Read about the actual work of a Data Scientist. Spoiler alert: It’s nothing like kaggle.
The online world to help students and enthusiasts prepare for the work as a Data Scientist is vast. There is a plethora of ways to access data and to get information. One could think that creating value from Data Science is as easy as spinning up a Jupyter Notebook and changing a few lines of code. All you have to do is to take a few online courses, and it’s all rainbows and unicorns.

Photo by Boudewijn Huysmans on Unsplash
This post aims to shed light on the opportunities as well as unconventional challenges you might encounter when working as a Data Scientist. You will walk through a real-world use-case and get a more realistic view of the job of a Data Scientist. Spoiler alert: it’s not all rainbows and unicorns.

The Problem
Every Data Science project starts with a problem you aim to solve. It’s important to keep this in mind. Too often, Data Scientists run around looking to solve problems with Machine Learning. It should be the other way around.
First comes the problem, second comes the Data Science.
Our use-case starts with a radical change in the legal landscape. The introduction of the European Union (EU) General Data Protection Regulation (GDPR) in 2018 affected more industries than just online marketing. GDPR aims at strengthening the privacy rights of individuals in the EU. The regulation is widely hailed by privacy advocates and equally alienated in the industry.

Companies generally struggle to interpret how GDPR will be applied in specific use-cases because there aren’t any exemplary rulings yet. In its essence, GDPR requires companies to give individuals the right to request and delete their data. In addition, companies should only collect the data needed for a specific, pre-determined use-case. GDPR prohibits unnecessary hoarding of personal data. The legislation introduces heavy uncertainties since the actual limits of enforcement yet remain to be explored.

This is you, the wandering Data Science unicorn. Photo by Andrea Tummons on Unsplash
Now imagine a self-driving car roaming the streets in the EU. They often record their environment with cameras. Per definition, faces and license plates count as personal data and need to be protected. How are car manufacturers supposed to drive around without unintendedly collecting faces and license plates of individuals? Some would say it’s almost impossible. Here we have identified an issue that is relevant to our partners. We also believe that Machine Learning can bring a solution. Let’s develop the use-case.
The Use-Case
Automotive companies need to collect real-world data without infringing GDPR protected personal data rights. There are many ways to solve this: only drive in areas without humans or cars, only collect data at night, rely entirely on simulated data, etc. None of these solutions are ideal. Data-driven function development requires real-world data, without constraints.
We could detect faces and license plates and anonymize them. Technically speaking this would be pseudo-anonymization, but due to abbreviation, we will stick to anonymization in this article.

He is anonymized.
You might notice that we haven’t even spoken of using Machine Learning yet! How we should solve this problem relies entirely on finding the best method, which doesn’t necessarily need to be Machine Learning driven.
We understand that there is a need to anonymize individuals in images and video to protect their privacy. After conducting some research, we can show that Deep Learning is the state-of-the-art approach to accurately detect objects in images. Let’s define the bounds of the project next.
The main goal is to focus on the anonymization of human faces recorded from outside car cameras. First, we need to detect faces in an image. Second, we will replace the face with a mask. There are other ways to replace the face, e.g. with a synthetic face, but we won’t get into it in this post.
Defining the Goal
A Machine Learning product is of little value if it stands for itself. Very often, you will integrate your model into an existing pipeline or build a pipeline around the product. The current engineering go-to framework is to build microservices. Microservices handle only the isolated task that they are designed to do. They are easily integrated into existing architectures. Standard tools to do that are Python Flask and Docker containers. This is what we want.
To formalize our approach, we vouch to use Objectives and Key Results (OKRs). We learned in this post about the benefits of using OKRs to steer our Data Science project, so we come up with the following goals:

These OKRs are ambitious stretch-goals for the full-blown face anonymization project. Later in this post, we will see that the scope of the project is limited to a prototype and thus the OKRs should change as well.
Creating a Project
No matter where you work as a Data Scientist, you always work together in a group with other stakeholders. Before we can get started with our work, we need to take the first hurdle and create a project pitch to convince our partners. We aim to get a Data Scientists for some time to work on this project to prototype a solution.
Management is well aware of the data privacy issue. After all, they are responsible that the company is adhering to the legal requirements. It also makes intuitive sense to anonymize the content of images! In a small pitch, we use the above-defined OKRs together with a persuasive story to convince management to sponsor a prototype solution as a project. If it’s promising enough, we will look for more partners and take the project to the next level.

Photo by Steve Johnson on Unsplash
Congratulations! We got ourselves a Machine Learning project. Now, let the fun begin.
The Work
Deep Learning Guru Andrew Ng recommends to come up with a working model as quickly as possible and then to iterate the idea until the goal is met. Andrew recommends starting to experiment with existing pre-trained models before adjusting them to fit our specific use-case.
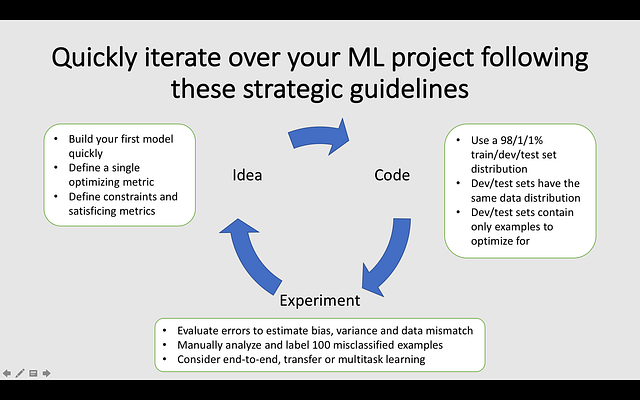
If we look at our OKRs, we realize we need to take three steps: research available face detection models, gather data, and compare the performance of different models. Let’s start with the first part.
Researching available Models
Face detection has been a vital part of computer vision researcher for many decades already. Our assumption is that finding a good model to detect faces should be easy. Open-source packages like OpenCV offer built-in face detection models from the get-go.
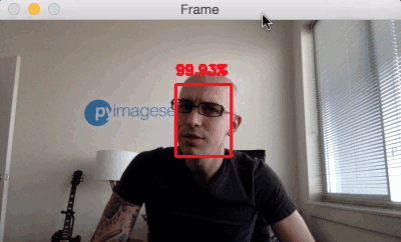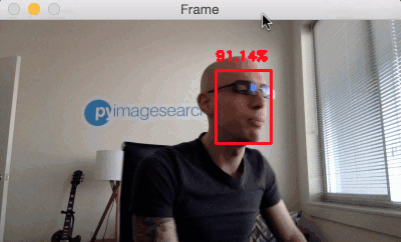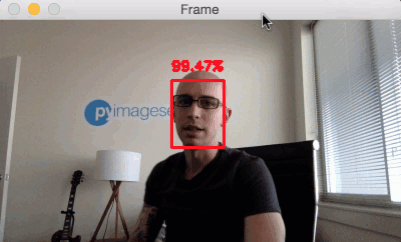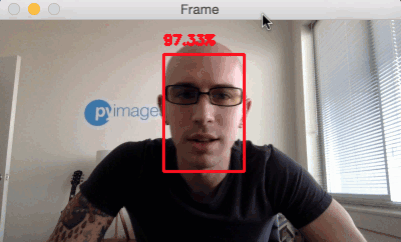
Hi there, Adrian! Check out PyImageSearch for more great OpenCV tutorials.
The downside is, however, that many face detection models focus on identifying faces which are close to the camera. In our automotive context, it’s too late of we recognize faces when they are right in front of the camera!

Too late if you recognize the face just now!
Additionally, cars on the road will record faces with occlusions like hats and sunglasses, in dim light conditions and from different poses. Thus, we should focus our research on models that satisfy these needs.
We analyze recent research papers on state-of-the-art face detection models and get clues from these papers about other existing models. One particular model catches our eye: the Tiny Faces model!

Apparently, the model is trained on a dataset which includes faces in different poses, lighting conditions, with occlusions and with a focus in small, distant faces. It looks very fitting to our use-case.
Licensing — The sleeping Beast
Researchers have it easy — licenses for released datasets or models are generally available for scientific purposes. Sparetime kagglers also don’t have to consider licenses, as they just try out models for personal use. However, this changes when you work for a profit-generating company. Suddenly, many data sets or models are taboo!
As a tip, if you read about a model license and it says “not for commercial purposes”, the model is pretty much out of reach for you. You can’t even test it out for an internal prototype. Let’s forget about this model and research some pre-trained more industry-friendly models.
Gathering the Data
After we’ve identified suitable models, it’s time to let them loose on real-world data. Since we’re working in the automotive industry, we can be sure to have access to vast amounts of clean and labeled data!
Not so fast, rookie. If you’re not working in a start-up, chances are high that your company is divided into different brands and subsidiaries with many subdivisions whose organization changes frequently. Additionally, GDPR makes it more difficult to share data between departments for different use-cases. As you can imagine, finding the right dataset is equal to finding a needle in a haystack!

Go ahead, find the needle. Photo by Lucas Gallone on Unsplash
So we don’t really have the data we need. This might seem outrageous to the reader, but not having the right data is one of the most common reasons why Data Science projects fail, regardless of the company you work for.
There is a great public dataset called WIDER Face. Unfortunately, the licensing beast strikes here again. Google published its Open Images dataset which contains many labeled human faces and is free for commercial use. The images are still not the real-world data that we need our model to perform well on.
Thus, the only way we can proceed is to collect our own dataset. Luckily, we have the equipment to gather real-world data that we want to do well on. Let’s take a spin and collect some data of pedestrians in a controlled environment.
Apply the Models
Now that we have collected some data, its time to try out the models. We have spent most of the time researching models and collecting data, so we don’t have enough time to label the dataset. How can we escape this misery? We help ourselves with approximations like comparing the detected face count and good ol’ intuitions about which model performs better.
This should do for an intermediate result though. The performance shows a winner, so we collect another more realistic dataset and create a showcase video as our result. We try out a few more things like hyperparameter tuning to get rid of too many false positives to improve the showcase, but the time is ticking for this project. We containerize the code present our results.

We’re done with our project! We show that face detection to protect GDPR data in the automotive industry works. Next, we have to convince other stakeholders and partners to sponsor the full project for which we have gathered the OKRs above. The next steps could include license plate detection, hyperparameter tuning, preparing a proper dataset, collecting more data, etc. Shortly after the project, the tremendous folks from understand.ai open-sourced their anonymization code, so we should definitely give this a try as well.
The Conclusion
As you can see, the actual work on this picture pretty use-case is messy. Data is not always available. Be careful when using licenses. Funding for your project might be limited to a certain point. Priorities and circumstances change. You have to stay flexible and work within the given time limits, even if you don’t like it.

Photo by Todd Cravens on Unsplash
With this post, I hope I could shed some light on the real-world work of a Data Scientist through a tiny project. The challenges are surely not always the same, but I imagine them to be similar at different companies. Now, you are prepared that the Data Science world is not all rainbows and unicorns.
Key Take-Aways
As a real-world Data Scientist, you should be aware of the following challenges:
- You need to convince management and stakeholders to sponsor your new project
- Check for the right licensing when incorporating existing models or datasets
- Most of the work you’re doing is research and data preparation
- You need to stay within the time scope of the pre-defined project


