Is an experiment still scientific if it is not reproducible?
“There is general recognition of a reproducibility crisis in science right now. I would venture to argue that a huge part of that does come from the use of machine learning techniques in science.” — Genevera Allen, Professor of Statistics and Electrical Engineering at Rice University
The use of machine learning is becoming increasingly prevalent in the scientific process, replacing traditional statistical methods. What are the ramifications of this on the scientific community and the pursuit of knowledge? Some have argued that the black-box approach of machine learning techniques is responsible for a crisis of reproducibility in scientific research. After all, is something really scientific if it is not reproducible?
Disclaimer: This article is my own opinion based on the material referred to in the references. This is a contentious area in academia and constructive debating is welcomed.
The cycle of the scientific process.
Machine learning (ML) has become ubiquitous in scientific research, and in many places has replaced the use of traditional statistical techniques. Whilst ML techniques are often simpler to perform analysis with, the inherent black-box approach causes severe problems in the pursuit of truth.
The “reproducibility crisis” in science refers to the alarming number of research results that are not repeated when another group of scientists tries the same experiment. It can mean that the initial results were wrong. One analysis suggested that up to 85% of all biomedical research carried out in the world is wasted effort.
The debate over the reproducibility crisis is probably the closest you can come in academia to a war between machine learning and statistics departments.
One AI researcher in a Science article alleged that machine learning has become a form of ‘alchemy’.AI researchers allege that machine learning is alchemy, Ali Rahimi, a researcher in artificial intelligence (AI) at Google in San Francisco, California, took a swipe at his…www.sciencemag.org
His paper and blog article about this are both worth reading: https://people.eecs.berkeley.edu/~brecht/papers/07.rah.rec.nips.pdf Reflections on Random Kitchen Sinks Ed. Note: Ali Rahimi and I won the test of time award at NIPS 2017 for our paper “Random Features for Large-scale…www.argmin.net
ML nicely supplements the scientific process, making its use in research ultimately inevitable. ML can be considered an engineering task — like an assembly line with its modeling, parameter tuning, data preparation, and optimization components. The intent of ML is to find optimal answers or predictions — which is a subset of scientific inquiry.
The types and algorithms for machine learning can be the subject of science in itself. Many research papers are being written about various types and sub-types of ML algorithms just like statistical methods of the past.
In February 2019, Genevera Allen gave a grave warning at the American Association for the Advancement of Science that scientists are leaning on machine learning algorithms to find patterns in data even when the algorithms are just fixating on noise that cannot be reproduced by another experiment.
This challenge has implications across multiple disciplines, as machine learning is used for obtaining discoveries in many fields such as astronomy, genomics, environmental science, and healthcare.
The prime example she uses is genomic data, which are typically incredibly large datasets of hundreds of gigabytes or several terabytes. Allen states that when a scientist uses poorly understood ML algorithms to cluster genomic profiles, specious and unreproducible results can often arise.
It is not until another team runs a similar analysis and finds very different results that the results are contested and discredited. This can be for multiple reasons:
- Lack of knowledge about the algorithm
- Lack of knowledge about the data
- Misinterpretation of the results
Lack of algorithmic knowledge
Lack of algorithmic knowledge is extremely common in machine learning. If you do not understand how an algorithm is producing results, then how can you be sure that it is not cheating or finding spurious correlations between variables?
This is a huge problem in neural networks due to the plethora of parameters (typically millions for deep neural networks). Not only do the parameters count, but also the hyperparameters — including items such as the learning rate, the initialization strategy, the number of epochs, and the network architecture.
Realizing that you lack algorithmic knowledge is not enough to solve the problem. How do you compare results if different networks are used across different research papers? Even adding a single extra variable or changing one hyperparameter can significantly influence the results due to the highly complex and dynamic structure of the high-dimensional neural network loss landscape.
Lack of data knowledge
Lack of data knowledge is also a huge issue, but one that extends to traditional statistical techniques. Errors in the acquisition of the data — such as quantization errors, sensor uncertainties, and the use of proxy variables — are one of the major issues.
Suboptimal data will always be a problem, but understanding what algorithm to use with what kind of data is also incredibly important and can have significant implications on results. This can be easily illustrated by examining a simple regression.
If we use linear regression with more parameters than data points (a very normal situation in genomics, where we have many genes and few data points) then our selection of regularization severely impacts what parameters are determined to be ‘important’.
If we use a LASSO regression, this tends to push apparently unimportant variables to be zero, thus eliminating them from the regression and providing some variable selection.
If we use a ridge regression, the regression tends to shrink these parameters to be small enough that they are negligible but does necessarily remove them from the dataset.
If we use Elastic Net regression (a combination of LASSO and ridge regression), we will again get very different answers.
If we do not use any regression, then the algorithm will obviously overfit to the data as we have more variables than data points, so the algorithm will trivially fit all data points.
Clearly, with linear regression, there are statistical tests that can be done to assess the accuracy in the form of confidence intervals, p-tests, etc. However, the same luxuries do not exist for a neural network, so how can we be sure of our conclusions? The best we can currently do is state the exact architecture and hyperparameters of the model, and provide the code as open-source for other scientists to analyze and reuse the model.
Misinterpretation of Results
Misinterpretation of results can be very common in the scientific world. One reason for this is that correlation does not imply causation — there are several reasons why two variables, A and B, might be correlated:
- A might be caused by the occurrence of B
- B might be caused by the occurrence of A
- A and B might be caused by a further confounding variable, C
- A and B may be spuriously correlated
It is easy to show a correlation between two values, but it is extremely difficult to determine the causation of such results. By typing in spurious correlations on Google, you can come up with some pretty interesting and clearly ridiculous correlations that have statistical significance:
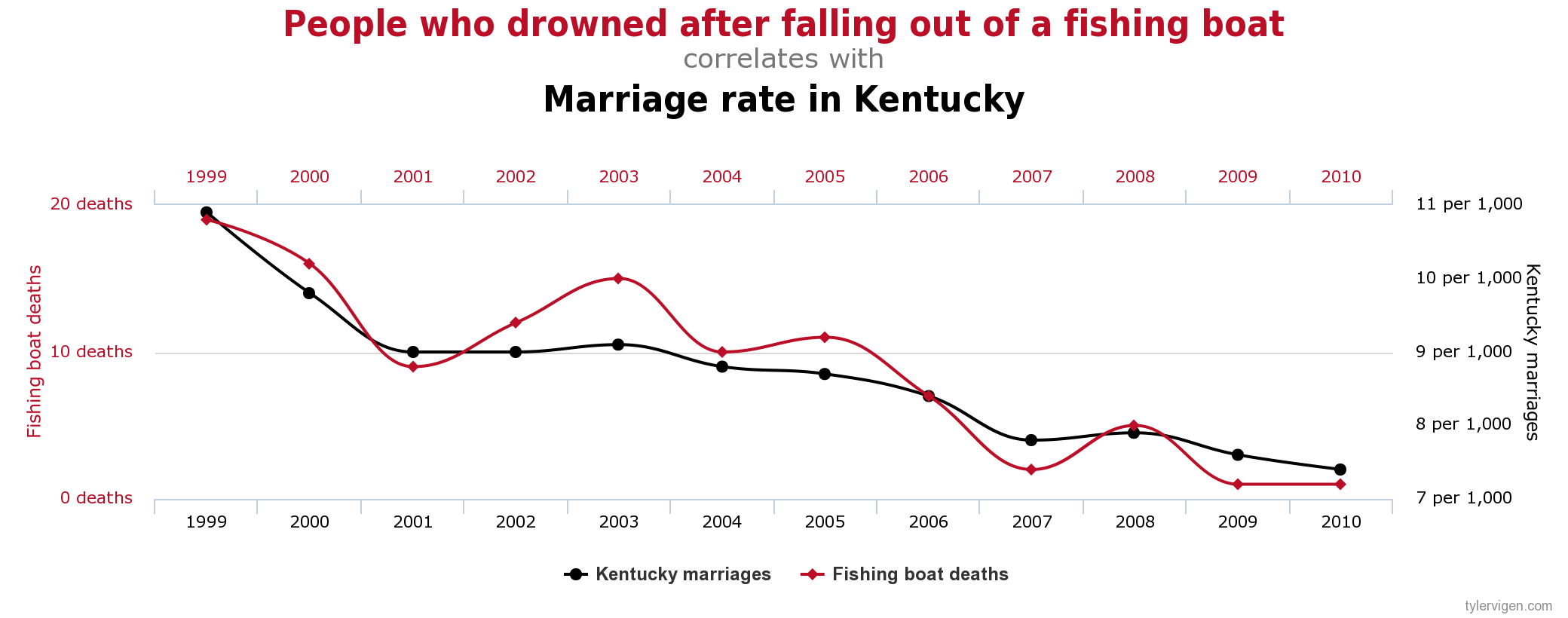
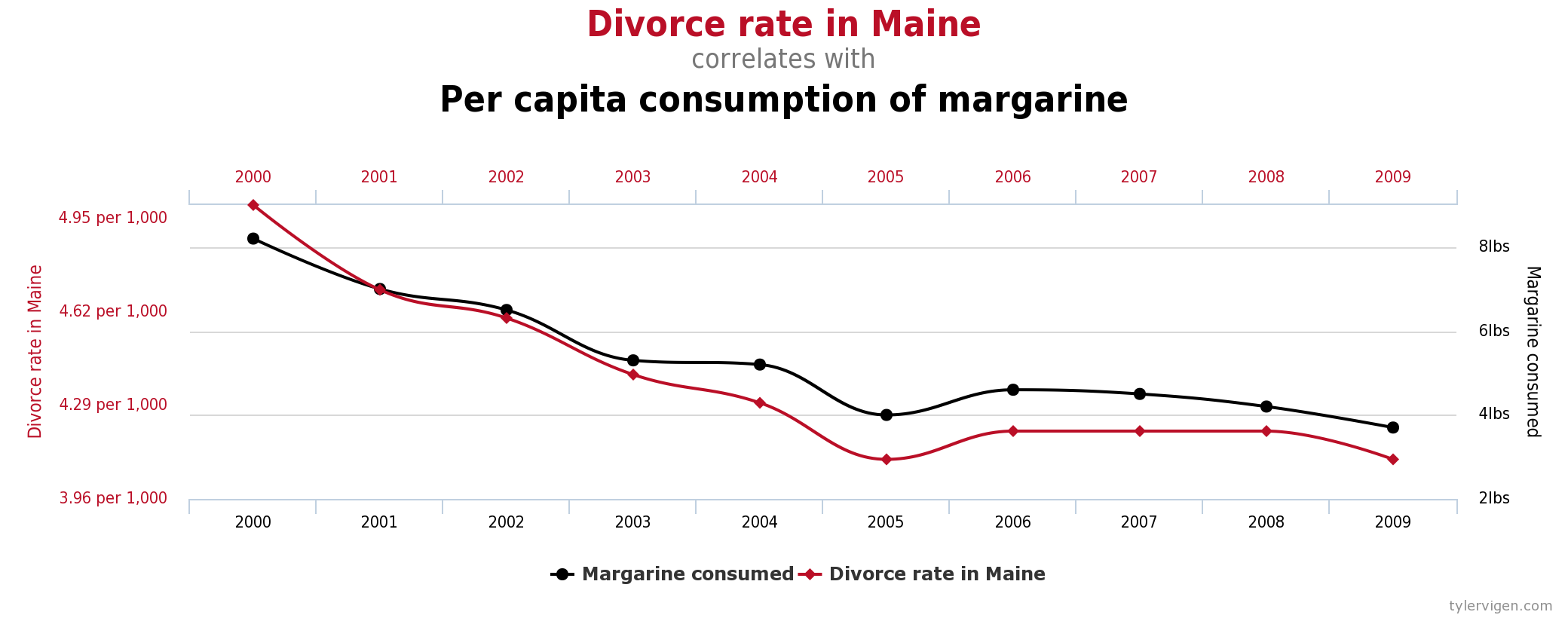
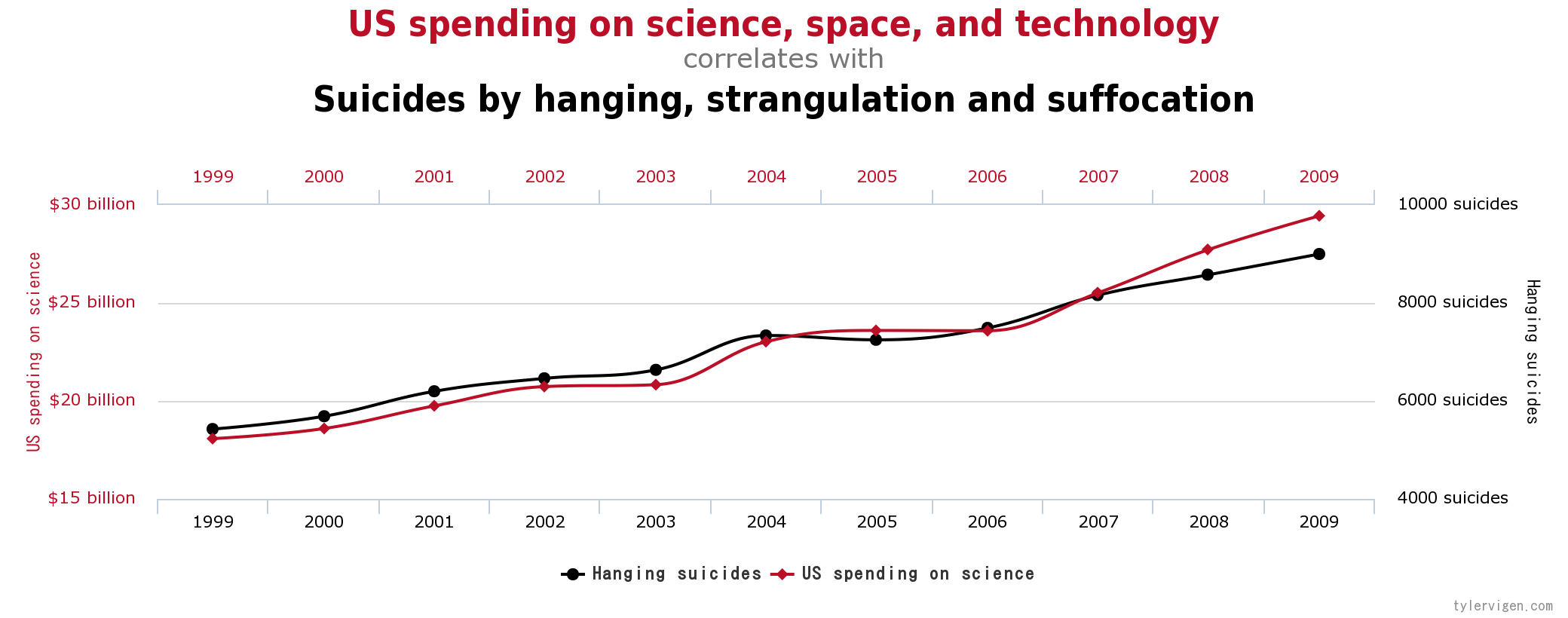
These may seem like ridiculous correlations, but the point is that if these variables were put together in a dataset that was fed to a machine learning algorithm, the algorithm would accept this as a causal variable without asking any questions about the validity of said causation. In this sense, the algorithm is likely to be inaccurate or wrong because the software is identifying patterns that exist only in that data set and not the real world.
The occurrence of spurious correlations, but it has become alarmingly more prevalent in recent years due to the use of large datasets with thousands of variables.
If I have a thousand variables and millions of data points, it is inevitable that there will be some correlations between the data. Algorithms can latch onto these and assume causation, effectively performing unconscious p-hacking, a technique frowned upon in academia.
What is p-hacking?
The practice of p-hacking involves taking a dataset and exhaustively searching for correlations that are statistically significant and taking them as scientifically valid.
The more data you have, the more likely you are to find a spurious correlation between two variables.
Usually, science involves the formation of a hypothesis, collection of data, and the analysis of the data to determine whether the hypothesis was valid. What p-hacking does is perform an experiment and then post-hoc hypotheses are formed to explain the data that was obtained. Sometimes, this is done without malintent, but other times scientists do this so that they are able to publish more papers.
Enforcing Correlations
One of the other problems of machine learning algorithms is that the algorithm must make a prediction. The algorithm cannot say ‘I didn’t find anything’. This brittle framework means that the algorithm will find some way of explaining the data no matter how unsuitable the features it has been given are (as long as the algorithm and data have been set up correctly, otherwise it may fail to converge).
Currently, I know of no machine learning algorithms that are able to come back to the user and tell them that the data is unsuitable, this is implicitly presupposed to be the job of the scientist — which is not an unfair assumption.
Why Use Machine Learning Then?
This is a good question. Machine learning makes analyzing datasets much easier and the ML algorithms perform the bulk of work for the user. In areas where datasets are too large to effectively analyze using standard statistical techniques, this becomes invaluable. However, although it accelerates the job of scientists, the increase in productivity afforded by machine learning is arguably offset by the quality of these predictions.
What can be done?
It is not all doom and gloom. The same problem has always been present with traditional statistical methods and datasets, these problems have just been amplified by the use of large datasets and algorithms which can automatically find correlations and are less interpretable than traditional techniques. This amplification has exposed weaknesses in the scientific process that must be ironed out.
However, there is work underway on the next generation of machine-learning systems to make sure they’re able to assess the uncertainty and reproducibility of their predictions.
That being said, it is a poor worker who blames their tools for failure, and scientists need to take more care in their use of ML algorithms to ensure that their research is corroborated and validated. The peer review process is designed to ensure this, but it is also the responsibility of the individual researcher. Researchers need to understand the techniques they are using and to understand their limitations. If they do not have these expertise then perhaps a quick trip to the statistics department to discuss with a professor would be fruitful (as I have done myself).
Rahimi (who believes ML is a form of alchemy) offers several suggestions for learning which algorithms work best, and when. He states that researchers should conduct ablation studies — successively removing parameters to assess their influence on the algorithm. Rahimi also calls for sliced analysis — analyzing an algorithm’s performance to see how improvements in certain areas might have a cost elsewhere. Lastly, he suggests running algorithms with a variety of different hyperparameter settings and should report performances for all of them. These techniques would provide a more robust analysis of the data using ML algorithms.
Due to the nature of the scientific process, once these issues are resolved, relationships previously found to be accurate that are, in fact, spurious, will eventually be found and corrected. Relationships that are accurate will, of course, stand the test of time.
Final Comments
Machine learning in science does present problems in academia due to the lack of reproducibility of results. However, scientists are aware of these problems and a push toward more reproducible and interpretable machine learning models is underway. The real breakthrough will be once this has been completed for neural networks.
Genevera Allen underscores a fundamental problem facing machine intelligence: data scientists still do not understand the mechanisms by which machines learn. The scientific community must make a concerted effort in order to understand how these algorithms work and how best to use them to ensure reliable, reproducible, and scientifically valid conclusions are made using data-driven methods.
Even Rahimi, who alleged that machine learning is alchemy, is still hopeful of its potential. He states that ‘alchemy invented metallurgy, ways to make medication, dying techniques for textiles, and our modern glass-making processes. Then again, alchemists also believed they could transmute base metals into gold and that leeches were a fine way to cure diseases.’
As physicist Richard Feynman said in his 1974 commencement address at the California Institute of Technology,
“The first principle [of science] is that you must not fool yourself, and you are the easiest person to fool.”
References
[1] https://science-sciencemag-org.ezp-prod1.hul.harvard.edu/content/sci/365/6452/416.full.pdf
[3] https://bigdata-madesimple.com/machine-learning-disrupting-science-research-heres/
[4] https://biodatamining.biomedcentral.com/track/pdf/10.1186/s13040-018-0167-7
[5] https://www.sciencemag.org/news/2018/05/ai-researchers-allege-machine-learning-alchemy
[6] https://www.sciencedaily.com/releases/2019/02/190215110303.htm
[7] https://phys.org/news/2018-09-machine-scientific-discoveries-faster.html
[9] https://www.datanami.com/2019/02/19/machine-learning-for-science-proving-problematic/
[10] https://www.quantamagazine.org/how-artificial-intelligence-is-changing-science-20190311/
[12] https://blogs.nvidia.com/blog/2019/03/27/how-ai-machine-learning-are-advancing-academic-research/
[14] https://www.hpcwire.com/2019/02/19/machine-learning-reproducability-crisis-science/



