Use This Instead
Information contained in User-Agent strings can be efficiently represented using low-dimensional embeddings, and then employed in downstream Machine Learning tasks.
What on Earth are User-Agent strings?
When a user interacts with a website, the browser sends HTTP requests to the server to fetch the required content, submit data, or perform other actions. Such requests typically contain several headers, i.e. character key-value pairs that specify parameters of a given request. A User-Agent string (refered to as “UAS” below) is an HTTP request header that describes the software acting on the user’s behalf (Figure 1).

The original purpose of UAS was content negotiation, i.e. a mechanism of determining the best content to serve to a user depending on the information contained in the respective UAS (e.g., image format, the language of a document, text encoding, etc.). This information typically includes details on the environment the browser runs in (device, operating system and its version, locale), browser engine and version, layout engine and version, and so on (Figure 2).

Although serving different web pages to different browsers is considered a bad idea nowadays, UAS still have many practical applications. The most common one is web analytics, i.e. reporting on the traffic composition to optimise the effectiveness of a website. Another use case is web traffic management, which involves blocking nuisance crawlers, decreasing the load on a website from unwanted visitors, preventing click fraud, and other similar tasks. Due to the rich information they contain, UAS can also serve as a source of data for Machine Learning applications. However, the latter use case has not received much attention so far. Here I address this issue and discuss an efficient way to create informative features from UAS for Machine Learning models. This article is a summary of the talk I presented recently at two conferences — Why R? and Enterprise Applications of the R Language. Data and code used in the examples described below are available at GitHub.
UAS elements as features for Machine Learning models
UAS elements can often serve as useful proxies of user characteristics, such as lifestyle, tech-savviness, and even affluence. For example, a user, who is typically visiting a website from a high-end mobile device is likely different from a user visiting that same website from Internet Explorer on a desktop computer running Windows XP. Having UAS-based proxies for such characteristics can be particularly valuable when no other demographic information is available for a user (e.g. when a new, unidentified person visits a website).
In certain applications, it can also be useful to distinguish between human and non-human web traffic. In some cases, this is straightforward to do as automated web crawlers use a simplified UAS format that includes the word “bot” (e.g., Googlebot/2.1 (+http://www.google.com/bot.html)). However, some crawlers do not follow this convention (e.g., Facebook bots contain the facebookexternalhit word in their UAS), and identifying them requires a lookup dictionary.
One seemingly straightforward way to create Machine Learning features from UAS is to apply a parser, extract individual UAS elements, and then one-hot encode these elements. This approach can work well in simple cases when only high-level and readily identifiable UAS elements need transforming into features. For example, it is relatively easy to determine the type of hardware of a User Agent (mobile vs desktop vs server, etc.). Several high-quality, regular expressions-based parsers can be used for this kind of feature engineering (e.g., see the “ua-parser” project and its implementations for a selection of languages).
However, the above approach quickly becomes impractical when one wants to use all elements making up a UAS and extract maximum information from them. There are two main reasons for this:
- Existing recommendations for the formatting of User-Agent headers are not enforced in any way, and one can encounter a wide variety of UAS specifications in the real world. As a result, consistent parsing of UAS is notoriously hard. Moreover, new devices and versions of operating systems and browsers emerge every day, turning the maintenance of high-quality parsers into a formidable task.
- The number of possible UAS elements and their combinations is astronomically large. Even if it were possible to one-hot encode them, the resultant data matrix would be extremely sparse and too large to fit into the memory of computers typically used by Data Scientists these days.
To overcome these challenges, one can apply a dimensionality reduction technique and represent UAS as vectors of fixed size, while minimising the loss of original information. This idea is not new, of course, and as UAS are simply strings of text, this can be achieved using a variety of methods for Natural Language Processing. In my projects, I have often found that the fastText algorithm developed by researchers from Facebook (Bojanowski et al. 2016) produces particularly useful solutions.
Describing the fastText algorithm is out of the scope of this article. However, before we proceed with examples, it is worth mentioning some of the practical benefits of this method:
- it is not data-hungry, i.e. a decently performing model can be trained on a few thousand examples only;
- it works well on short and structured documents, such as UAS;
- as the name suggests, it is fast to train;
- it deals well with “out-of-vocabulary words”, i.e. it can generate meaningful vector representations (embeddings) even for strings that have not been seen during the training.
fastText implementations: choose your weapon
The official implementation of fastText is available as a standalone C++ library and as a Python wrapper. Both of these libraries are well documented and easy to install and use. The widely used Python library gensim has its own implementation of the algorithm. Below I will demonstrate how one can also train fastText models in R.
There exist several R wrappers around the fastText C++ library (see fastText, fastrtext, and fastTextR). However, arguably the simplest way to train and use fastText models in R is by calling the official Python bindings via the reticulate package. Importing the fasttext Python module into an R environment can be done as follows:
# Install `fasttext` first
# (see https://fasttext.cc/docs/en/support.html)# Load the `reticulate` package
# (install first, if needed):
require(reticulate)# Make sure `fasttext` is available to R:
py_module_available("fasttext")
## [1] TRUE# Import `fasttext`:
ft <- import("fasttext")# Then call the required methods using
# the standard `$` notation,
# e.g.: `ft$train_supervised()`
Learning the UAS embeddings with fastText in R
Examples described below are based on a sample of 200,000 unique UAS from the whatismybrowser.com database (Figure 3).https://towardsdatascience.com/media/45d78c93c3aaedc888919cd6ac032fce Figure 3. A sample of UAS used in the examples in this article. Data are stored in a plain text file, where each row contains a single UAS. Note that all UAS were normalised to lower case and no other pre-processing has been applied.
Training an unsupervised fastText model in R is as simple as calling a command similar to the following one:
m_unsup <- ft$train_unsupervised(
input = "./data/train_data_unsup.txt",
model = "skipgram",
lr = 0.05,
dim = 32L, # vector dimension
ws = 3L,
minCount = 1L,
minn = 2L,
maxn = 6L,
neg = 3L,
wordNgrams = 2L,
loss = "ns",
epoch = 100L,
thread = 10L
)
The dim argument in the above command specifies the dimensionality of the embedding space. In this example, we want to transform each UAS into a vector of size 32. Other arguments control the process of model training (lr — learning rate, loss — the loss function, epoch — number of epochs, etc.). To understand the meaning of all arguments, please refer to the official fastText documentation.
Once the model is trained, it is easy to calculate embeddings for new cases (e.g., from a test set). The following example shows how to do this (the key command here is m_unsup$get_sentence_vector(), which returns a vector averaged across embeddings of individual elements that make up a given UAS):
test_data <- readLines("./data/test_data_unsup.txt")
emb_unsup <- test_data %>%
lapply(., function(x) {
m_unsup$get_sentence_vector(text = x) %>%
t(.) %>% as.data.frame(.)
}) %>%
bind_rows(.) %>%
setNames(., paste0("f", 1:32))
# Printing out the first 5 values
# of the vectors (of size 32)
# that represent the first 3 UAS
# from the test set:emb_unsup[1:3, 1:5]
## f1 f2 f3 f4 f5
## 1 0.197 -0.03726 0.147 0.153 0.0423
## 2 0.182 0.00307 0.147 0.101 0.0326
## 3 0.101 -0.28220 0.189 0.202 -0.1623
But how do we know if the trained unsupervised model is any good? Of course, one way to test it would involve plugging the vector representations of UAS obtained with that model into a downstream Machine Learning task and evaluating the quality of the resultant solution. However, before jumping to a downstream modelling task, one can also visually assess how good the fastText embeddings are. The well known tSNE plots (Maaten & Hinton 2008; see also this YouTube video) can be particularly useful.
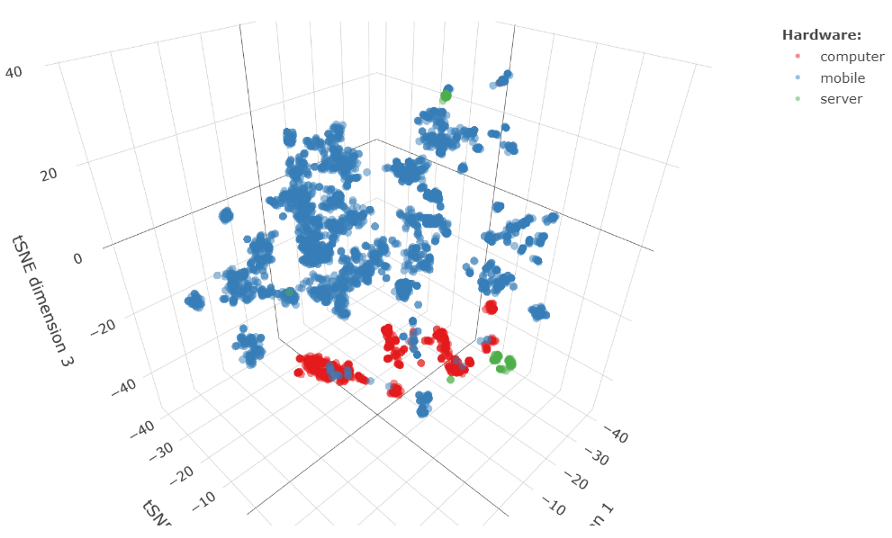
Figure 3 shows a 3D tSNE plot of embeddings calculated for UAS from a test set using the fastText model specified above. Although this model was trained in an unsupervised manner, it was able to produce embeddings that reflect important properties of the original User-Agent strings. For example, one can see a good separation of the points with regards to the hardware type.
Training a supervised fastText model by definition requires labelled data. This is where existing UAS parsers can often be of great help as one can use them to quickly label thousands of training examples. The fastText algorithm supports both the multiclass and multilabel classifiers. The expected (default) format for labels is __label__<value>. Labels formatted this way (and potentially separated by a space in the case of a multilabel model) are to be prepended to each document in the training dataset.
Suppose we are interested in embeddings that emphasise differences in UAS with regards to the hardware type. Figure 4 shows an example of labelled data that are suitable for training the respective model.
The R command required to train a supervised fastText model on such labelled data is similar to what we have seen before:
m_sup <- ft$train_supervised(
input = "./data/train_data_sup.txt",
lr = 0.05,
dim = 32L, # vector dimension
ws = 3L,
minCount = 1L,
minCountLabel = 10L, # min label occurence
minn = 2L,
maxn = 6L,
neg = 3L,
wordNgrams = 2L,
loss = "softmax", # loss function
epoch = 100L,
thread = 10L
)
We can evaluate the resultant supervised model by calculating precision, recall and f1 score on a labelled test set. These metrics can be calculated across all labels or for individual labels. For example, here are the quality metrics for UAS corresponding to the label “mobile”:
metrics <- m_sup$test_label("./data/test_data_sup.txt")
metrics["__label__mobile"]## $`__label__mobile`
## $`__label__mobile`$precision
## [1] 0.998351
##
## $`__label__mobile`$recall
## [1] 0.9981159
##
## $`__label__mobile`$f1score
## [1] 0.9982334
Visual inspection of the tSNE plot for this supervised model also confirms its high quality: we can see a clear separation of the test cases with regards to the hardware type (Figure 5). This is not surprising as by training a supervised model we provide supporting information that helps the algorithm to create task-specific embeddings.
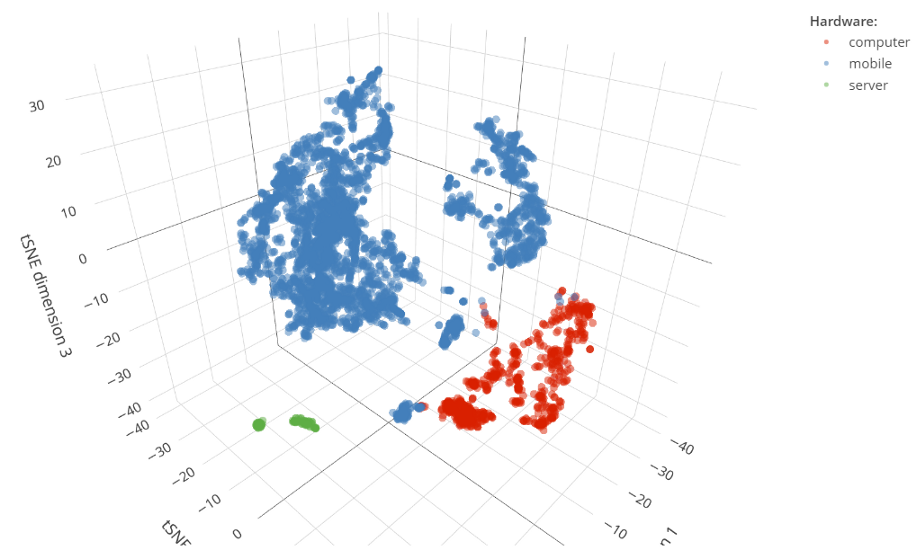
Conclusions
This article has demonstrated that the rich information contained in UAS can be efficiently represented using low-dimensional embeddings. Models to generate such embeddings can be trained in both unsupervised and supervised modes. Unsupervised embeddings are generic and thus can be used in any downstream Machine Learning task. Whenever possible, however, I would recommend training a task-specific, supervised model. One particularly useful algorithm for representing UAS as vectors of fixed size is fastText. Its implementations are available in all major languages used by Data Scientists nowadays.



