Focus on automated decision making instead
Open any large job board and search for “Data Scientist” positions. Many of the returned job specs will contain a requirement to produce data-driven insights that can be used to optimise business processes or products of the hiring organisation. In this context, “insight” is defined as a novel piece of useful information that has been extracted from data using Statistics or Machine Learning techniques. Here are just a few excerpts from the job ads found on LinkedIn:
- “Perform hands-on data analysis and modelling with very large data sets to develop insights into different aspects of our business.”
- “You will define and support the research and analytical process that will deliver rigorous business insights.”
- “Investigate and analyse data to generate insights to support optimisation of business performance and improvement of product development.”
If you are a senior executive planning to hire Data Scientists to perform such tasks for your organisation, I urge you to pause and think again. Chances are, this initiative will not yield the return on investment you are hoping for. To understand why this is so, try to honestly answer the following questions (I provide brief comments for each of these questions to clarify what they mean).
What if modern Business Intelligence is all you actually need?
Although both Business Intelligence (BI) and Data Science experts work with data to extract useful information, there are fundamental differences between these two disciplines. Most importantly, a typical BI project starts from a set of predefined KPIs that business users are already familiar with and then generates a descriptive report on what already happened to those KPIs in the past. In contrast, Data Scientists work on questions that have not been answered before. They strive to uncover hidden patterns in data and extract new knowledge that can then be used to either prescribe new ways for the business to operate or predict how it will develop in the future.
It turns out, however, that certain tasks that would traditionally require input from Data Scientists can now be solved using modern BI tools. For example, users of Microsoft PowerBI can create complex dataflows in a self-service manner and then build Machine Learning-based predictive models without writing a single line of code. PowerBI also offers a range of “cognitive services” that can help analysts enrich their data with additional features, such as text sentiment scores, image tags, etc.
Machine Learning capabilities offered by modern BI tools may well be all that your organisation needs to produce rich data-driven insights. Moreover, BI is already part of culture and mindset in most of the organisations, making it much easier to embed these new capabilities into the existing process of decision making. Thus, instead of hiring a separate team of Data Scientists to perform what could potentially become “BI-on-steroids”, it may make more sense to invest in the existing BI infrastructure and teams.
Is your infrastructure Data Science-friendly?
But let us assume that hiring Data Scientists is still deemed necessary. Then it becomes crucial to understand the respective infrastructural and financial implications.
For example, your company may well be collecting terabytes or even petabytes of data (and you probably even listed this fact in the job spec as one of the advantages of working for your company). Unfortunately, that does not automatically mean that these data are ready for Data Scientists to work with. There is a slim chance of producing valuable insights from data that are:
- sitting in disparate and inaccessible source systems;
- poorly documented;
- too aggregated to be useful in Data Science projects;
- inconsistent or of low quality.
To run their analyses, Data Scientists will require a dedicated compute environment (e.g., a cluster of computers in the cloud). The organisation has to be ready to invest in such an environment and its IT support. Moreover, Data Scientists should be able to easily install specialised software packages that they need to work with in that environment. This implies the existence of proper access permissions and connectivity to internal and, potentially, external software repositories.
Similar to software developers, Data Scientists write code. In line with modern best practices, this code has to be version-controlled and stored in a remote repository. The IT department will have to set up and maintain such a version control system.
Insights and models produced by Data Scientists are commonly delivered in the form of interactive reports and web applications. These applications are to be hosted in their own dedicated environment. Once again, the IT department will have to set up and maintain such an environment and implement access permission rules for the application end-users.
Given the crucial role of IT specialists in providing a secure and efficient infrastructure for analytical work, they have to be comfortable with Data Science concepts and tools (which are typically opensource). This implies additional investment in training and upskilling of the IT teams.
Many of the above-mentioned technical requirements can be satisfied by a commercially offered Data Science platform (e.g., RStudio Connect, Dataiku, Domino Data Lab, DataRobot, etc.). However, such platforms are not cheap, and the organisation would have to thoroughly evaluate the economy of licensing one of them vs using in-house solutions. And, of course, the organisation has to be aware of the potential lock-in posed by adhering to any specific technology long-term.
Data Science projects take time. Are you willing to wait?
The key term in “Data Science” is… “science”. Among many other things, this implies that Data Science projects take time. This is true even for organisations that have managed to remove the infrastructural hurdles described above.
There is a good reason why the average time it takes to develop and release a new prescription drug is ca. 12 years. This science-heavy process consists of several laborious and often iterative steps. For instance, 5,000–10,000 compounds have to be screened in the initial experiments in order to find a promising drug candidate. And then it takes years to run preclinical and clinical trials to prove the new drug’s efficacy and safety. These trials can easily conclude that the proposed drug is not safe, cancelling all the previous development efforts.
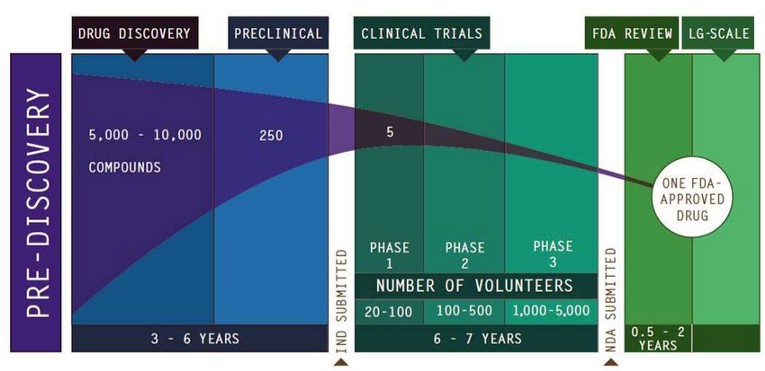
In many aspects, Data Science projects resemble this drug development cycle (although they definitely do not take 12 years to complete! — a few weeks to a few months is a more common timeframe). At the beginning of a project, Data Scientists are likely to spend a lot of time and effort finding the right data for the problem at hand, sorting out access permissions and data governance approvals, preparing the data for analysis, and eventually building and fine-tuning many candidate models. Once a good model is found, the results are presented to the business stakeholders, who may ask for further refinements. Data Science is highly iterative.
However, even if the final result does meet all the expectations, it may be too late: the organisation may have already found a simpler (and most likely subpar) solution to the original problem. Or the priorities might have changed altogether. Thus, investing in insight-generating Data Science projects is a risky thing to do and should only be undertaken if the expected outcome is clearly worth it.
Can your organisational culture execute on data-driven insights?
Insights produced by Data Scientists often suggest changing the existing business processes. Although many organisations claim that these are precisely the kind of recommendations they expect from their Data Scientists, in reality only a few organisations manage to introduce such changes. The main reasons for this are usually as follows:
- lack of a data-driven culture;
- internal politics and resistance from the affected teams, who feel threatened by the proposed optimisations;
- inefficient and slow IT and data governance processes;
- infrastructural hurdles (as outlined above, but also lack of a solid test-and-learn framework);
- lack of dedicated funding;
- bureaucracy.
These reasons are not specific for Data Science activities: they also plague other initiatives, especially in big non-tech companies and government departments. In theory, this could be remedied if senior executives started leading by example and actively helping the change happen. Unfortunately, this is rarely observed in the Data Science space due to a poor understanding among executives of what Data Science is in the first place, what it can deliver, and how its deliverables can be embedded into business processes and product development.
Lack of a data-driven culture is, to a great extent, driven by poor data literacy among employees. Wikipedia defines data literacy as “the ability to read, understand, create and communicate data as information”. A data-literate person is someone who can, for example, read a graph and correctly interpret it. However, successfully executing on the insights produced by Data Scientists requires more than that: one has to also understand the main concepts of Statistics, predictive analytics, design of experiment, etc. Otherwise, attempts to embed Data Science-generated insights into business processes can do more harm than good.
Imagine, for example, that your Data Science team found a strong positive relationship between the number of times customers log in to an online shop and the number of purchases they make. It can be tempting to run a CRM campaign that incentivises customers to log in more often (e.g., by offering them Amazon vouchers). However, such a campaign is almost guaranteed to become a waste of money and effort. The reason is that the relationship found by Data Scientists is just a correlation: it does not describe a truly mechanistic link between the number of logins and the number of purchases. In fact, high-purchasers already want to buy and to make a purchase they have to log in. But simply nudging low-purchasers to log in more often is very unlikely to make them want to buy. You can find a more detailed discussion on this topic in my previous article: So, your stakeholders want an interpretable Machine Learning model?
Conclusion: focus on automated decisions making
By now, you might have started thinking that investing in Data Science is a hopeless endeavour. However, this is not the message I am trying to convey. What I am saying is that organisations need to clearly understand the risks and evaluate requirements before investing in a Data Science team that is expected to mainly develop data-driven insights. Unless you are Google, Facebook, Netflix or Amazon and can afford working on risky R&D projects, you may be better off investing in a different flavour of Data Science — the one that builds intelligent systems for automated decisions making.
The harsh reality is such that producing data-driven insights and then embedding them into business processes involves too many people with their own agendas and varying data-literacy skills, and thus too many potential points of failure. However, if a business process requires repeated decision making based on the same type of input data, it can and should be automated. Examples of this kind of decisions are countless: product recommendations, loan and pricing decisions, email spam classification, image recognition, text sentiment analysis, etc. This is where Data Science and Machine Learning really shine.
Building systems for automated decision making incurs a whole new set of requirements, both in terms of the technology stack and personnel skills. However, investing in Data Science and engineering teams that can build such systems has a much better chance to succeed.



