What is Spark? Let’s take a look under the hood
In my previous post, we introduced a problem: copious, never ending streams of data, and it’s solution: Apache Spark. Here in Part II, we’ll focus on Spark’s internal architecture and data structures.
In pioneer days they used oxen for heavy pulling, and when one ox couldn’t budge a log, they didn’t try to grow a larger ox. We shouldn’t be trying for bigger computers, but for more systems of computers — Grace Hopper
With the scale of data growing at a rapid and ominous pace, we needed a way to process potential petabytes of data quickly, and we simply couldn’t make a single computer process that amount of data at a reasonable pace. This problem is solved by creating a cluster of machines to perform the work for you, but how do those machines work together to solve the common problem?
Meet Spark

Photo by Jez Timms on Unsplash
Spark is the cluster computing framework for large-scale data processing. Spark offers a set of libraries in 3 languages (Java, Scala, Python) for its unified computing engine. What does this definition actually mean?
Unified: With Spark, there is no need to piece together an application out of multiple APIs or systems. Spark provides you with enough built-in APIs to get the job done
Computing Engine: Spark handles loading data from various file systems and runs computations on it, but does not store any data itself permanently. Spark operates entirely in memory — allowing unparalleled performance and speed
Libraries: Spark is comprised of a series of libraries built for data science tasks. Spark includes libraries for SQL (SparkSQL), Machine Learning (MLlib), Stream Processing (Spark Streaming and Structured Streaming), and Graph Analytics (GraphX)
The Spark Application
Every Spark Application consists of a Driver and a set of distributed worker processes (Executors).
Spark Driver
The Driver runs the main() method of our application and is where the SparkContext is created. The Spark Driver has the following duties:
- Runs on a node in our cluster, or on a client, and schedules the job execution with a cluster manager
- Responds to user’s program or input
- Analyzes, schedules, and distributes work across the exectors
- Stores metadata about the running application and conveniently exposes it in a webUI
Spark Executors
An executor is a distributed process responsible for the execution of tasks. Each Spark Application has its own set of executors, which stay alive for the life cycle of a single Spark application.
- Executors perform all data processing of a Spark job
- Stores results in memory, only persisting to disk when specifically instructed by the driver program
- Returns results to the driver once they have been completed
- Each node can have anywhere from 1 executor per node to 1 executor per core
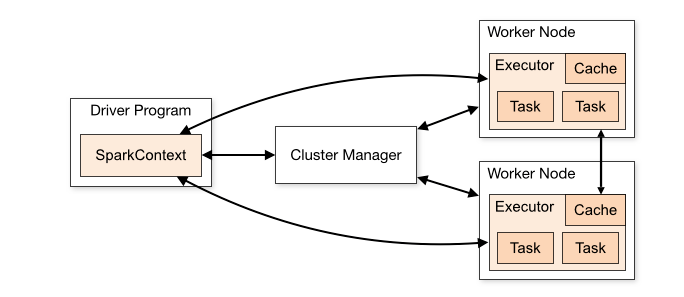
Spark’s Application Workflow
When you submit a job to Spark for processing, there is a lot that goes on behind the scenes.
- Our Standalone Application is kicked off, and initializes its SparkContext. Only after having a SparkContext can an app be referred to as a Driver
- Our Driver program asks the Cluster Manager for resources to launch its executors
- The Cluster Manager launches the executors
- Our Driver runs our actual Spark code
- Executors run tasks and send their results back to the driver
- SparkContext is stopped and all executors are shut down, returning resources back to the cluster
MaxTemperature, Revisited
Lets take a deeper look at the Spark Job we wrote in Part I to find max temperature by country. This abstraction hid a lot of set-up code, including the initialization of our SparkContext, lets fill in the gaps:

MaxTemperature Spark Setup
Remember that Spark is a framework, in this case, implemented in Java. It isn’t until line 16 that Spark needs to do any work at all. Sure, we initialized our SparkContext, however, loading data into an RDD is the first bit of code that requires work be sent to our executors.
By now you may have seen the term “RDD” appear multiple times, it’s about time we define it.
Spark Architecture Overview
Spark has a well-defined layered architecture with loosely coupled components based on two primary abstractions:
- Resilient Distributed Datasets (RDDs)
- Directed Acyclic Graph (DAG)
Resilient Distributed Datasets
RDDs are essentially the building blocks of Spark: everything is comprised of them. Even Sparks higher-level APIs (DataFrames, Datasets) are composed of RDDs under the hood. What does it mean to be a Resilient Distributed Dataset?
Resilient:Since Spark runs on a cluster of machines, data-loss from hardware failure is a very real concern, so RDDs are fault tolerant and can rebuild themselves in the event of failureDistributed:A single RDD is stored on a series of different nodes in the cluster, belonging to no single source (and no single point of failure). This way our cluster can operate on our RDD in parallelDataset:A collection of values — this one you should probably have known already
All data we work within Spark will be stored inside some form of RDD — it is, therefore, imperative to fully understand them.
Spark offers a slew of “Higher Level” APIs built on top of RDDs designed to abstract away complexity, namely the DataFrame and Dataset. With a strong focus on Read-Evaluate-Print-Loops (REPLs), Spark-Submit and the Spark-Shell in Scala and Python are targeted toward Data Scientists, who often desire repeat analysis on a dataset. The RDD is still imperative to understand, as it’s the underlying structure of all data in Spark.
An RDD is colloquially equivalent to: “Distributed Data Structure”. A JavaRDD<String> is essentially just a List<String> dispersed amongst each node in our cluster, with each node getting several different chunks of our List. With Spark, we need to think in a distributed context, always.
RDDs work by splitting up their data into a series of partitions to be stored on each executor node. Each node will then perform its work only on its own partitions. This is what makes Spark so powerful: If an executor dies or a task fails Spark can rebuild just the partitions it needs from the original source and re-submit the task for completion.
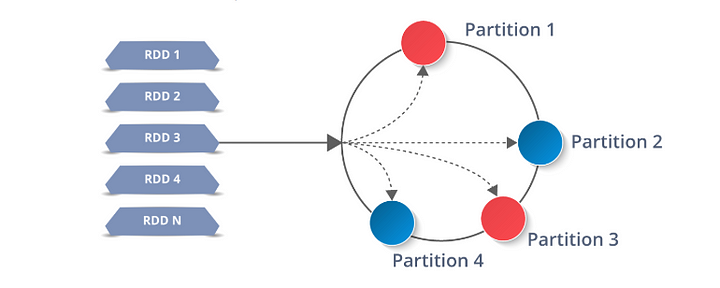
Spark RDD partitioned amongst executors
RDD Operations
RDDs are Immutable, meaning that once they are created, they cannot be altered in any way, they can only be transformed. The notion of transforming RDDs is at the core of Spark, and Spark Jobs can be thought of as nothing more than any combination of these steps:
- Loading data into an RDD
Transformingan RDD- Performing an
Actionon an RDD
In fact, every Spark job I’ve written is comprised of exclusively those types of tasks, with vanilla Java for flavour.
Spark defines a set of APIs for working with RDDs that can be broken down into two large groups: Transformations and Actions.
Transformations create a new RDD from an existing one.
Actions return a value, or values, to the Driver program after running a computation on its RDD.
For example, the map function weatherData.map() is a transformation that passes each element of an RDD through a function.
Reduce is an RDD action that aggregates all the elements of an RDD using some function and returns the final result to the driver program.
Lazy Evaluation
“I choose a lazy person to do a hard job. Because a lazy person will find an easy way to do it. — Bill Gates”
All transformations in Spark are lazy. This means that when we tell Spark to create an RDD via transformations of an existing RDD, it won’t generate that dataset until a specific action is performed on it or one of its children. Spark will then perform the transformation and the action that triggered it. This allows Spark to run much more efficiently.
Let’s re-examine the function declarations from our earlier Spark example to identify which functions are actions and which are transformations:
16: JavaRDD<String> weatherData = sc.textFile(inputPath);
Line 16 is neither an action or a transformation; it’s a function of sc, our JavaSparkContext.
17: JavaPairRDD<String, Integer> tempsByCountry = weatherData.mapToPair(new Func.....
Line 17 is a transformation of the weatherData RDD, in it we map each line of weatherData to a pair comprised of (City, Temperature)
26: JavaPairRDD<String, Integer> maxTempByCountry = tempsByCountry.reduce(new Func....
Line 26 is also a transformation because we are iterating over key-value pairs. its a transformation of tempsByCountry in which we reduce each city to its highest recorded temperature.
Finally, on line 31 we trigger a Spark action: saving our RDD to our file system. Since Spark subscribes to the lazy execution model, it isn’t until this line that Spark generates weather data, tempsByCountry, and maxTempsByCountry before finally saving our result.
Directed Acyclic Graph
Whenever an action is performed on an RDD, Spark creates a DAG, a finite direct graph with no directed cycles (otherwise our job would run forever). Remember that a graph is nothing more than a series of connected vertices and edges, and this graph is no different. Each vertex in the DAG is a Spark function, some operation performed on an RDD (map, mapToPair, reduceByKey, etc).
In MapReduce, the DAG consists of two vertices: Map → Reduce.
In our above example of MaxTemperatureByCountry, the DAG is a little more involved:
parallelize → map → mapToPair → reduce → saveAsHadoopFile
The DAG allows Spark to optimize its execution plan and minimize shuffling. We’ll discuss the DAG in greater depth in later posts, as it’s outside the scope of this Spark overview.
Evaluation Loops
With our new vocabulary, let us re-examine the problem with MapReduce as I defined in Part I, quoted below:
MapReduce excels at batch data processing, however it lags behind when it comes to repeat analysis and small feedback loops. The only way to reuse data between computations is to write it to an external storage system (a la HDFS)”
‘Re-use data between computations’? Sounds like an RDD that can have multiple actions performed on it! Let's suppose we have a file “data.txt” and want to accomplish two computations:
- Total length of all lines in the file
- Length of the longest line in the file
In MapReduce, each task would require a separate job or a fancy MulitpleOutputFormat implementation. Spark makes this a breeze in just four simple steps:
- Load contents of data.txt into an RDD
JavaRDD<String> lines = sc.textFile("data.txt");
2. Map each line of ‘lines’ to its length (Lambda functions used for brevity)
JavaRDD<Integer> lineLengths = lines.map(s -> s.length());
3. To solve for total length: reduce lineLengths to find the total line length sum, in this case, the sum of every element in the RDD
int totalLength = lineLengths.reduce((a, b) -> a + b);
4. To solve for longest length: reduce lineLengths to find the maximum line length
int maxLength = lineLengths.reduce((a, b) -> Math.max(a,b));
Note that steps 3 and 4 are RDD actions, so they return a result to our Driver program, in this case, a Java int. Also recall that Spark is lazy and refuses to do any work until it sees an action, in this case, it will not begin any real work until step 3.
Next Steps
So far we’ve introduced our data problem and its solution: Apache Spark. We reviewed Spark’s architecture and workflow, it’s flagship internal abstraction (RDD), and its execution model. Next, we’ll look into Functions and Syntax in Java, getting progressively more technical as we dive deeper into the framework.


