Ready to learn Data Science? Browse Data Science Training and Certification courses developed by industry thought leaders and Experfy in Harvard Innovation Lab.
Cross-Validation is an essential tool in the Data Scientist toolbox. It allows us to utilize our data better. Before I present you my five reasons to use cross-validation, I want to briefly go over what cross-validation is and show some common strategies.
When we’re building a machine learning model using some data, we often split our data into training and validation/test sets. The training set is used to train the model, and the validation/test set is used to validate it on data it has never seen before. The classic approach is to do a simple 80%-20% split, sometimes with different values like 70%-30% or 90%-10%. In cross-validation, we do more than one split. We can do 3, 5, 10 or any K number of splits. Those splits called Folds, and there are many strategies we can create these folds with.
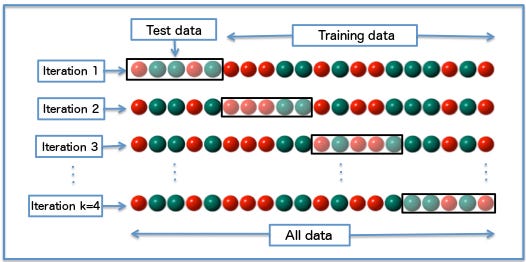
Diagram of k-fold cross-validation with k=4.
Simple K-Folds — We split our data into K parts, let’s use K=3 for a toy example. If we have 3000 instances in our dataset, We split it into three parts, part 1, part 2 and part 3. We then build three different models, each model is trained on two parts and tested on the third. Our first model is trained on part 1 and 2 and tested on part 3. Our second model is trained to on part 1 and part 3 and tested on part 2 and so on.
Leave One Out — This is the most extreme way to do cross-validation. For each instance in our dataset, we build a model using all other instances and then test it on the selected instance.
Stratified Cross Validation — When we split our data into folds, we want to make sure that each fold is a good representative of the whole data. The most basic example is that we want the same proportion of different classes in each fold. Most of the times it happens by just doing it randomly, but sometimes, in complex datasets, we have to enforce a correct distribution for each fold.
Here are my five reasons why you should use Cross-Validation:
1. Use All Your Data

When we have very little data, splitting it into training and test set might leave us with a very small test set. Say we have only 100 examples, if we do a simple 80–20 split, we’ll get 20 examples in our test set. It is not enough. We can get almost any performance on this set only due to chance. The problem is even worse when we have a multi-class problem. If we have 10 classes and only 20 examples, It leaves us with only 2 examples for each class on average. Testing anything on only 2 examples can’t lead to any real conclusion.
If we use cross-validation in this case, we build K different models, so we are able to make predictions on all of our data. For each instance, we make a prediction by a model that didn’t see this example, and so we are getting 100 examples in our test set. For the multi-class problem, we get 10 examples for each class on average, and it’s much better than just 2. After we evaluated our learning algorithm (see #2 below) we are now can train our model on all our data because if our 5 models had similar performance using different train sets, we assume that by training it on all the data will get similar performance.
By doing cross-validation, we’re able to use all our 100 examples both for training and for testing while evaluating our learning algorithm on examples it has never seen before.
2. Get More Metrics

As mentioned in #1, when we create five different models using our learning algorithm and test it on five different test sets, we can be more confident in our algorithm performance. When we do a single evaluation on our test set, we get only one result. This result may be because of chance or a biased test set for some reason. By training five (or ten) different models we can understand better what’s going on. Say we trained five models and we use accuracy as our measurement. We could end up in several different situations. The best scenario is that our accuracy is similar in all our folds, say 92.0, 91.5, 92.0, 92.5 and 91.8. This means that our algorithm (and our data) is consistent and we can be confident that by training it on all the data set and deploy it in production will lead to similar performance.
However, we could end up in a slightly different scenario, say 92.0, 44.0, 91.5, 92.5 and 91.8. These results look very strange. It looks like one of our folds is from a different distribution, we have to go back and make sure that our data is what we think it is.
The worst scenario we can end up in is when we have considerable variation in our results, say 80, 44, 99, 60 and 87. Here it looks like that our algorithm or our data (or both) is no consistent, it could be that our algorithm is unable to learn, or our data is very complicated.
By using Cross-Validation, we are able to get more metrics and draw important conclusion both about our algorithm and our data.
3. Use Models Stacking

Sometimes we want to (or have to) build a pipeline of models to solve something. Think about Neural Networks for example. We can create many layers. Each layer may use previews layer output and learn a new representation of our data so eventually, it will be able to produce good predictions. We are able to train those different layers because we use the back-propagation algorithm. Each layer computes its error and passes it back to the previous layer.
When we do something similar but not using Neural Networks, we can’t train it in the same way because there’s not always a clear “error” (or derivative) that we can pass back.
For example, we may create a Random Forest Model that predicts something for us, and right after that, we want to do a Linear Regression that will rely on previous predictions and produce some real number.
The critical part here is that our second model must learn on the predictionsof our first model. The best solution here is to use two different datasets for each model. We train our Random Forest on dataset A. Then we use dataset B to make a prediction using it. Then we use the dataset B predictions to train our second model (the logistic regression) and finally, we use dataset C to evaluate our complete solution. We make predictions using the first model, pass them to our second model and then compare it to the ground truth.
When we have limited data (as in most cases), we can’t really do it. Also, we can’t train both our models on the same dataset because then, our second model learns on predictions that our first model already seen. These will probably be over-fitted or at least have better results than on a different set. This means that our second algorithm is trained not on what it will be tested on. This may lead to different effects in our final evaluations that will be hard to understand.
By using cross-validation, we can make predictions on our dataset in the same way as described before and so our second’s models input will be real predictions on data that our first model never seen before.
4. Work with Dependent/Grouped Data

When we perform a random train-test split of our data, we assume that our examples are independent. That means that by knowing/seeing some instance will not help us understand other instances. However, that’s not always the case.
Consider a speech recognition system. Our data may include different speakers saying different words. Let’s look at spoken digits recognition. In this dataset, for example, there are 3 speakers and 1500 recordings (500 for each speaker). If we do a random split, our training and test set will share the same speaker saying the same words! This is, of course, will boost our algorithm performance but once tested on a new speaker, our results will be much worse.
The proper way to do it is to split the speakers, i.e., use 2 speakers for training and use the third for testing. However, then we’ll test our algorithm only on one speaker. It is not enough. We need to know how our algorithm performs on different speakers.
We can use cross-validation on the speakers level. We will train 3 models, each time using one speaker for testing and two others for training. This way we’ll be able to evaluate better our algorithm (as described above) and finally build our model on all speakers.
5. Parameters Fine-Tuning

This is one of the most common and obvious reasons to do cross validation. Most of the learning algorithms require some parameters tuning. It could be the number of trees in Gradient Boosting classifier, hidden layer size or activation functions in a Neural Network, type of kernel in an SVM and many more. We want to find the best parameters for our problem. We do it by trying different values and choosing the best ones. There are many methods to do this. It could be a manual search, a grid search or some more sophisticated optimization. However, in all those cases we can’t do it on our training test and not on our test set of course. We have to use a third set, a validation set.
By splitting our data into three sets instead of two, we’ll tackle all the same issues we talked about before, especially if we don’t have a lot of data. By doing cross-validation, we’re able to do all those steps using a single set.
Conclusion
Cross-Validation is a very powerful tool. It helps us better use our data, and it gives us much more information about our algorithm performance. In complex machine learning models, it’s sometimes easy not pay enough attention and use the same data in different steps of the pipeline. This may lead to good but not real performance in most cases, or, introduce strange side effects in others. We have to pay attention that we’re confident in our models. Cross-Validation helps us when we’re dealing with non-trivial challenges in our Data Science projects.


