Let’s face it — forgetting things sucks. It’s frustrating not to remember where you left your keys or to stumble over your words because you can’t recall the name of that colleague you just ran into at the grocery store. However, forgetfulness is core to the human condition, and in fact, we’re lucky that we’re able to do so.
For humans, forgetting is more than just a failure to remember; it’s an active process that helps the brain take in new information and make decisions more effectively.
Now, data scientists are applying neuroscience principles to improve machine learning, convinced that human brains may hold the key to unlocking Turing complete artificial intelligence.
According to a recent paper in Neuron, our brains are meant to act as information filters. Put in a big pile of messy data, filter for the useful bits, then clear out any irrelevant details in order to tell a story or make a decision. The unused pieces are deleted in order to make space for new data — like running a disk cleanup on a computer. In neurobiology terms, forgetting happens when synaptic connections between neurons weaken or are eliminated over time, and as new neurons develop, they rewire the circuits of the hippocampus, overwriting existing memories (New Atlas).
For humans, forgetting has two benefits:
- It enhances flexibility by reducing the influence of outdated information on our decision-making
- It prevents overfitting to specific past events, promoting generalizations (Neuron)
In order to adapt effectively, humans need to be able to strategically forget.
But what about computers?
Herein lies one of the big challenges for artificial intelligence — computers forget differently than humans. Deep neural networks are the most successful technique for a range of machine learning tasks, but they don’t forget like we do.
Let’s take a simplified example- if you teach a child that speaks English to learn Spanish, the child will use relevant clues from learning English to apply it to Spanish —perhaps nouns, verb-tenses, sentence building — and simultaneously forget the parts that aren’t pertinent— think accents, mumbling, intonation. The child can incrementally learn and build while strategically forgetting.
In contrast, if a neural network is trained to learn English, the parameters are adapted to solve for English. If then, you’d like to teach it Spanish, new adaptations for Spanish will overwrite the knowledge that the neural network previously acquired for English, effectively deleting everything and starting anew. This is called ‘catastrophic forgetting’, and “it’s one of the fundamental limitations of neural networks” (Deep Mind).
While it’s still new territory, scientists have made strides recently to explore a few potential theories on how to overcome this limitation.
Teaching AI to Strategically Forget: Three Approaches
#1. Long Short Term Memory Networks (LSTM)
LSTMs are a type of recurrent neural network that use specific learning mechanisms to decide which pieces of information to remember, which to update, and which to pay attention to”(Edwin Chen) at any point.
It’s easiest to explain how LSTMs work by using a movie analogy: Imagine that a computer is trying to predict what will happen next in a movie by analyzing previous scenes. In one scene, a woman holds a knife — does the computer guess she’s a chef or a murderer? In another, the woman and a man are eating sushi under an golden archway — are they in Japan or at McDonalds? Maybe it’s actually St. Louis?
Pretty difficult to predict.
LSTMs aid in this process by helping a neural network 1) forget/remember, 2) save and 3) focus:
- Forget/Remember: “If a scene ends, for example, the model should forget the current scene location, the time of day, and reset any scene-specific information; however, if a character dies in the scene, it should continue remembering that he’s no longer alive. Thus, we want the model to learn a separate forgetting/remembering mechanism: when new inputs come in, it needs to know which beliefs to keep or throw away.” (Edwin Chen)
- Save: When the model sees a new image, it needs to learn whether any information about the image is worth using and saving. If the woman walks past a billboard in a certain scene — will it be important to remember the billboard or is it simply noise?
- Focus: We need to remember that the woman in the movie is a mother, because we will see her children later on, but it is perhaps not important in a scene that she isn’t in, so we don’t need to focus on it during that scene. In the same way, not everything stored in the neural network’s long term memory is immediately relevant, so the LSTM helps to determine which parts to focus on at any given time while keeping everything safely stored for later.
#2. Elastic Weight Consolidation (EWC)
EWC is an algorithm created in March 2017 by researchers at Google’s DeepMind that mimics a neuroscience processes called synaptic consolidation. During synaptic consolidation, our brains assess a task, compute the importance of many neurons used to perform the task, weighing some neurons as more critical to performing the task correctly. These critical neurons are coded as important and are less likely to be overwritten in subsequent tasks. Similarly, in neural networks, multiple connections (like neurons) are used to perform a task. EWC codes some connections as critical and thus protects them from being overwritten/forgotten.
In the chart below, you can see what happened when the researchers applied EWC to a game of Atari — the blue line is a standard deep learning process, and the red and brown lines are aided by EWC:
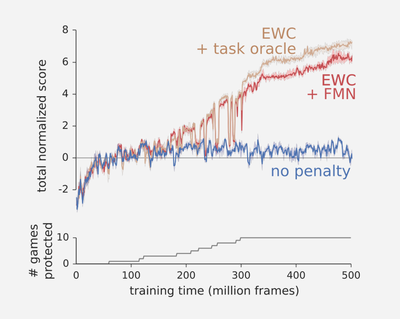
blue line = standard deep learning, red & brown lines = improvements with the help of EWC
#3. Bottleneck Theory
In the Fall of 2017, the AI community was humming over a talk by Naftali Tishby, a computer scientist and neuroscientist from the Hebrew University of Jerusalem and evidence for what he called The Bottleneck Theory. “The idea is that a network rids noisy input data of extraneous details as if by squeezing the information through a bottleneck, retaining only the features most relevant to general concepts” (Quanta).
As Tishby explains it, neural networks go through two phases while learning — fitting and compressing. During fitting, the network labels its training data, and during compression, a much longer process, it “sheds information about the data, keeping track of only the strongest features” (Qanta) — those will be most relevant to helping it generalize. In this way, compressing is a way of strategically forgetting, and manipulating this bottleneck could be a tool AI researchers use to to construct new objectives and architectures of stronger neural networks in the future.
As Tishby says, “the most important part of learning is actually forgetting.”
It’s possible that our brains and distinctly human processes, like forgetting, hold the map to creating strong artificial intelligence, but scientists are collectively still figuring out how to read the directions.


