Timeline for data science competency depends on the level: Basic, Intermediate, and Advanced
I. Introduction
For anyone interested in jumping into the field of data science, one of the most important questions to ask is: How long does it take to gain competency in data science?
This article will discuss the typical timeline for data science competency. The time required to gain competency in data science depends on the level of competency. In Section II, we will discuss the three levels of data science. In Section III, we discuss the time required for gaining data science competency based on the level of interest. A short summary completes the article.
The views provided here are my views and are based on my own journey to data science.
II. The 3 Levels of Data Science
Before discussing the timeline for data science competency, let us first consider the three levels of data science. This section will discuss what I consider to be the three levels of data science competency, namely: level 1 (basic level); level 2 (intermediate level); and level 3 (advanced level). Competency increases from level 1 to 3. We shall use Python as the default language, even though other platforms such as R, SAS, and MATLAB could be used as programming languages for data science.
1. Basic Level
At level one, a data science aspirant should be able to work with datasets generally presented in comma-separated values (CSV) file format. They should have competency in data basics; data visualization; and linear regression.
1.1 Data Basics
Be able to manipulate, clean, structure, scale, and engineer data. They should be skilled in using pandas and NumPy libraries. Should have the following competencies:
- Know how to import and export data stored in CSV file format
- Be able to clean, wrangle, and organize data for further analysis or model building
- Be able to deal with missing values in a dataset
- Understand and be able to apply data imputation techniques such as mean or median imputation
- Be able to handle categorical data
- Know how to partition a dataset into training and testing sets
- Be able to scale data using scaling techniques such as normalization and standardization
- Be able to compress data via dimensionality reduction techniques such as principal component analysis (PC)
1.2. Data Visualization
Be able to understand the essential components of good data visualization. Be able to use data visualization tools including Python’s matplotlib and seaborn packages; and R’s ggplot2 package. Should understand the essential components of good data visualization:
- Data Component: An important first step in deciding how to visualize data is to know what type of data it is, e.g., categorical data, discrete data, continuous data, time-series data, etc.
- Geometric Component: Here is where you decide what kind of visualization is suitable for your data, e.g., scatter plot, line graphs, bar plots, histograms, Q-Q plots, smooth densities, boxplots, pair plots, heatmaps, etc.
- Mapping Component: Here, you need to decide what variable to use as your x-variable and what to use as your y-variable. This is important especially when your dataset is multi-dimensional with several features.
- Scale Component: Here, you decide what kind of scales to use, e.g., linear scale, log scale, etc.
- Labels Component: This includes things like axes labels, titles, legends, font size to use, etc.
- Ethical Component: Here, you want to make sure your visualization tells the true story. You need to be aware of your actions when cleaning, summarizing, manipulating, and producing a data visualization and ensure you aren’t using your visualization to mislead or manipulate your audience.
1.3 Supervised Learning (Predicting Continuous Target Variables)
Be familiar with linear regression and other advanced regression methods. Be competent in using packages such as scikit-learn and caret for linear regression model building. Have the following competencies:
- Be able to perform simple regression analysis using NumPy or Pylab
- Be able to perform multiple regression analysis with scikit-learn
- Understand regularized regression methods such as Lasso, Ridge, and Elastic Net
- Understand other non-parametric regression methods such as KNeighbors regression (KNR), and Support Vector Regression (SVR)
- Understand various metrics for evaluating a regression model such as MSE (mean square error), MAE (mean absolute error), and R2 score
- Be able to compare different regression models
2. Intermediate Level
In addition to skills and competencies in level I, should have competencies in the following:
2.1 Supervised Learning (Predicting Discrete Target Variables)
Be familiar with binary classification algorithm such as:
- Perceptron classifier
- Logistic Regression classifier
- Support Vector Machines (SVM)
- Be able to solve nonlinear classification problems using kernel SVM
- Decision tree classifier
- K-nearest classifier
- Naive Bayes classifier
- Understand several metrics for accessing the quality of a classification algorithm such as accuracy, precision, sensitivity, specificity, recall, f-l score, confusion matrix, ROC curve.
- Be able to use scikit-learn for model building
2.2 Model Evaluation and Hyperparameter Tuning
- Be able to combine transformers and estimators in a pipeline
- Be able to use k-fold cross-validation to assess model performance
- Know how to debug classification algorithms with learning and validation curves
- Be able to diagnose bias and variance problems with learning curves
- Capable of addressing overfitting and underfitting with validation curves
- Know how to fine-tune machine learning models via grid search
- Understand how to tune hyperparameters via grid search
- Be able to read and interpret a confusion matrix
- Be able to plot and interpret a receiver operating characteristic (ROC) curve
2.3 Combining Different Models for Ensemble Learning
- Be able to use the ensemble method with different classifiers
- Be able to combine different algorithms for classification
- Know how to evaluate and tune the ensemble classifier
3. Advanced Level
Be able to work with advanced datasets such as text, images, voice, and videos. In addition to the Basic and Intermediate skills, should have the following competencies:
- Clustering Algorithm (Unsupervised Learning)
- K-means
- Deep Learning
- Neural Networks
- Keras
- TensorFlow
- Theano
- Cloud Systems (AWS, Azure)
III. Timeline for Data Science Competency
Level 1 competency can be achieved within 6 to 12 months. Level 2 competencies can be achieved within 7 to 18 months. Level 3 competencies can be achieved within 18 to 48 months.
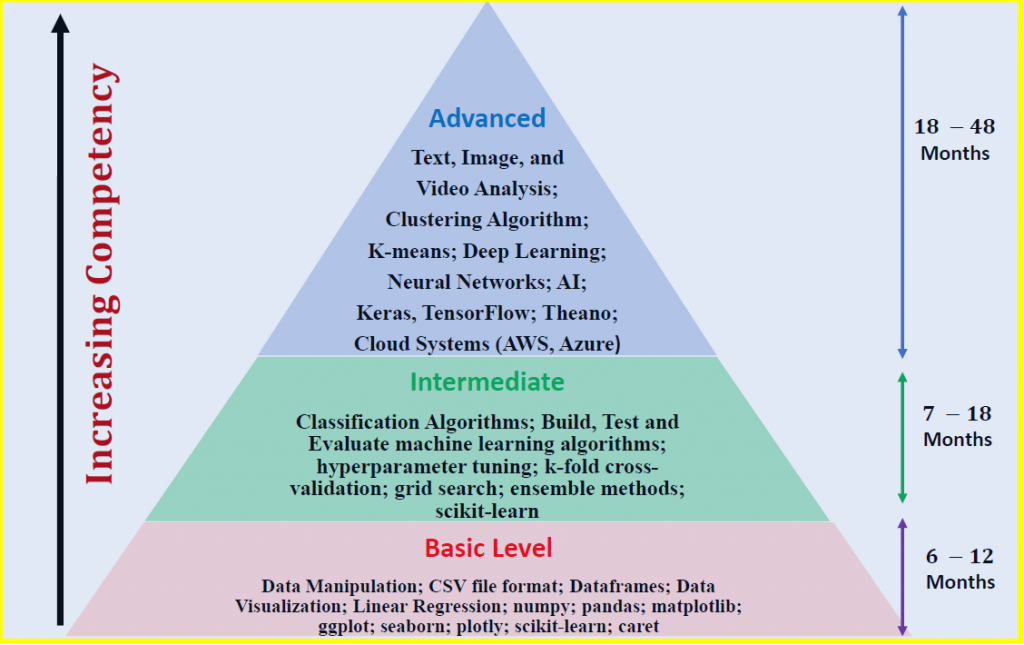
We remark here that these are approximate values only. The amount of time required to gain a certain level of competence depends on your background and how much amount of time you are willing to invest in your data science studies. Typically, individuals with a background in an analytic discipline such as physics, mathematics, science, engineering, accounting, or computer science would require less time compared to individuals with backgrounds not complementary to data science.
IV. Summary
In summary, we’ve discussed the 3 levels of data science. Level 1 competency can be achieved within 6 to 12 months. Level 2 competencies can be achieved within 7 to 18 months. Level 3 competencies can be achieved within 18 to 48 months. It all depends on the amount of effort invested and the background of each individual.



