Ready to learn Data Science? Browse courses like Data Science Training and Certification developed by industry thought leaders and Experfy in Harvard Innovation Lab.
How Data Curation Can Enable More Faithful Data Science (In Much Less Time)

Thomas Piketty’s monumental Capital in the Twenty-First Century has deep challenges and lessons beyond the world of economics.
In adhering to strict economic principles Piketty achieved the nearly impossible with no guidance from Data Science let alone tools. He instinctively followed many as-yet unwritten principles of this emerging field. As an unwitting Data Science pioneer, Piketty’s work took a decade. Following his model, emerging data curation tools may enable others to achieve similar results in two years or less.
Let’s look at his challenge:
For each of his many hypotheses in his ~700-page book, Piketty had to:
- Discover, ingest, clean, analyze, transform, consolidate, enrich / interpolate and validate relevant economic data …
- From ~200 external, official data sources with incomplete schemas and minor data heterogeneity …
- To form meaningful, consolidated, and curated target data set that met functional and data governance requirements (e.g., veracity, data quality and significance) for the hypothesis.
For Piketty, faithful data science here was a dynamic process, requiring him to explore, acquire and curate the data he needed; model and verify it; modify his hypothesis and all the data that went with it; document its provenance; and then and only then publish it.
Rigorous? Yes. Protracted? Yup – a decade. Worth it? Absolutely, especially in the context of the data controversy that ensued.
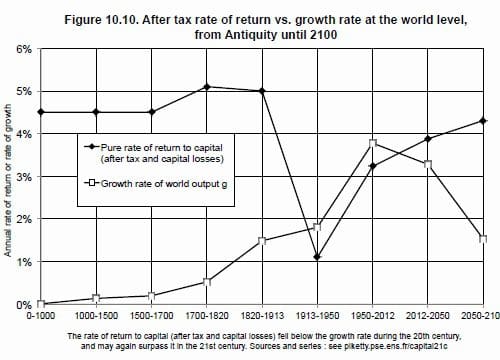
Typically, debates about science, medicine and economics focus around modelling and the related assumptions. However, the rapidly growing role, use, and value of Big Data adds Data Science to the debate, and whether the appropriate scientific, statistical and economic methods were followed in conducting the research. Specifically, did the Data Curation – the discovery, analysis and combination of data sources into a curated data set for use in the analysis – achieve the veracity, data quality and significance requirements of the economic analysis? Does the data curation provenance demonstrate that adequate data governance was applied?
Let’s address these questions through the example of economics.
Computational Economics (a term coined or at least endorsed by Piketty, joining Computational Biology, Computational Social Science and many more) should be based on sound data science principles just as scientific experiments are based on the principles of the scientific method.
Piketty’s work is an example of using computational economics to test collections of economic hypotheses against available data. Good data science practice in these cases involves determining data requirements from the economic hypotheses including the veracity, data quality, and significance requirements. These controls, as they are called in physical science experiments and clinical studies, are derived from the model, the intended analysis, and should be verified together with the model and the intended analysis by expert economists. The economic analysis proceeds in two steps: data curation and data analysis.
As the Piketty data controversy illustrates, raw data sources are seldom in a form required for analysis. Raw data sources are replete with errors, inconsistencies, and gaps and must be augmented and combined to meet the requirements of the analysis. The economic facts that are analyzed are those curated from the raw data sources.
The data curation step involves discovering, analyzing, cleaning, transforming, combining, and de-duplicating data sources to produce target data sources that meet the requirements for input to the analysis. Every data curation step should be documented as data provenance that is then compared against the controls to determine the extent to which the appropriate data governance was followed and the required data quality was achieved.
All of this must be verified by reviewers, supporters and detractors alike. The analytical results should be accompanied by the measures of data quality supported by the data provenance, and data governance, hence the extent to which the requirements were met. Variations from the requirements should be considered in establishing a level of confidence in the analytical results.
Data provenance that demonstrates sound data science principles and data curation practices offers the best transparency for a worthy economic theory. Anything less can be assumed to conceal poor data practices.
In conclusion, as the example of computational economics suggests, data curation (as supported by Tamr) must be thought of as an activity that precedes – as independent of but partnered with – analysis. Approached this way, the analyst has a far better chance to remain faithful to strong data science principles. Alternatively, the analyst may violate the principles of their analysis and domain, in Piketty’s case economics.
Have a look at Piketty’s groundbreaking results in economics and data science.
Previous version published at Tamar


