
Attention mechanisms have greatly helped accelerate the progress in deep learning [1] [2]. Although initially developed for language, Attention has become a popular technique in several domains such as Vision and RL. In this series of articles, we will briefly review the concept of attention and discuss some of the works that have applied attention in visual tasks.
Intuition:
The ability of a species to quickly process information and respond to environmental changes greatly determines the chances of its survival [3] [4] [5]. Although our brain can perform complex tasks, it is limited by the amount of computation it can perform. In fact, our vision system is capable of processing less than 1% of the input data (Wikipedia). Our ability to pay attention to important aspects of the input data compensates for this bottleneck and helps us in performing complex tasks efficiently.
Inspired by the biological concept of attention, a similar technique is used in deep learning models. It enables the model to assign higher importance to certain aspects of the input signal while generating the output. The concept of attention has played an important role in designing models that have achieved or sometimes outperformed human-level performance in complex learning tasks in vision and language. In this article, we will review the concept of attention, specifically self-attention, and its adoption in visual tasks.
Attention:
Bahdanau et al. introduced the attention mechanism for Neural Machine Translation (NMT)[6]. It enabled the RNN models to better represent long-range dependencies in the input sequence. Inspired by its success, variants of attention techniques were developed and successfully applied to language and image tasks. Refer to this excellent blog by Lilian Weng for more details on the evolution of attention mechanisms [7].
Attention models usually learn the attention weights by aligning the input and output sequence representations. The technique is called self-attention if the same input sequence is used instead of the output sequence, for computing the alignment scores. Vaswani et al. used self-attention in the encoder of the transformer model to generate useful representations of the input sequences, which was later used for downstream tasks such as translation [8].
How does self-attention work?
The attention mechanisms is analogous to how an information retrieval system works. The data in a database usually exists in the form of Key-Value pairs to enable faster retrieval. A query is compared against each key in the database and the value corresponding to the matching key is returned.
In self-attention, Query(Q), Key(K), and Value(V) are vectors obtained by applying transformations on the input sequence. The output of the attention layer is calculated as the weighted sum of the values. The weights(W) assigned to the values are calculated by comparing the query and the key vectors. The concept of self-attention is discussed in great detail here [9].
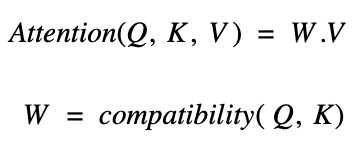
The compatibility scores are calculated as a dot-product between Query and Key vectors. The result is scaled by a factor of 1/√dk to limit the magnitude of the dot product from growing extremely large for large inputs. A softmax is applied to normalize the output values.
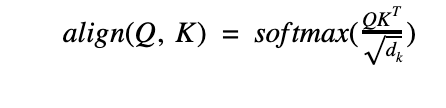
Vaswani et al. discussed three major advantages of self-attention layers over traditional sequential networks:
- The computation complexity per layer is drastically reduced compared to the traditional sequential networks.
- Unlike RNNs, several computations can be parallelized in the attention layer, offering a way to scale them up for larger datasets.
- Due to its reduced complexity and parallelizable structure, the path length between the positions in input and output sequences is reduced. This helps the model to learn the long-range dependencies easier than the sequential networks where the signals/cues could easily be lost while passing through several layers.
Due to these advantages, attention-based models such as Transformers have clearly outperformed other architectures such as RNNs in various language tasks. Although they are particularly efficient in learning sequences (text), they have also been successful in the Image domain. We will review some of the approaches in vision in the following article and discuss the challenges in applying attention to Vision.
[1] S. Chaudhari and R. Ramanath, “An Attentive Survey of Attention Models; An Attentive Survey of Attention Models,” ACM Trans. Intell. Syst. Technol. 1, 1, Artic., vol. 1, p. 33, 2021, doi: 10.1145/3465055.
[2] A. de S. Correia and E. L. Colombini, “Attention, please! A survey of Neural Attention Models in Deep Learning,” Mar. 2021, Accessed: Sep. 19, 2021. [Online]. Available: https://arxiv.org/abs/2103.16775v1.
[3] M. EM and B. JJ, “The evolution of intelligence: adaptive specializations versus general process,” Biol. Rev. Camb. Philos. Soc., vol. 76, no. 3, pp. 341–364, 2001, DOI: 10.1017/S146479310100570X.
[4] R. G and D. U, “Evolution of the brain and intelligence in primates,” Prog. Brain Res., vol. 195, pp. 413–430, 2012, DOI: 10.1016/B978-0-444-53860-4.00020-9.
[5] M. A. Hofman, “Evolution of the human brain: when bigger is better,” Front. Neuroanat., vol. 8, no. MAR, Mar. 2014, DOI: 10.3389/FNANA.2014.00015.
[6] D. Bahdanau, K. Cho, and Y. Bengio, “Neural Machine Translation by Jointly Learning to Align and Translate,” 3rd Int. Conf. Learn. Represent. ICLR 2015 – Conf. Track Proc., Sep. 2014, Accessed: Sep. 19, 2021. [Online]. Available: https://arxiv.org/abs/1409.0473v7.
[7] “Attention? Attention!” https://lilianweng.github.io/lil-log/2018/06/24/attention-attention.html (accessed Sep. 19, 2021).
[8] A. Vaswani et al., “Attention is all you need,” in Advances in Neural Information Processing Systems, 2017, vol. 2017-December, pp. 5999–6009.
[9] “The Illustrated Transformer – Jay Alammar – Visualizing machine learning one concept at a time.” https://jalammar.github.io/illustrated-transformer/ (accessed Sep. 19, 2021).



