On the other hand, if it’s related to the company’s core competence, then investing in building up a team that can design and deploy models based on the company’s proprietary data is the better way to go. It allows much more control and understanding of the process, though it does come with a high initial investment overhead.
Just remember
All that matters to a business owner is: how will the output of your model be useful in the context of the business?
Broadly speaking, machine learning is a next step up in automation. So in thinking this way, your model helps to increase revenue, or improves business efficiency by reducing costs.
For instance, integrating a better recommendations system should lead to higher user satisfaction and engagement. Higher satisfaction leads to more subscriptions and organic promotion, which leads to higher revenue and lower churn.
As a data scientist, you have to help the business owner make the best decision on whether to build or buy, and that means assessing the specific pros and cons of either approach in the context of the business.
The points in this article are very useful in approaching the “build vs. buy” question, and it also applies to machine learning production. There’s a case for building it yourself, as argued here, if it is a core business competence.
It all starts from the source
Consider the search results for a user who searched for photos of puppies. Here we have an example from Unsplash, one from Shutterstock, and finally one from EyeEm, this time on a mobile device.
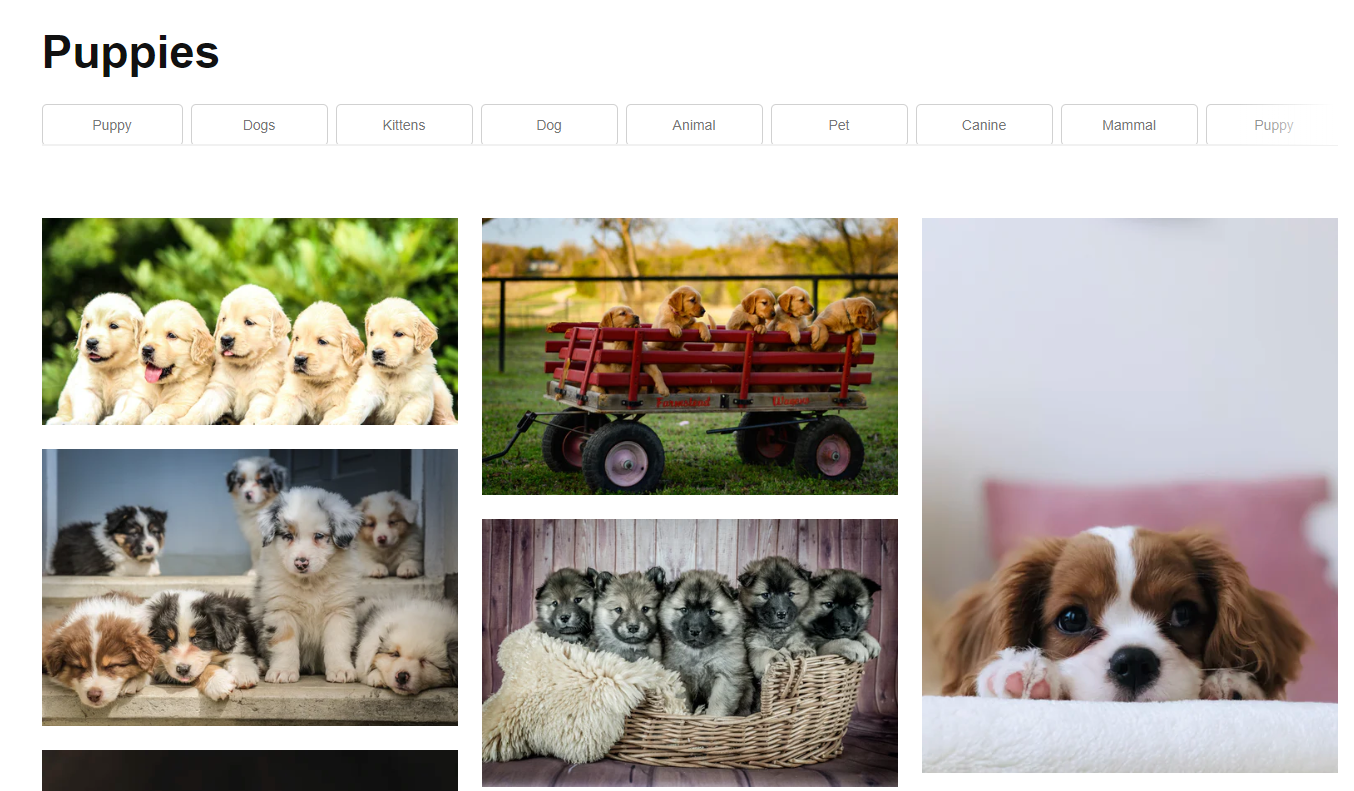
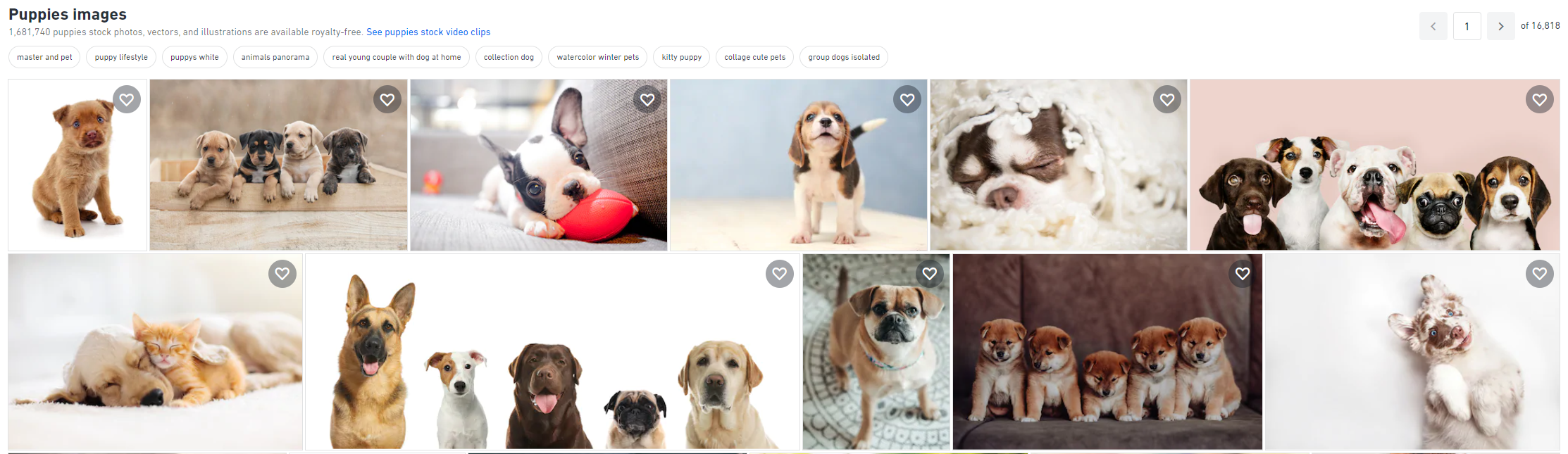

We can see that while each user interface(UI) displays images in a wide selection. Suppose we want to use clicks on the image to train a model that gives better search results.
Which image would you be drawn to first if you were a user?
In the Shutterstock example, you may first be drawn to puppy on the right most side of the window, but in the EyeEm example, it could be the image in the center.
It is clear that there are differences between each UI to cause differences in the distribution of the data collected.
Information retrieval literature has demonstrated that a positional bias² and presentation bias³ exists when displaying results. It is entirely possible for users to click on the first ranked result, even if it’s not relevant to their search query, simply because it’s the first thing they see, and they might be curious about the result!
We can see that the click data used to train search ranking models will have these biases in them, driven by how the UI was designed. So,
Know where and how the model will ultimately be used in the product
A data scientist and machine learning engineer cannot build models in isolation from where the model will ultimately be used. A consequence of this is that a data scientist has to work with all manners of specialties who are involved in the product: the product manager, the designer, the engineers (frontend and backend) and quality assurance engineers.
The cross-functional team work provides benefits, including briefing all team members about the limitations of the model, how that affects UI design and vice versa. Another is to find simple, reliable ways to solve problems, for instance, not solving an inherent UI (and user experience) issue using machine learning. Designers can also come up with ways to make the presentation of results from the model look amazing, as well as constraining user actions in the UI to limit the space of inputs that goes into a model.
A data scientist must build up domain knowledge about the product, including why certain UI decisions were made, and how they can impact your data downstream if product changes are made. The latter point is especially important, since it can mean your model is outdated very quickly when product changes are rolled out.
Moreover, how the results from the model are presented is important so as to minimize bias in future training data, as we shall see next.
Data collection is still challenging
Analytics collection typically depend on engineers setting up analytics events in the services they are responsible for on various parts of the product. Sometimes, analytics are not collected, or collected with noise and bias in them. Analytics events can be dropped, resulting in missing data. Clicks on a button are not debounced, resulting in multiple duplicate events.
Machine learning models are, unfortunately, typically downstream consumers of these analytics data, which means problems with measurements and data collection has a huge impact on the models.
If there’s one thing to remember about data it’s that
Data is merely a byproduct of measurement
This means that it is important to understand where the data is coming from, and how it is being collected. It is also then paramount that measurements are made correctly, with tests on the measurement system conducted periodically to ensure good data quality. It would also be prudent to work with an engineer and a data analyst to understand the issues first-hand because there’s usually a “gotcha” in collected data.
Stored data needs to be encoded to suit the business domain. Let’s take image storage for instance. In most domains, a lossy JPEG image may be fine to encode your stored images, but not in some domains where very high resolution is needed, such as using machine learning for detecting anomalies in MRI scans, for instance. It’s important that these issues be communicated up-front to engineers who are helping you collect the data.
Machine learning in research differs from machine learning in the product in that generally your biggest wins come from better data, not so much better algorithms. There are exceptions, though, such as deep learning improving performance metrics in many areas. Even then, these algorithms are still sensitive to the training data, and you need a whole lot more data.
It is always worth convincing your stakeholder to continually invest in improving the data collection infrastructure. Sometimes, just even a new source of data to construct new features can boost model performance metrics. Not only does it help with better models, it helps with better tracking of the company’s key metrics and product features overall. The data analysts you work with will be very thankful for that.
As an ex-Dropbox data scientist told me recently
Your biggest improvements usually come from sitting down with an engineer to improve analytics
Check your assumptions on the data
Here is one story I experienced first-hand from the trenches.
During the early days of incorporating learning-to-rank models to improve image search at Canva, we planned to use a set of relevance judgments sourced from Mechanical Turk. Canva has a graphic design editor tool that allows a user to search over 50 million images to include into their design.
Basically, what this meant was collected sets of pairwise judgements: for each search term, raters are given a pair of images, one of them which they give a thumbs up to. An example pairwise judgement rating for the term firefly is shown below. Although both are relevant, the image on the left is more preferred by the rater than the image on the right.

We then trained a model using these pairwise judgements, and another model that solely relied on clicks from search logs. The latter has more data, but is of lower quality due to positional bias and errant clicks. Both models look great on offline ranking metrics, and a visual check of the results (i.e., manually, using our eyes).
In online experiments, however, the model that relied on these sourced relevance judgements had a very poor performance, tanking business metrics, compared to the control and the other model.
What happened?
As it turned out, we sourced the judgements without the context of users searching for images to fit their design, not just on pure search relevance alone. This missing context contributed to a dataset that had a different distribution from the data distribution in the product.
Needless to say, we were wrong in our assumption.
Data distribution skew is a very real problem: even the team that implemented the Quick Access functionality in Google Drive at Google faced it⁴. In this case, the distribution of data collected for their development environment did not match the data distribution of the final deployed environment, as the training data was not collected from a production service.
The data used to train your models should match the final environment where your model will be deployed
A sample of other assumptions to check for are
- the appearance of a concept drift, where a significant shift in the data distribution happens (a very recent example is the COVID-19 outbreak messing with prediction models),
- the predictive power of features going into the model as some features decay in predictive power over time, and
- product deprecations, resulting in features disappearing.
These are partially solvable by having monitoring systems in place to check data quality and model performance metrics, as well as flag anomalies. Google has provided an excellent checklist on scoring your current production machine learning system here, including data issues to watch out for.
Remember, if a team at Google, whose maturity in deploying machine learning systems is one of the best in the world, had data assumption problems, you should certainly double-check your assumptions about your training data.
Wrapping it all up
Machine learning systems are very powerful systems. They provide companies with new options in creating new product features, improving existing product features, and improving automation.
However, these systems are still fragile, as there are more considerations about how it’s designed, and how data is collected and used to train models.
I still have more to say on the topic, but these will do for now.
[1] Substitute with your favorite cloud provider.
[2] Thorsten Joachims, Laura Granka, Bing Pan, Helene Hembrooke, and Geri Gay, Accurately Interpreting Clickthrough Data As Implicit Feedback, In Proc. of the 28th Annual International ACM SIGIR Conference on Research and Development in Information Retrieval (SIGIR), pp.154–161 (2005).
[3] Yisong Yue, Rajan Patel, and Hein Roehrig, Beyond Position Bias: Examining Result Attractiveness As a Source of Presentation Bias in Clickthrough Data, In Proc. of the 19th International Conference on World Wide Web (WWW), pp. 1011–1018 (2010).
[4] Sandeep Tata, Alexandrin Popescul, Marc Najork, Mike Colagrosso, Julian Gibbons, Alan Green, Alexandre Mah, Michael Smith, Divanshu Garg, Cayden Meyer, Reuben Kan, Quick Access: Building a Smart Experience for Google Drive, KDD ’17: Proceedings of the 23rd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, pp.1643–1651 (2017)



