Ready to learn Machine Learning? Browse Machine Learning Training and Certification courses developed by industry thought leaders and Experfy in Harvard Innovation Lab.
What's different about machine learning projects? How do you reduce risks and build a good solution quickly?
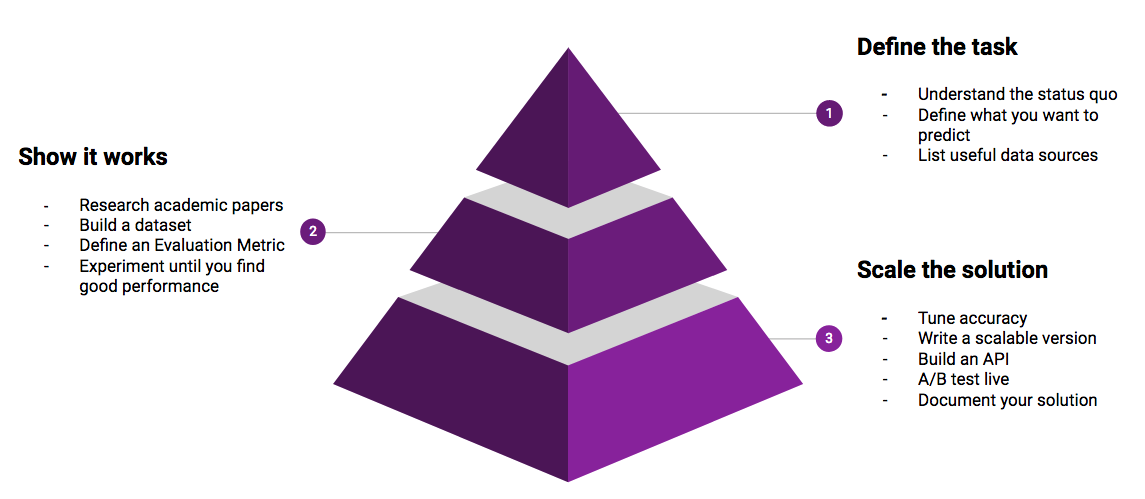
Machine Learning Project Workflow
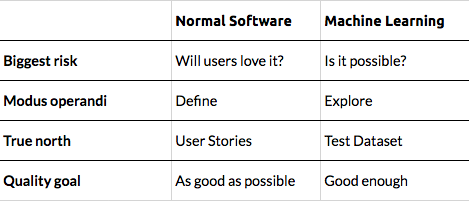
In standard software development, you simply answer the question:
What do you want to implement?
And then you, well, implement.
But in machine learning projects, you first need to explore what’s possible – with the data you have. So the first question is:
What can you implement?
Here’s what we learned works to keep a machine learning project on track from start to finish:
1. Define the task
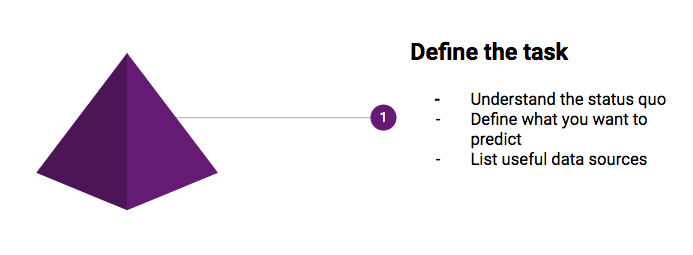
It’s easy to get drawn into AI projects that don’t go anywhere. A proper machine learning project definition drastically reduces this risk.
These are the questions you need to answer to define a project:
Understand the current process
What is your current process? Your machine learning solution will replace a process that already exists. How are decisions currently made in this process? Considering the current process will give you a lot of domain knowledge and help you define how your machine learning system has to look.
Define what you want to predict
What exact variable do you want to predict? Define the output of your machine learning system — in as much detail as possible.
List the useful data sources
What data do you have that’s useful to predict this output correctly? Start by listing the data sources the current process relies on. One way to list useful data sources is by asking yourself: “If I — as a human — needed to make this prediction, what data points would I want to know about?”
If you understand the current process, know what you want to predict, and have identified all the useful data sources, then you’re in a good position to decide whether it makes sense to proceed to the next stage.
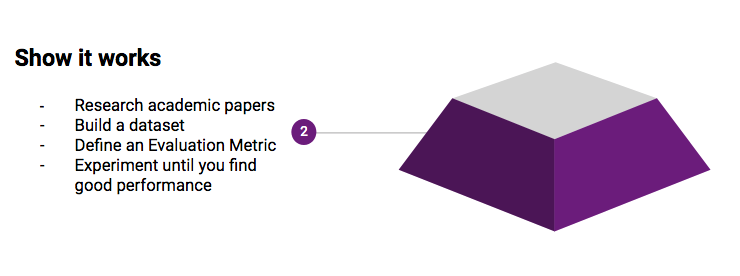
2. Find an approach that works
Even if you have a good problem definition, you can’t know yet how accurate your machine learning model will be in the end – or whether it will be worth replacing the current process.
A proof of concept is the cheapest way to find out what ROI you can expect from your final solution. These are the steps:
Research
Research all the ways other teams have resolved similar tasks — whether they used machine learning or not. Then make a plan, using what you’ve learned from both your research and the existing process you want to replace.
Build a dataset
The central part of any machine learning project is the sample dataset! This includes realistic examples of exactly those cases for which you want your machine learning system to make correct predictions. Think of it as an Excel table, with:
- One row per example, and
- A number of columns of useful input data, plus
- One column containing the output (aka the target).
The model then has to learn to predict the output from the input. For example, predicting a customer’s credit rating (output) from their payment history (input).
This dataset is like the requirements document in a normal software project — the point of reference against which you check whether you’re on track.
Experiment
Start with the most promising approach, evaluate it, and then improve from there. Repeat – until you’ve found an approach that is good enough.
3. Build a full-scale solution
Working software is the primary measure of progress. – Agile Manifesto
A proof-of-concept doesn’t make you any money. So here are the steps to take you to a stable, full-scale solution.
Improve accuracy
A proof-of-concept is a 20/80 implementation. Now it’s time to make the critical improvements you left out in your first iteration:
- Add more data;
- Build new features;
- Try other algorithms;
- Fine-tune the model parameters.
Scale
It’s a big step from a proof-of-concept script to a production-ready solution.
- Scalability & Stability: Rewrite data processing steps into separate, scalable tasks within a data pipeline.
- Tests: Write additional unit and integration tests — that also cover possible errors in the data.
- Deployment: Build flexible, repeatable, easy deployment that can handle the throughput and processing speed you need (including automated build-up of your infrastructure).
A/B Test
Similarly to other software updates, the final test for your newly automated process is comparing it with the current process. With an A/B test, you can measure the improvement you’ve achieved, as well as the ROI of your project.
API
Your machine learning service needs a way to speak to the rest of your infrastructure. That’s either done by continually saving the results into a database or making the algorithm available through an API.
Documentation
Beyond documentation for the code, you should consider writing a user guide that explains how the solution works. It’s important to clarify the ideas behind the implementation: in data science, it can be hard to understand your reasoning from your code alone.
Optional Add-ons
- Versioning. Maybe you need to A/B test against an older model, or switch to a previous version of your pipeline on short notice — correct versioning makes this easy.
- Automated retraining. Models get outdated — and eventually, you’ll have to retrain yours on new data. In some cases, it makes sense to automate model updating.


