How the new advances in semantics and the data fabric can help us be better at Machine Learning. Also, a new definition of machine learning.
Introduction
If you search for machine learning online you’ll find around 2,050,000,000 results. Yeah for real. It’s not easy to find that description or definition that fits every use or case, but there are amazing ones. Here I’ll propose a different definition of machine learning, focusing on a new paradigm, the data fabric.
Objectives
General
Explain the data fabric connection with machine learning.
Specifics
- Give a description of the data fabric and ecosystems to create it.
- Explain in a few words what is machine learning.
- Propose a way of visualizing machine learning insights inside of the data fabric.
Main theory
If we can construct a data fabric that supports all the data in the company, then a business insight inside of it can be thought as a dent in it. The automatic process of discovering what that insight is, it’s called machine learning.
Section 1. What is the Data Fabric?

I’ve talked before about the data fabric, and I gave a definition of it (I’ll put it here again bellow).
There are several words we should mention when we talk about the data fabric: graphs, knowledge-graph, ontology, semantics, linked-data. Read the article from above if you want those definitions; and then we can say that:
The Data Fabric is the platform that supports all the data in the company. How it’s managed, described, combined and universally accessed. This platform is formed from an Enterprise Knowledge Graph to create an uniform and unified data environment.
Let’s break that definition in parts. The first thing we need it’s a knowledge graph.
The knowledge graph consists in integrated collections of data and information that also contains huge numbers of links between different data. The key here is that instead of looking for possible answers, under this new model we’re seeking an answer. We want the facts — where those facts come from is less important. The data here can represent concepts, objects, things, people and actually whatever you have in mind. The graph fills in the relationships, the connections between the concepts.
Knowledge graphs also allow you to create structures for the relationships in the graph. With it, it’s possible to set up a framework to study data and its relation to other data (remember ontology?).
In this context we can ask this question to our data lake:
What exists here?
The concept of the data lake it’s important too because we need a place to store our data, govern it and run our jobs. But we need a smart data lake, a place that understand what we have and how to use it, that’s one of the benefits of having a data fabric.
The data fabric should be uniform and unified, meaning that we should make an effort in being able to organize all the data in the organization in one place and really manage and govern it.
Section 2. What is Machine Learning?
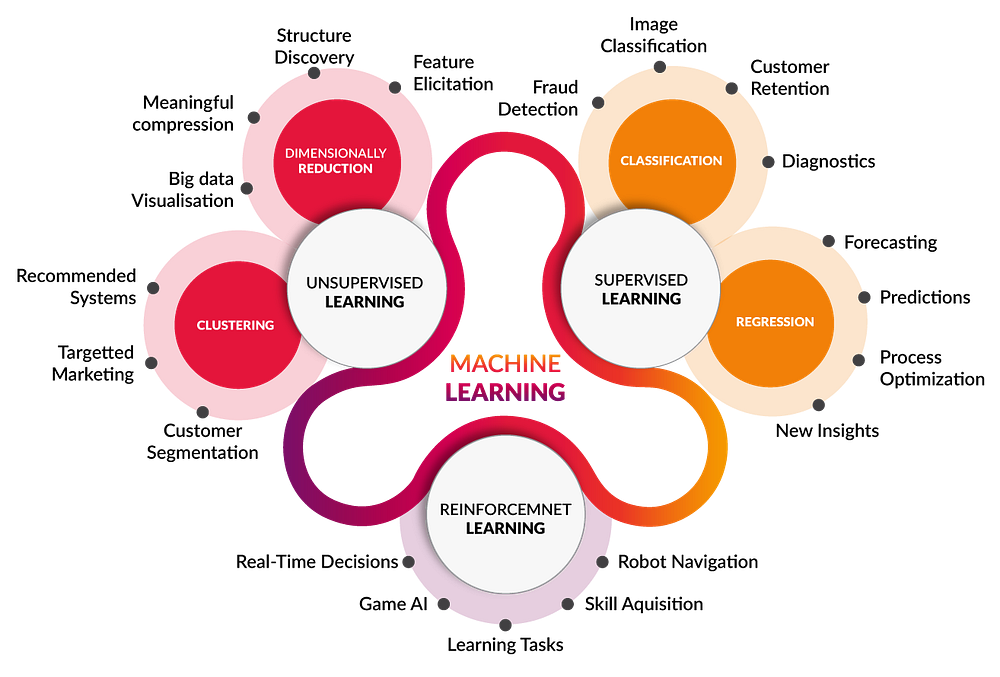
Machine Learning has been around for a while now. There are great descriptions, books, articles and blogs about it so I’m not going to bore you with 10 paragraphs on what is it.
I just want to make some points clear.
Machine Learning is not magic.
Ok after that, let me give a kinda borrowed and personalized definition of machine learning:
Machine learning is the automatic process of understanding patterns in data and some data representations by using algorithms that are able to extract those patters without being specifically programmed for that, to create models that solves a particular (or multiple) problem(s).
You can agree with this definition or not, there are great ones in the literature right now, I just think this one it’s simple and useful for what I want to express.
Section 3. Doing Machine Learning in the Data Fabric

In Einstein theory of gravity (General Relativity) he proposed mathematically that mass can deform space-time, and that deformation is what we understand as gravity. I know that if you are not familiar with the theory it can sound weird. Let me try to explain it.
In the “flat” space-time of special relativity, where gravity is absent, the laws of mechanics take on an especially simple form: As long as no external force is acting on an object, it will move on a straight line through space-time: at a constant velocity along a straight path (Newton’s first law of mechanics).
But when we have mass and acceleration we can say we are in the presence of gravity. Like Wheeler said:
Spacetime tells matter how to move; matter tells spacetime how to curve.
In the image above the “cubes” are a representation of the space-time fabric, and when mass move within it, it deforms it, the way the “lines” move would tell us how a near object will behave close to that one. So gravity is something like:
So when we have mass we can make a “dent” in space-time, and after that what we see when we are close to that dent, is gravity. We have to be close enough to the object to feel it.
That’s exactly what I’m proposing what machine learning can be in the data fabric. I know I sound crazy. Let me explain myself.
Let’s say we have created a data fabric. For me the best tool out there for me is Anzo as I mentioned in other articles.

https://www.cambridgesemantics.com/
You can build something called “The Enterprise Knowledge Graph” with Anzo, and of course create your data fabric.
The nodes and edges of the graph flexibly capture a high-resolution twin of every data source — structured or unstructured. The graph can help users answer any question quickly and interactively, allowing users to converse with the data to uncover insights.
By the way, this is how I’m picturing an insight:

Image by Héizel Vázquez
If we have the data fabric:

Image by Héizel Vázquez
what I’m proposing is that an insight can be thought as a dent in it. And the automatic process of discovering what that insight is, it’s machine learning.

Image by Héizel Vázquez
So now we can say:
Machine learning is the automatic process of discovering hidden insights in data fabric by using algorithms that are able to find those insights without being specifically programmed for that, to create models that solves a particular (or multiple) problem(s).
Insights generated with the fabric are themselves new data that becomes explicit/manifest as part of the fabric. i.e. Insights can grow the graph, potentially yielding further insights.
In the data fabric we come with a problem, trying to find those hidden insights in the data, and then using machine learning we can discover them. How would this look in real life?
The people at Cambridge Semantics has the answer with Anzo too. The Anzo for Machine Learning solution replaces this tedious, error-prone work with a modern data platform designed to rapidly integrate, harmonize and transform data from all relevant data sources into optimized Machine Learning-ready feature datasets.
The data fabric provides the advanced data transformation functionality essential for fast and effective feature engineering to help separate key business signals from irrelevant noise.
Remember, data come first, this new paradigm integrates and harmonizes all relevant data sources — structured and unstructured data alike — using a built-in graph database and semantic data layer. The data fabric conveys the business context and meaning of your data, making it easier for business users to understand and properly utilize.
Reproducibility is important for data science and of course machine learning, so we need an easy way to reuse harmonized structured and unstructured data by managing catalogs of data sets as well as ongoing aspects of data integrations such as data quality processing, and this is what the data fabric provides. It also retains end-to-end lineage and provenance for the data comprising machine learning datasets so that it is easy to find out what data transformations are required when it comes to using models in production.
In following articles I’ll give a concrete example on how to do machine learning in this new framework.
Conclusions
Machine learning is not new, but there is a new paradigm to do it, and maybe it’s the future of the field (how optimistic of me). Inside of the data fabric, we have new concepts like ontology, semantics, layers, knowledge-graph, etc; but all of those can improve the way we think about and do machine learning.
In this paradigm, we discover hidden insights in the data fabric by using algorithms that are able to find those insights without being specifically programmed for that, to create models that solves a particular (or multiple) problem(s).
Thanks to the amazing team at Ciencia y Datos for helping with this article.


