There are 3 technical (read: theoretical, scientific) reasons why the data-driven/quantitative/statistical/machine learning approaches (that I will collectively refer to as BERTology) are utterly hopeless and futile efforts, at least when it comes to language understanding. This is a big claim, I understand, especially given the current trend, the misguided media hype, and the massive amount of money the tech giants are spending on this utterly flawed paradigm. As I have repeated this claim in my publications, in seminars and posts, I have often been told “but could all of those people be wrong?” Well, for now I will simply reply with “yes, they could indeed all be wrong”. I say that armed with the wisdom of the great mathematician/logician Bertrand Russell who once said
The fact that an opinion has been widely held is no evidence whatsoever that it is not utterly absurd
Before we begin, however, it is important to emphasize that our discussion is directed to the use of BERTology in NLU, and the ‘U’ here is crucial — that is, and as will become obvious below, BERTology might be useful in some NLP tasks (such as text summarization, search, extraction of key phrases, text similarity and/or clustering, etc.) because these tasks are all some form of ‘compression’ that machine learning can be successfully applied to. However, we believe that NLP (which is essentially just text processing) is a completely different problem from NLU. Perhaps NLU should be replaced by HuTU for human thought understanding, since NLU is about comprehending the thoughts behind our linguistic utterances (you may also want to read this short article that discusses this specific point).
So, to summarize our introduction: the claim that we will defend here is that BERTology is a futile effort to NLU (in fact, it is irrelevant) and this claim is not about some NLP tasks, but is specific to true understanding of ordinary spoken language, the kind of which we do on a daily basis when we engage in dialogues with people that we don’t even know, or with young children that do not have any domain specific knowledge!
Now we can get down to business.
MTP — the Missing Text Phenomenon
Let us start first with describing a phenomenon that is at the heart of all challenges in natural language understanding, which we refer to as the “missing text phenomenon” (MTP).
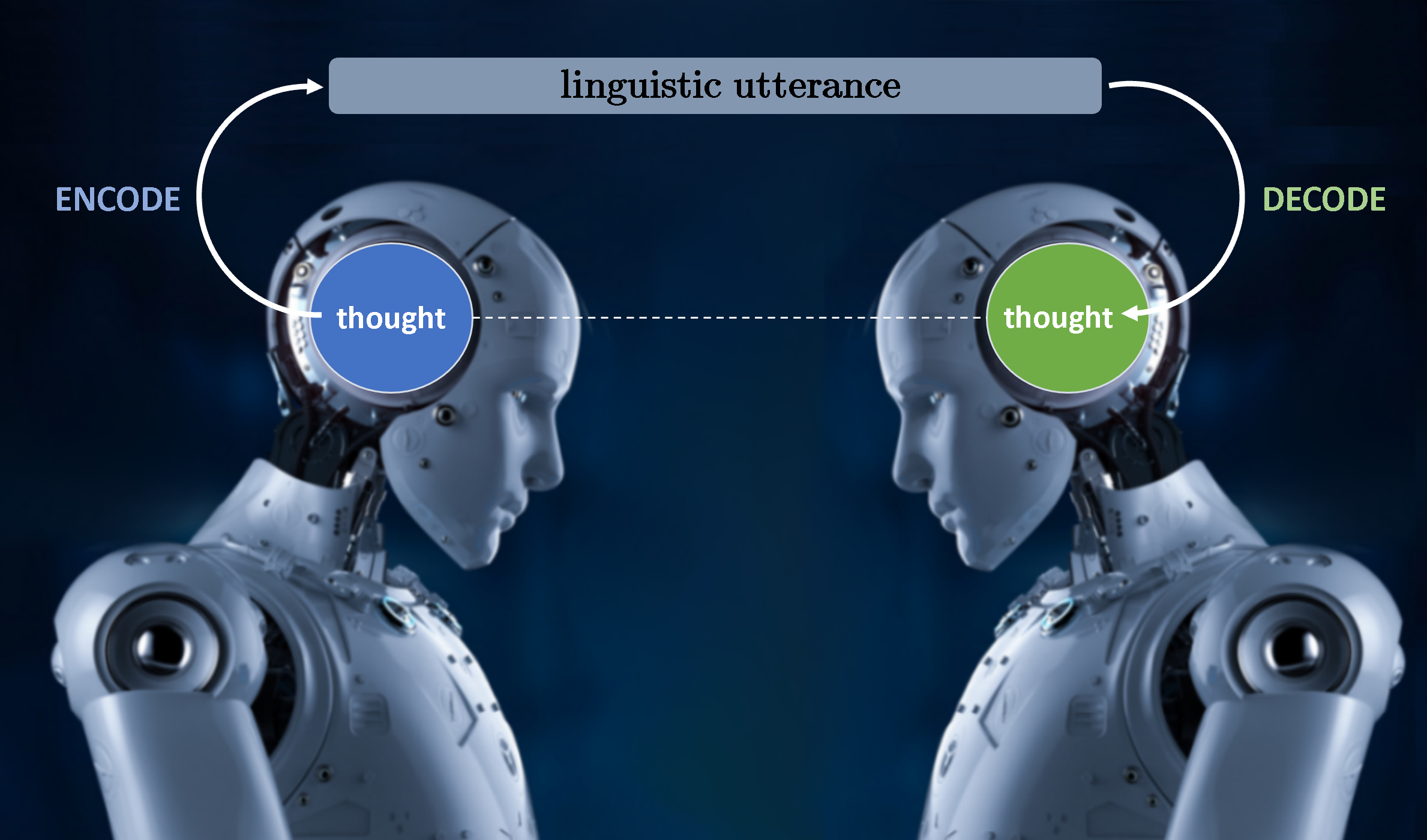
Linguistic communication happens as shown in the image above: a thought is encoded by a speaker into some linguistic utterance (in some language), and the listener then decodes that linguistic utterance into (hopefully) the thought that the speaker intended to convey! It is that “decoding” process that is the ‘U’ in NLU — that is, understanding the thought behind the linguistic utterance is exactly what happens in the decoding process. Moreover, there are no approximations or any degrees of freedom in this ‘decoding’ process — that is, from the multitude of possible meanings of an utterance, there is one and only one thought the speaker intended to convey in making an utterance.And this is precisely why NLU is difficult. Let’s elaborate.
In this complex communication there are two possible alternatives for optimization, or for effective communication: (i) the speaker can compress (and minimize) the amount of information sent in the encoding of the thought and hope that the listener will do some extra work in the decoding (uncompressing) process; or (ii) the speaker will do the hard work and send all the information needed to convey the thought which would leave the listener with little to do (see this article for a full description of this process). The natural evolution of this process, it seems, has resulted in the right balance where the total work of both speaker and listener is optimized. That optimization resulted in the speaker encoding the minimum possible information that is needed, while leaving out everything else that can be safely assumed to be information that is available for the listener. The information we tend to leave out is usually information that we can safely assume to be available for both speaker and listener, and this is precisely the information that we usually call common background knowledge.
To appreciate the intricacies of this process, consider the following (unoptimized) communication:

It should be very obvious that we certainly do not communicate this way. In fact, the above thought is usually expressed as follows:
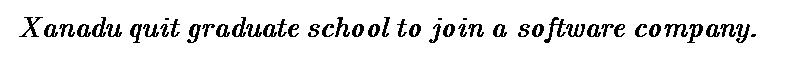
This much shorter message, which is how we usually speak, conveys the same thought as the longer one. We do not explicitly state all the other stuff because we all know

That is, for effective communication, we do not say what we can assume we all know! This is also precisely why we all tend to leave out the same information — because we all know what everyone knows , and that is the “common” background knowledge. This genius optimization process that humans have developed in about 200,000 years of evolution works quite well, and precisely because we all know what we all know. But this is where the problem is in AI/NLU. Machines don’t know what we leave out, because they don’t know what we all know. The net result? NLU is very very difficult, because a software program can only fully understand the thoughts behind our linguistic utterances if they can somehow “uncover” all that stuff that humans assume and leave out in their linguistic communication. That, really, is the NLU challenge (and not parsing, stemming, POS tagging, etc.) In fact, here are some well-known challenges in NLU — with the label such problems are usually given in computational linguistics. I am showing here (just some of) the missing text highlighted in red:

All the above well-known challenges in NLU are due to the fact that the challenge is to discover (or uncover) that information that is missing and implicitly assumed as shared and common background knowledge.
Now that we are (hopefully) convinced that NLU is difficult because of MTP — that is, because our ordinary spoken language in everyday discourse is highly (if not optimally) compressed, and thus the challenge in “understanding” is in uncompressing (or uncovering) the missing text, I can state the first technical reason why BERTology is not relevant to NLU.
The equivalence between (machine) learnability (ML) and compressibility (COMP) has been mathematically established. That is, it has been established that learnability from a data set can only happen if the data is highly compressible (i.e., it has lots of redundancies) and vice versa (see this article and the important article “Learnability can be Undecidable” that appeared in 2019 in the journal Nature). But MTP tells us that NLU is about uncompressing. What we now have is the following:

End of proof 1.
Intension (with an ‘s’)
Intension is another phenomenon I want to discuss, before I get to the second proof that BERTology is not even relevant to NLU. I will start with what is known as the meaning triangle, shown below with an example:
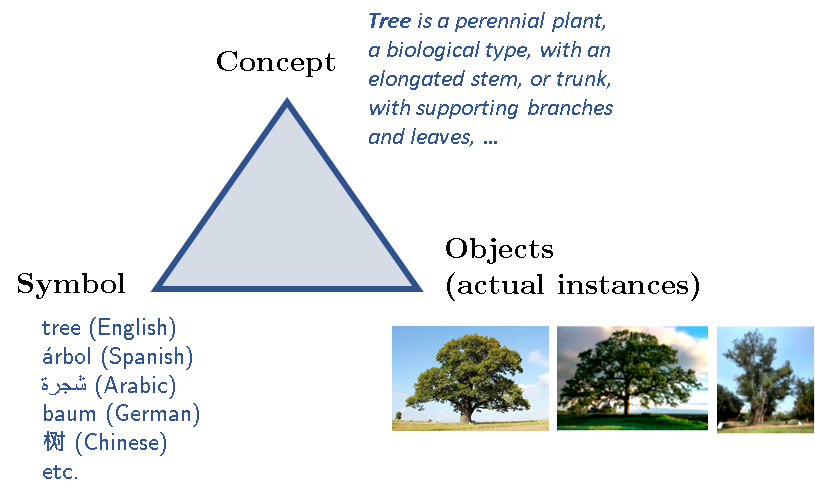
Thus every “thing” (or every object of cognition) has three parts: a symbol that refers to the concept, and the concept has (sometimes) actual instances. I say sometimes, because the concept “unicorn” has no “actual” instances, at least in the world we live in! The concept itself is an idealized template for all its potential instances (and thus it is close to the idealized Forms of Plato!) You can imagine how philosophers, logicians and cognitive scientists might have debated for centuries the nature of concepts and how they are defined. Regardless of that debate, we can agree on one thing: a concept (which is usually referred to by some symbol/label) is defined by a set of properties and attributes and perhaps with additional axioms and established facts, etc. Nevertheless, a concept is not the same as the actual (imperfect) instances. This is also true in the perfect world of mathematics. So, for example, while the arithmetic expressions below all have the same extension, they have different intensions:
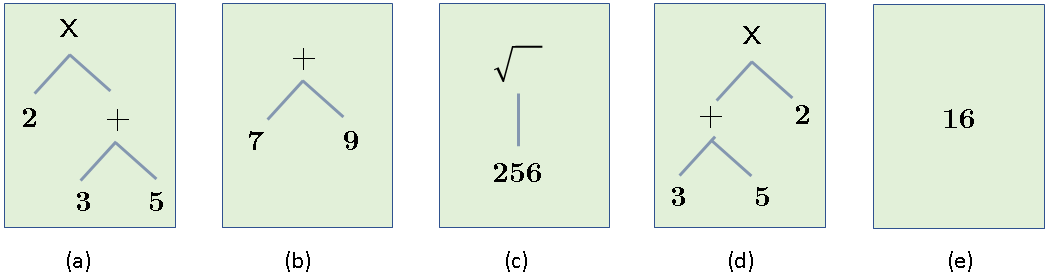
Thus, while all the expressions evaluate to 16, and thus are equal in one sense (their VALUE), this is only one of their attributes. In fact, the expressions above have several other attributes, such as their syntactic structure (that’s why (a) and (d) are different), number of operators, number of operands, etc. The VALUE (which is just one attribute) is called the extension, while the set of all the attributes is the intension. While in applied sciences (engineering, economics, etc.) we can safely consider these objects to be equal if they are equal in the VALUE attribute only, in cognition (and especially in language understanding) this equality fails! Here’s one simple example:
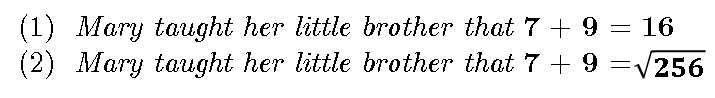
Suppose that (1) is true — that is, suppose (1) actually happened, and we saw it/witnessed it. Still, that does not mean we can assume (2) is true, although all we did was replace ‘16’ in (1) by a value that is (supposedly) equal to it. So what happened? We replaced one object in a true statement by an object that is supposedly equal to it, and we have inferred from something that is true something that is not! Well, what happened is this: while in physical sciences we can easily replace an object by one that is equal to it with one attribute, this does not work in cognition! Here’s another example:
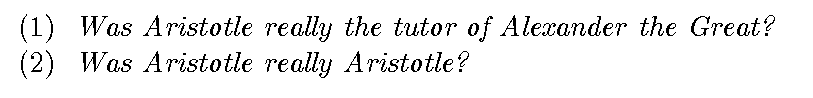
We obtained (2), which is ridiculous, by simply replacing ‘the tutor of Alexander the Great’ by a value that is equal to it, namely Aristotle. Again, while ‘the tutor of Alexander the Great’ and ‘Aristotle’ are equal in one sense (they both have the same value as a referent), these two objects of thought are different in many other respects.
I’ll stop here with the discussion of what ‘intension’ is and why it’s important in high-level reasoning, and specifically in NLU. The interested reader can look at this short article where I have references there to additional material.
So, what is the point from this discussion on ‘intension’. Natural language is rampant with intensional phenomena, since objects of thoughts — that language conveys — have an intensional aspect that cannot be ignored. But BERTology, in all its variants, is a purely extensional system and can only deal with extensions (numeric values, tensors/vectors) only and thus it cannot model or account for intensions, and thus, it cannot model various phenomena in language.
End of proof 2.
Incidentally, the fact that BERTology is a purely extensional paradigm and it cannot account for ‘intension’ is the source of so-called ‘adversarial examples’ in DL. The problem is related to the fact that once tensors (high-dimensional vectors) are composed into one tensor, the resulting tensor can now be decomposed into components in infinite number of ways (meaning the decomposition is undecidable) — that is, once the input tensors are composed we lose the original structure (in simple terms: 10 can be the value of 2 * 5, but also the result of 8 + 1 + 1, and the result of 9 + 1 + 0, etc). Neural networks can always be hit with adversarial examples because by optimizing in reverse, we can always get the outputs expected at any layer but from components other than the ones expected. But this is a discussion for another place and another time.
Statistical (In)Significance
One of the main issues with BERTology regarding statistical significance is the issue of function words, that in BERTology must be ignored and are labelled as “stop-words”. These words have the same probability in every context and thus they must be taken out because they will disrupt the entire probability space. But, and whether BERTologists like it or not, function words are the words that in the end glue together the final meaning. Just consider the difference between the pair of sentences below:
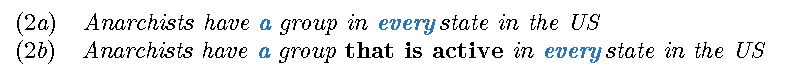
In (2a) we are referring to 50 groups, while to only 1 in (2b). How we interpret quantifiers, prepositions, modals, etc. changes the target (and intended) meaning considerably and thus there cannot be any true language understanding without taking function words into account, and in BERTology they cannot be (appropriately) modelled.
We could have stopped here and that would be the end of proof 3 that BERTology is not even relevant to NLU. But there’s more…
BERTology is essentially a paradigm that is based on finding some patterns (correlations) in the data. Thus the hope in that paradigm is that there are statistically significant differences between various phenomenon in natural language, otherwise they will be considered essentially the same. But consider the following (see this and this for a discussion on this example as it relates to the Winograd Schema Challenge):
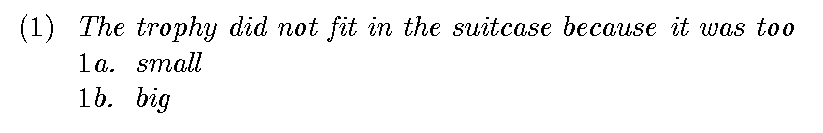
Note that antonyms/opposites such as ‘small’ and ‘big’ (or ‘open’ and ‘close’, etc.) occur in the same contexts with equal probabilities. As such, (1a) and (1b) are statistically equivalent, yet even for a 4-year old (1a) and (1b) are considerably different: “it” in (1a) refers to “the suitcase” while in (1b) it refers to “the trophy”. Basically, and in simple language, (1a) and (1b) are statistically equivalent, although semantically far from it. Thus, statistical analysis cannot model (not even approximate) semantics — it is that simple!
But let us see how many examples we would need if one insists on using BERTology to learn how to correctly resolve “it” in such structures. First of all, in BERTology there is no notion of type (and no symbolic knowledge whatsoever, for that matter). Thus the following are all different:

That is, in BERTology there is no type hierarchy where we can make generalized statements about a ‘bag’, a ‘suitcase’, and a ‘briefcase’ etc. where all are considered subtypes of the general type ‘container’. Thus, each one of the above, in a purely data-driven paradigm, are different and must be ‘seen’ separately. If we add to the semantic differences all the minor syntactic differences to the above pattern (say changing ‘because’ to ‘although’ — which also changes the correct referent to “it”) then a rough calculation tells us that a BERTology system would need to see something like 40,000,000 variations of the above, and all of this just to resolve a reference like “it” in structures like the one in (1). If anything, this is computationally implausible. As Fodor and Pylyshyn once famously quoted the renowned cognitive scientist George Miller, to capture all syntactic and semantic variations that an NLU system would require, the number of features a neural network might need is more than the number of atoms in the universe! (I would recommend for anyone interested in cognitive science this classic and brilliant paper — it is available here).
To conclude this section, often there is no statistical significance in natural language that can explain the different interpretations — and precisely because the information needed to bring out the statistical significance is not in the data but is information that is available elsewhere — in the above example, the information needed is something like this: not(FIT(x,y)) then LARGER(y, x) is more likely than LARGER(x, y). In short, the only source of information in BERTology is the data, but very often the required information required for a correct interpretation is not even in the data, and you can‘t’ find what is not even there.
End of proof 3
Conclusion
I have discussed three reasons that proves BERTology is not even relevant to NLU (although it might be used in text processing tasks that are essentially compression tasks). Each of the above three reasons is enough on its own to put and end to this runaway train called BERTology.
Natural language is not (just) data!



