Your team has worked for months to gather data, built a predictive model, create a user interface, and deploy a new machine learning product with some early customers. But instead of celebrating victory, you’re now hearing grumbling from the account managers for those early adopter customers that they’re not happy with the prediction accuracy they are seeing and starting to think that “the model doesn’t work”. What do you do now?
This is a situation we often see at Pattern Labs in working with organizations that are implementing machine learning in new products. And it’s not an easy one to resolve quickly. The performance of real-world machine learning models is influenced by a large number of factors, some of which may be under your control and others which may not. On top of that, when trying to model real-world phenomenon, every modeling problem has an inherent amount of noise/randomness mixed in with the signal, making it difficult to understand the degree of accuracy one can truly expect to achieve with a predictive model. Add in the customer expectations in terms of the accuracy they expect to get with your model, and all of a sudden your data science team is stuck in a tricky situation trying to figure out where to even begin to solve the problem.
1) Understanding the Problem to Solve
The first place to start is to make sure the team has a good understanding of the customer problem they are trying to solve with the model. It is amazing how often the data science team’s understanding of what defines success differs from the customers’ criteria. We worked recently with a company that was trying to predict the impact of severe weather on a utility’s operations. The technical team was beating their heads against a wall trying to improve a MAPE score of their model. When we dug into it, it turned out that MAPE wasn’t the right metric to use at all, and the target they were striving for was one that they set themselves (vs. listening to the customer). What the customer actually cared most about was our ability to consistently classify the storm in a 1–5 impact severity range that they had defined for their operating procedures.
Ensuring that the data science team has a thorough understanding of the problem, and preferably hear it first-hand from customers themselves, is critical to the success of a new initiative. If your team is getting stuck in the situation described above where the model doesn’t work, step one is to go back and ensure you have properly defined the problem and understand how your customer measures success.
2) Is the data right, and complete?
The next step is to go back and look at the input data your team has collected. More often than not, when working with complex real-world models the primary reason for lack of model performance is due to issues with the input dataset and features, rather than the model itself. Particularly if you are running multiple types of models (and we would advise you to do so whenever possible) and getting similar results, it’s often a sign that your input dataset is holding you back.
A key part of this step is to ensure you have collected as much relevant data as you possibly can. Often there are contributing factors to real-world patterns that are not always intuitive or obvious, and so the more data and features you can collect, the better. There are plenty of techniques at your disposal to downselect the feature data to build a model on the most relevant features, which we’ll discuss in the next step. But for this step, the focus is on re-visiting your assumptions around which inputs drive the output you are trying to model, and going back for additional data if needed. For example, when trying to model a real-world phenomenon there are often unobvious factors that need to be taken into account due to their impact on trends and especially on outlier cases — such as seasonality, weather, calendar events, and even geo-political happenings.
Secondly, some simple QA checks should be put in place to ensure that the input data is getting mapped and processed correctly. We recently worked with a client who was struggling with model performance, only to eventually uncover that the issue was not with the model at all — the client was incorrectly processing some of the geo-located feature data which prevented the models they were running from identifying correct patterns.
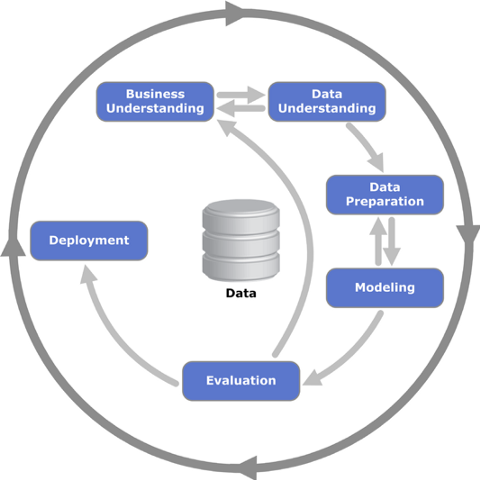
The CRISP-DM process is one of the most common frameworks followed by many data science teams for managing projects. We like it for its focus on ensuring business and data understanding prior to diving into the modeling. Two of the key steps in the CRISP-DM process are “data understanding” and “data preparation”. Properly following these steps involves an in-depth dive into the input data to really understand it, often aided by visualizations of distributions, trends, and relationships within the data. And “data preparation” often involves pre-processing, data augmentation, and/or normalization to prepare for modeling. Done properly, these two steps help the data scientist ensure that mistakes in input data are not to blame for any model performance issues he/she later encounter.
3) Model adjustments to dial in performance
Now that you’ve validated the input data as correct and as complete as possible, it’s time to focus on the fun stuff, the modeling itself. One of the highest impact parts of this step is the feature selection — downselecting the key features that most impact the output and training your model on those, eliminating redundant or highly correlated features to both speed up and increase model accuracy. There are several good blog posts out there on features selection techniques including univariate selection, recursive feature elimination, and random forest feature importance. Here is one for reference: https://machinelearningmastery.com/feature-selection-machine-learning-python/. Whichever technique you employ, or a combination of them all, make sure to spend time on this step to get the optimal combination of features for your model.
Another important part of this step is to revisit your choice of model, or considering adding additional model types or ensembling multiple models. Again there are many good articles comparing the pros and cons of different models, but we recommend running at least two model types when possible (ideally one being a neural net) to compare results.
And finally, once you have your features and your model selection, re-run your hyperparameter tuning ensuring you have properly defined your training, validation and test sets in a way that you are not “cheating” when tuning your model so that it generalizes well to new data rather than tuning it so tightly on the training set that it overfits and does a poor job in practice with new data.
4) Finally, and most importantly, manage your customers’ expectations
This is another critical step which many data scientists ignore, thinking it is “not their job”. When launching a new-to-the-world machine learning product, there is a fair amount of uncertainty around the performance of the model in the wild. Furthermore, as noted above the amount of noise that occurs in the real world around the problem you are solving may set limitations on your model’s performance despite your best efforts to maximize accuracy. It is part of the responsibility of the data science team to work hand-in-hand with product managers, salespeople, and customer success to define the message to the customer on the performance they can expect to see from the model, but also to educate them on how the model will improve over time with additional data to train on.
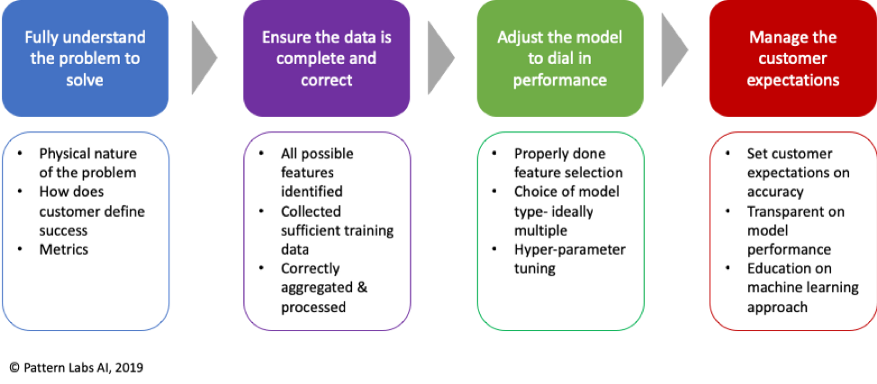
So the next time your team runs into performance challenges when releasing a new model into the wild, rather than playing the blame game or jumping right into adjusting model hyperparameters to optimize fit, take a step back and follow this simple, structured process to work through the problem step-by-step and maximize the probability of success with your new model.



