Big Data
According to Forbes, about 2.5 quintillion bytes of data is generated every day. Nonetheless, this number is just projected to constantly increase in the following years (90% of nowadays stored data has been produced within the last two years) [1].
What makes Big Data different from any other large amount of data stored in relational databases is its heterogeneity. The data comes from different sources and has been recorded using different formats.
- Unstructured = unorganised data (eg. videos).
- Semi-structured = the data is organised in a not fixed format (eg. JSON).
- Structured = the data is stored in a structured format (eg. RDBMS).
Big Data is defined by three properties:
Volume = because of the large amount of data, storing data on a single machine is impossible. How can we process data across multiple machines assuring fault tolerance?
Variety= How can we deal with data coming from varied sources which have been formatted using different schemas?
Velocity = How can we quickly store and process new data?
Big Data can be analysed using two different processing techniques:
- Batch processing= usually used if we are concerned by the volume and variety of our data. We first store all the needed data and then process it in one go (this can lead to high latency). A common application example can be calculating monthly payroll summaries.
- Stream processing = usually employed if we are interested in fast response times. We process our data as soon as is received (low latency). An application example can be determining if a bank transaction is fraudulent or not.
Big Data can be processed using different tools such as MapReduce, Spark, Hadoop, Pig, Hive, Cassandra and Kafka. Each of these different tools has its advantages and disadvantages which determines how companies might decide to employ them [2].
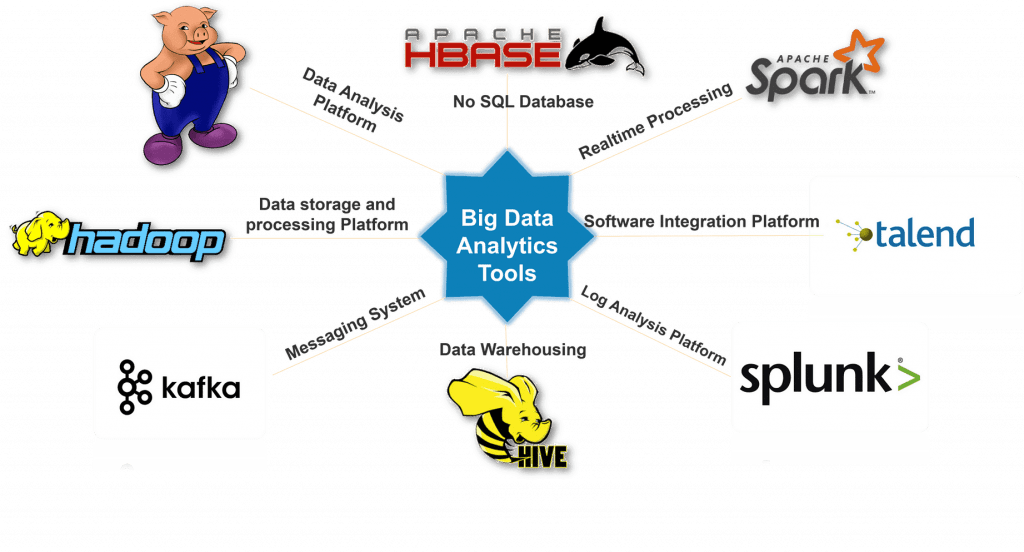
Big Data Analysis is now commonly used by many companies to predict market trends, personalise customers experiences, speed up companies workflow, etc…
MapReduce
When working with a large amount of data and we run out of resources there are two possible solutions: scaling horizontally or vertically.
In horizontal scaling, we solve this problem by adding more machines of the same capacity and distributing the workload. If using vertical scaling we instead scale by adding more computational power to our machine (eg. CPU, RAM).
Vertical scaling is easier to manage and control than horizontal scaling and is proved to be efficient if working with a relatively small size problem. Although, horizontal scaling is generally less expensive and faster than vertical scaling when working with a large problem.
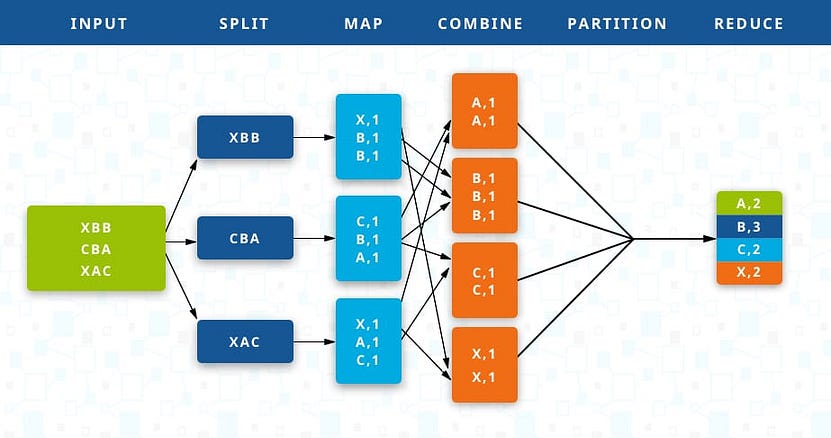
MapReduce is based upon horizontal scaling. In MapReduce, a cluster of computers is used for parallelization making so easier to handle Big Data.
In MapReduce, we take the input data and divide it into many parts. Each part is then sent to a different machine to be processed and finally aggregated according to a specified groupby function.
Apache Spark
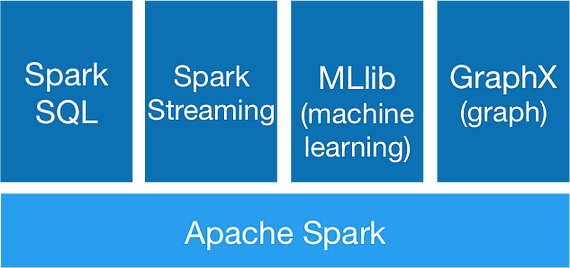
The Apache Spark framework has been developed as an advancement of MapReduce. What makes Spark stand out from its competitors is its execution speed, which is about 100 times faster than MapReduce (intermediated results are not stored and everything is executed in memory).
Apache Spark is commonly used for:
-
- Reading stored and real-time data.
- Preprocess a large amount of data (SQL).
Analyse data using Machine Learning and process graph networks.
When using Spark our Big Data is parallelizedusing Resilient Distributed Datasets (RDDs). RDDs are Apache Spark’s most basic abstraction, which takes our original data and divides it across different clusters (workers). RRDs are fault tolerant, which means they are able to recover the data lost in case any of the workers fail.
RDDs can be used to perform two types of operations in Spark: Transformations and Actions (Figure 4).
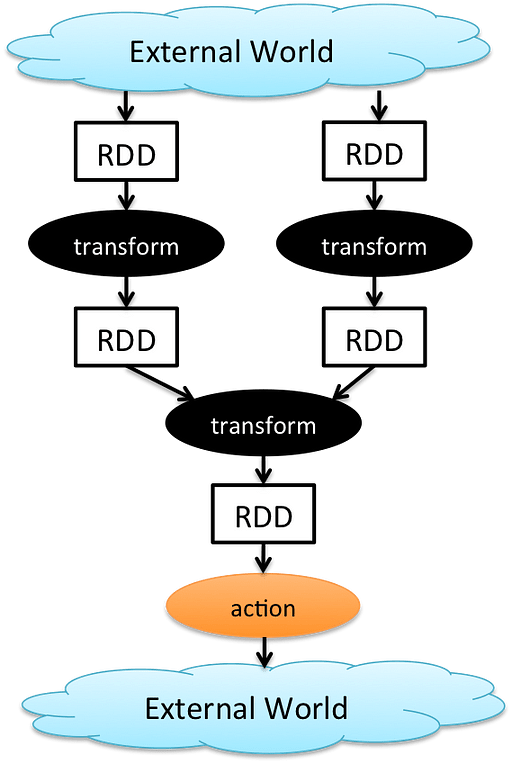
Transformations create new datasets from RDDs and returns as result an RDD (eg. map, filter and reduce by key operations). All transformations are lazy, they are executed just once when an action is called (they are placed in an execution map and then performed when an Action is called).
Actions are instead used to get our analysis results out of Apache Spark and return a value to our Python/R application (eg. collect and take operations).
In order to store key/value pairs in Spark, Pair RDDs are used. Pair RDDs are formed by two RRDs stored in a tuple. The first tuple element is used to store the key values and the second one to store value elements (key, value).
Hadoop
Hadoop is a set of open source programs written in Java which can be used to perform operations on a large amount of data. Hadoop is a scalable, distributed and fault tolerant ecosystem. The main components of Hadoop are [6]:
Hadoop YARN = manages and schedules the resources of the system, dividing the workload on a cluster of machines.
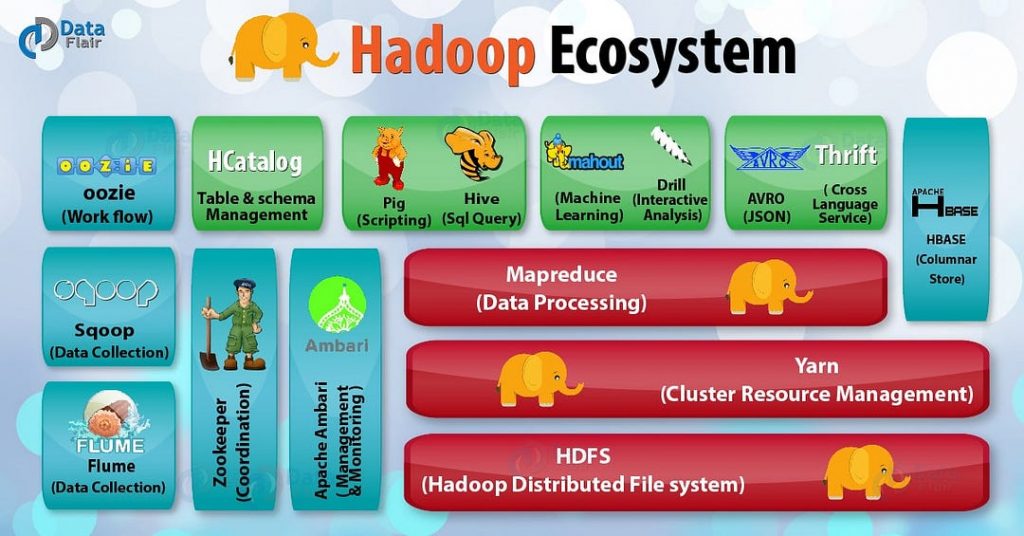
Some application examples of Hadoop are: search (eg. Yahoo), log processing/Data warehouse (eg. Facebook) and Video/Image Analysis (eg. New York Times).
Hadoop has traditionally been the first system to make MapReduce available on a large scale, although Apache Spark is nowadays the framework of preference by many companies thanks to it’s greater execution speed.
Conclusion
The term Big Data has initially been coined to describe a problem: we are generating more data than we can actually process. After years of research and technology advancements, Big Data is instead now seen as an opportunity. Thanks to Big Data recent advancements in Artificial Intelligence and Deep Learning have been possible, enabling machines to perform tasks which seemed to be impossible to perform just a few years ago.
Bibliography
1] What is Big Data? — A Beginner’s Guide to the World of Big Data. Anushree Subramaniam, edureka! . Accessed at:https://www.edureka.co/blog/what-is-big-data/
[2] See some Best-Known Big Data tools, their Advantages and Disadvantages to Analyze your Data. House of Bots. Accessed at: https://www.houseofbots.com/news-detail/12023-1-see-some-best-known-big-data-tools,-there-advantages-and-disadvantages-to-analyze-your-data<
[3] What is MapReduce?. Shana Pearlman, talend. Accessed at: <a href=”https://www.talend.com/resources/what-is-mapreduce/” target=”_blank” rel=”noreferrer noopener”>https://www.talend.com/resources/what-is-mapreduce/</a><
[4] Apache Spark Documentation. Accessed at: https://spark.apache.org/
5] How Apache Spark’s Transformations And Action works…. Alex Anthony, Medium. Accessed at: https://medium.com/@aristo_alex/how-apache-sparks-transformations-and-action-works-ceb0d03b00d0
[6] Apache Hadoop Explained in 5 Minutes or Less. CREDERA, Shravanthi Denthumdas. Accessed at: https://www.credera.com/blog/technology-insights/open-source-technology-insights/apache-hadoop-explained-5-minutes-less/
[7] Hadoop Ecosystem and Their Components — A Complete Tutorial. Data Flair. Accessed at: https://data-flair.training/blogs/hadoop-ecosystem-components/



