Information extraction (IE) is a broad area in both the natural language processing (NLP) and the Web communities. The main goal of IE is to extract useful information from raw documents and webpages. For example, given a product webpage, one might want to extract attributes like the name of the product, its date of production, price, and seller.

A few decades ago, such extractors were built painstakingly using rules. In the modern artificial intelligence (AI) community, IE is done using machine learning. Supervised machine learning methods take a training set of webpages, with gold standard extractions, and learn an IE function based on statistical models like conditional random fields and even deep neural nets.
Traditional IE, assumed in our article, assumes a particular schema according to which information must be extracted and typed. A schema for e-commerce might include the attributes mentioned earlier, such as price and date. Domain-specific applications, such as human trafficking, generally require the schema to be specific and fine-grained, supporting attributes of interest to investigators, including phone number, address and also physical features such as hair color and eye color.

The analysis of information related to human trafficking information has proven difficult through the lens of natural language processing.
Image by Free-Photos from Pixabay
AI is not a solved problem, and IE has proven to be a difficult problem in the NLP community for non-traditional domains like human trafficking. Unlike ordinary domains, such as news and e-commerce, training and evaluation datasets for human trafficking IE are not available, and it is also not straightforward to collect such labeled datasets using traditional methods like crowdsourcing, due to the sensitivity of the domain.
While minimally supervised or even unsupervised IE (which only require a few, or even no, labels) can be used, especially with a good sprinkling of domain knowledge, the problem of evaluation remains. Simply put: how can one know whether the IE is good enough without a large, labeled dataset?
The conventional answer is that this is not possible. But we argue that, given a sufficiently large set of documents over which an IE program has been executed, we can use the dependencies between extractions to reason about IE performance.
What do we mean by ‘a dependency?’
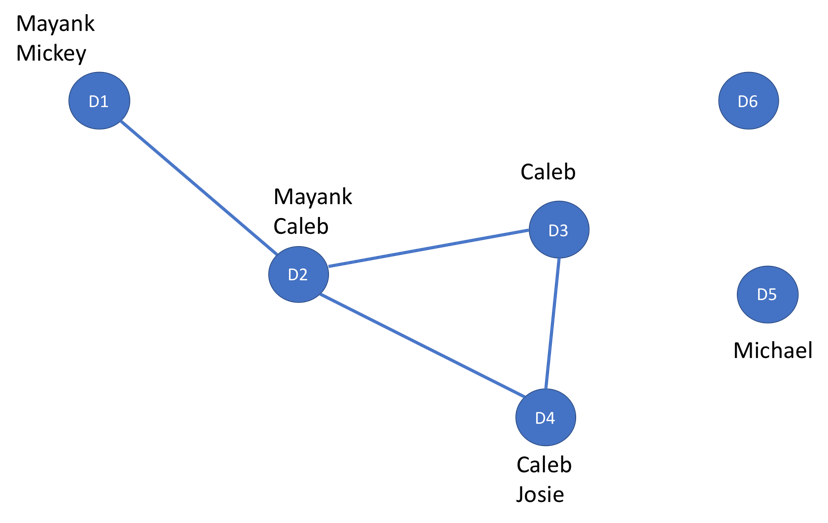
An example of an attribute extraction network, assuming the attribute Name. Vertices are documents.
Consider the network illustrated in the figure above. In this kind of network, called attribute extraction network (AEN), we model each document as a node. An edge exists between two nodes if their underlying documents share an extraction (in this case, names). For example, documents D1 and D2 are connected by an edge because they share the extraction ‘Mayank.’ Note that constructing the AEN only requires the output of an IE, not a gold standard set of labels.
Our primary hypothesis in the article was that, by measuring network-theoretic properties (like the degree distribution, connectivity, etc.) of the AEN, correlations would emerge between these properties and IE performance metrics like precision and recall, which require a sufficiently large gold standard set of IE labels to compute. The intuition is that IE noise is not random noise and that the non-random nature of IE noise will show up in the network metrics. Why is IE noise non-random? We believe that it is due to ambiguity in the real world over some terms, but not others.
For example, ‘Charlotte’ is a more ambiguous location term than ‘London,’ since Charlotte is the name of a (fairly well known) city in the US state of North Carolina, whereas London is predominantly used in a location context (though it may occasionally emerge as someone’s name). The hypothesis is that, if an IE system mis-extracts Charlotte from a document once, it will (all things equal) mis-extract it from other documents as well. In other words, IE mistakes are not random incidents. By mapping IE outputs as a network, we are able to quantify the non-random nature of these mistakes and estimate the performance of the IE on the dataset as a whole.
Because we had access to such a gold standard set, painstakingly constructed by social scientists over millions of sex advertisements scraped from the Internet, we were able to study these correlations across three important attributes (names, phone numbers, and locations) and determine that such correlations do exist, especially for the precision metric.
In our experiments, we construct an AEN for each extraction class of interest, such as a separate AEN is constructed for phone number extractions, name extractions (as in the figure, etc.) In the future, an interesting line of work that we are looking into is to construct a multi-network where all the extractions are modeled jointly in a single multi-class. Our hypothesis is that our results and predictions can be improved even further by considering such joint models.
The takeaway of this work is that, in AI systems that exhibit dependencies, ours may be an exciting methodology for studying the performance of these systems. Historically, network science has been used primarily for the study of ‘non-abstract’ interactions that are typically amenable to observations such as friendships, co-citations, and protein-protein interactions. In contrast, the AEN is a highly abstract network of an IE system’s outputs, albeit still based on actual observations. However, its consequences are very real: it can be used to compare and (approximately) evaluate systems without an actual, painstakingly acquired ground truth.



