Ready to learn Machine Learning? Browse courses like Machine Learning Foundations: Supervised Learning developed by industry thought leaders and Experfy in Harvard Innovation Lab.
Many of us frown upon the technical debt but generally, it is not a bad thing. Technical debt is an instrument which is justified when we need to meet some release deadlines or unblock a colleague. The problem with the technical debt though is the same as with the financial debt — when the time comes to pay the debt we give back more than we took at the beginning. That is because the technical debt has a compound effect.
Experienced teams know when to back up seeing a piling debt, but technical debt in machine learning piles extremely fast. You can create months worth of debt in a matter of one working day and even the most experienced teams can miss a moment when the debt is so huge that it sets them back for half a year, which is often enough to kill a fast-pacing project.
Here are three fantastic papers that explore this issue:
Machine Learning: The High Interest Credit Card of Technical Debt NIPS’14
Hidden Technical Debt in Machine Learning Systems NIPS’15
What’s your ML test score? NIPS’16
These papers categorize and present dozens of machine learning anti-patterns that can slowly creep into your infrastructure creating a time bomb. Here I discuss only three anti-patterns that wake me up at night in a cold sweat and I will leave the rest to the reader.
Feedback Loops
Feedback loops happen when the output of the ML model is indirectly fed into its own input. Sounds like something which is easy to avoid but it is actually not in practice. There are multiple variations of feedback loops and NIPS’14 paper gives a great example but I will give the one which is more real-lify.
Example
Let us say your company has a shopping website. A backend team comes up with a recommender system which decides whether to show a pop-up notification with an offer based on the customer’s profile and the history of past purchases. Naturally, you want to train your recommender system based on the previously clicked or ignored pop-up notifications, which is not a feedback loop, yet. You launch this feature and rejoice as the fraction of clicked notifications slowly grows week-over-week. You explain this growth with an ability of AI to improve on its past performance 🙂 What you didn’t know though is that the front-end team implemented a fixed threshold which hides pop-up notification if the confidence of a recommended offer is less than 50%, because obviously, they do not want to show potentially bad offers to the customers. As the time passes, the recommendations that would previously be in the 50–60% confidence range are now inferred with the <50% confidence, leaving only the most potent recommendations in the 50–100% bracket. That is a feedback loop — your metric grows but the quality of the system does not improve. Morale: you should not only exploit the ML system but also allow it to explore — get rid of the fixed threshold.
In small companies, it is relatively easy to control the feedback loops, but in large companies with dozens of teams working on dozens of complex systems piped into each other some of the feedback loops are very likely to be missed.
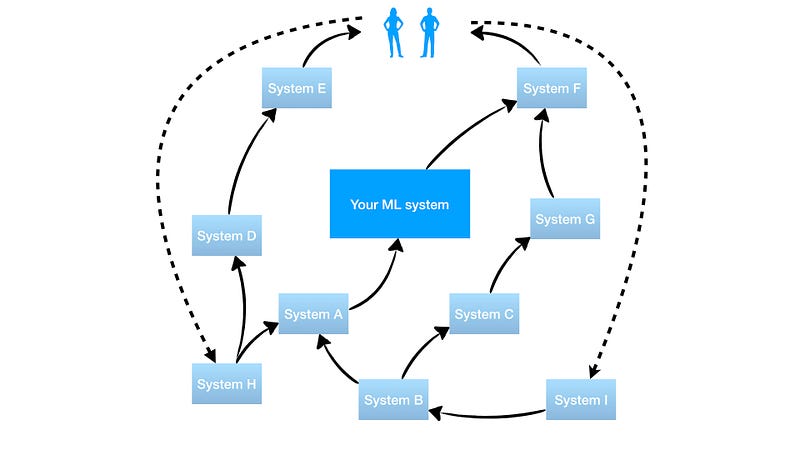
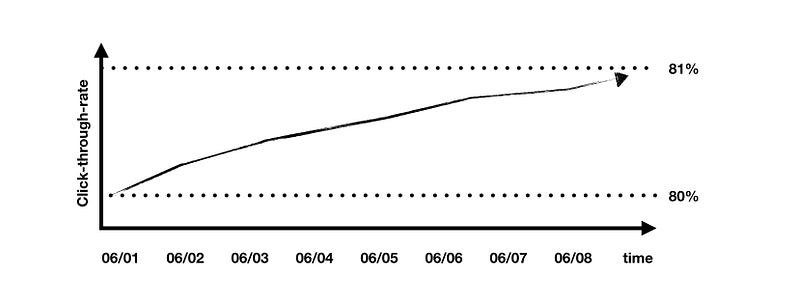
Feedback loops can be smelled if you notice that some of your metrics slowly drift upwards with the time even when there are no launches. Finding and fixing the loop is a much harder problem since it involves a directed cross-team effort.
Correction Cascades
Correction cascades happen when the ML model does not learn the thing that you want it to learn and you end up applying a hotfix on the output of the ML model. As the hotfixes pile-up you end up with a thick layer of heuristics on the top of the ML model which is called a correction cascade. Correction cascades are extremely tempting even in the absence of time pressure. It is easy to apply a filter to the output of the ML system in order to take care of some rare special cases that ML does not want to learn.
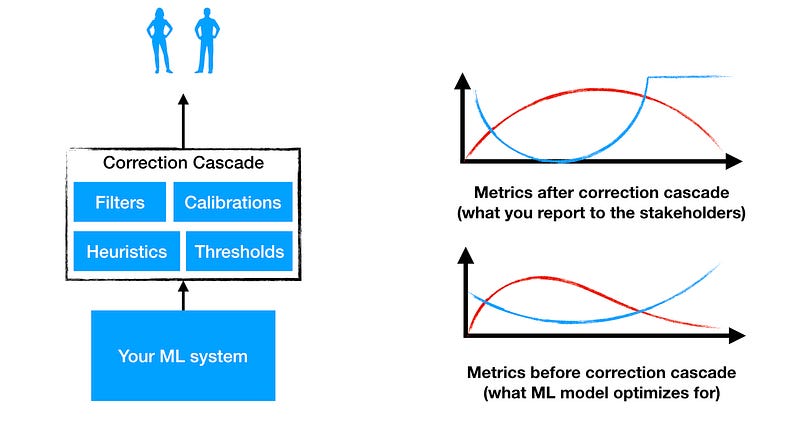
Correction cascades decorrelate the metrics that your ML model tries to optimize while training from the overall metrics of the entire system. As this layer grows thicker you can no longer figure out what changes to the ML model would improve the final metrics that you present to your boss and you end up not being able to deliver the new improvements.
Hobo-features
Hobo-features are features that do nothing useful in your ML system and you cannot get rid of them. There are three types of hobo-features:
Bundled features
Sometimes when we have a group of new features you evaluate them together and if found beneficial submit the entire bundle. Unfortunately, only some of the features in the bundle can be useful while other features are dragging it down.
ε-Features
It is tempting to sometimes add a feature even when the quality increase is very minor. Such features, however, may become neutral or negative in a week if the underlying data drifts a bit.
Legacy features
As times goes on, we add new features to a project and never reevaluate them again. In a couple of months, some of these features may become totally useless or superseded by the new features.
In a complex ML system, the only way to efficiently weed out the hobo-features is to try pruning them one at a time. Meaning, you remove one feature at a time, train the ML system, and evaluate it using your metrics. If the system takes 1 day to train, we can run at most 5 trainings at a time, and we have 500 features, then pruning all of them will take us 100 days. Unfortunately features may interact which means you have to try pruning all possible subsets of features, which becomes an exponentially hard problem.
With Our Powers Combined
Having all three anti-patterns in your machine learning infrastructure can be an instakill to the entire project.
With the feedback loops, your metrics won’t reflect the real quality of the system and your ML model will learn to exploit these feedback loops instead of learning useful things. Additionally, as the time goes your model may be unintentionally shaped by the engineering team to exploit these loops even more.
The correction cascades will loosen correlation between the metrics measured directly on the ML model and a system as a whole. You will end up in a situation where positive improvements to the ML model have a random effect on the metrics of the overall system.
With hobo-features you won’t even know which of your hundreds of features actually carry the useful information and it will be too expensive to prune them. On a daily basis, the metrics that you commonly monitor will randomly jump up or drop down because some of the garbage features will randomly seizure. And no, regularization helps just a little bit.
You end up with the project where the metrics randomly jump up or down, do not reflect the actual quality, and you are not able to improve them. The only way out would be to rewrite the entire project from the scratch. That is when you know — you shot yourself in the foot with a bazooka.


