Ready to learn Data Science? Browse courses like Data Science Training and Certification developed by industry thought leaders and Experfy in Harvard Innovation Lab.
The First in a Series on Deep Learning for Non-Experts
Why read this?
To get started applying Deep Learning, either as an individual practitioner or as a organization, you need two things:
- The “what”: an idea of what the latest developments in Deep Learning are capable of.
- The “how”: the technical capability to either train a new model or take your existing model and get it working in production.
Thanks to the strength of the open source community, the second part is getting easier every day. There are many great tutorials on the specifics of how to train and use Deep Learning models using libraries such as TensorFlow — many of which publications like Towards Data Science publish on a weekly basis.
The implication of this is that once you have an idea for how you’d like to use Deep Learning, implementing your idea, while not easy, involves standard “dev” work: following tutorials like the ones linked throughout this article, modifying them for your specific purpose and/or data, troubleshooting via reading posts on StackOverflow, and so on. They don’t, for example, require being (or hiring) a unicorn with Ph.D who can code original neural net architectures from scratch and is an experienced software engineer.
This series of essays will attempt to fill a gap on the first part: covering, at a high level, what Deep Learning is capable of, while giving resources for those of you who want to learn more and/or dive into the code and tackle the second part. More specifically, I’ll cover:
- What the latest achievements using open source architectures and datasets have been.
- What the key architectures or other insights were that led to those achievements
- What the best resources to get started with using similar techniques on your own projects.
What These Breakthroughs Have in Common
The breakthroughs, while they involve many new architectures and ideas, were all achieved using the usual “Supervised Learning” process from machine learning. Specifically the steps are:
- Collect a large set of appropriate training data
- Set up a neural net architecture — that is, a complicated system of equations, loosely modeled on the brain — that often has of millions of parameters called “weights”.
- Repeatedly feed the data through the neural net; at each iteration comparing the result of the neural net’s prediction to the correct result, and adjusting each of the neural net’s weights based on how much and in what direction it misses.
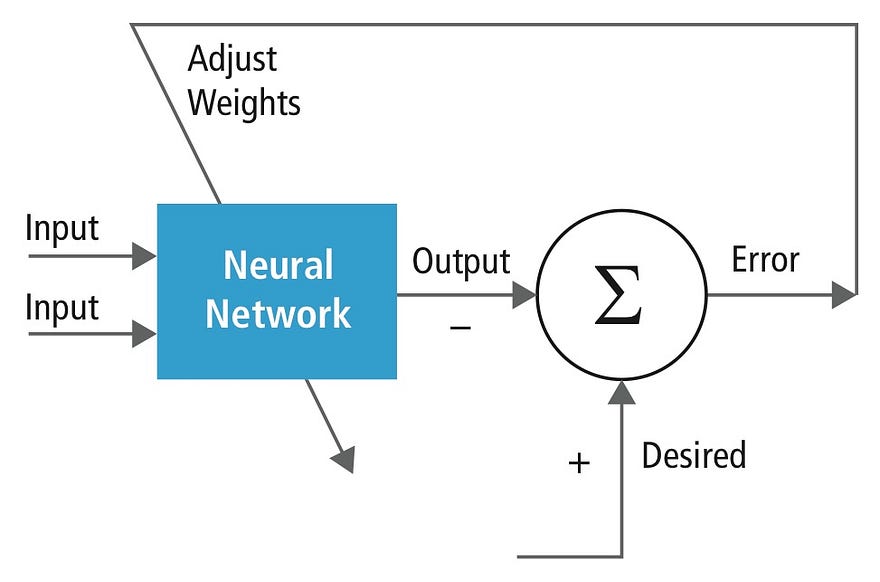
This is how neural nets are trained: this process is repeated many, many times. Source.
This process has been applied to many different domains, and has resulted in neural nets that appear to have “learned”. In each domain, we’ll cover:
- The data needed to train these models
- The model architecture used
- The results
1. Image classification
Neural networks can be trained to figure out what object or objects an image contains.
Data required
To train an image classifier, you need labeled images, where each image belongs to one of a number of finite classes. For example, one of the standard datasets used to train image classifiers is the CIFAR 10 data, which has correctly labelled images of 10 classes:

Illustration of images of CIFAR-10 data. Source
Deep Learning Architecture
All the neural net architectures we’ll cover were motivated by thinking about how people would actually have to learn to solve the problem. How do we do this for image detection? When humans determine what is in an image we first would look for high-level visual features, like branches, noses, or wheels. In order to detect these, however, we would subconsciously need to determine lower level features like colors, lines, and other shapes. Indeed, to go from raw pixels to complex features that humans would recognize, like eyes, we would require detecting features of pixels, and then features of features of pixels, etc.
Prior to Deep Learning, researchers would manually try to extract these features and use them for prediction. Just before the advent of Deep Learning, researchers were starting to use techniques (mainly SVMs) that tried to find complex, nonlinear relationships between these manually-extracted features and whether an image was of a cat or dog, for example.
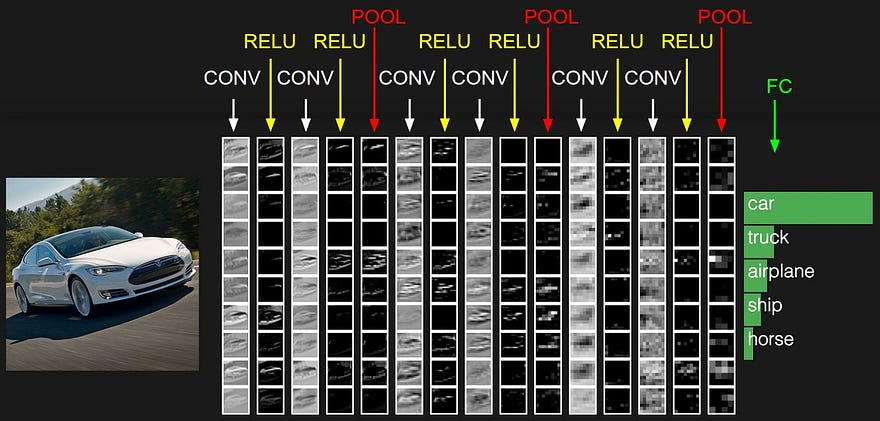
Convolutional Neural Network extracting features at each layer. Source
Now, researchers have developed neural net architectures that learn these features of the original pixels themselves; specifically, Deep Convolutional Neural Net architectures. These networks extract features of pixels, then features of features of pixels and so on, and then ultimately feed these through a regular neural net layer (similar to a logistic regression) to make the final prediction.

Samples of the predictions a leading CNN architecture made on images from the ImageNet dataset.
We’ll dive deeper into how convolutional neural nets are being used for image classification in a future post.
Breakthroughs
The consequence of this is that on the central task these architectures were designed to solve — image classification —algorithms can now achieve better results than humans. On the famous ImageNet dataset, which is most commonly used as a benchmark for convolutional architectures, trained neural nets now achieve better-than-human performance on image classification:
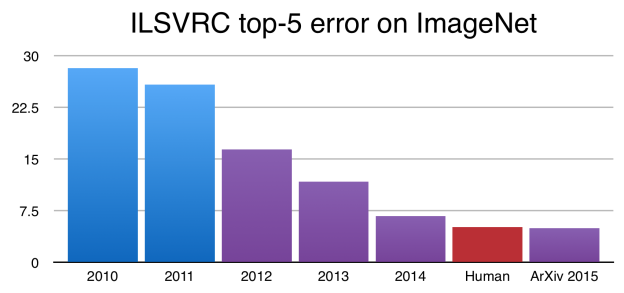
As of 2015, computers can be trained to classify objects in images better than humans. Source
In addition, researchers have figured out how to take images not immediately curated for image classification, segment out rectangles of the image most likely to represent objects of specific classes, feed each of these rectangles through a CNN architecture, and end up with classifications of the individual objects in the image along with boxes bounding their location (these are called “bounding boxes”):

Object detection using “Mask R-CNN”. Source
This entire multi-step process is technically known as “object detection”, though it uses “image classification” for the most challenging step.
Resources
Theoretical: For a deeper look at the theory of why CNNs work, read the tutorial from Andrej Karpathy’s Stanford course here. For a slightly more mathematical version, check out Chris Olah’s post on convolutions here.
Code: To get started quickly building an Image Classifier, check out this introductory example from the TensorFlow documentation.
2. Text Generation
Neural networks can be trained to generate text that mimics text of a given type.
Data required
Simply text of a given class. This could be all the works of Shakespeare, for example.
Deep Learning Architecture
Neural nets can model the next element in a sequence of elements. It can look at the past sequence of characters and, for a given set of past sequences, determine which character is most likely to appear next.
The architecture used for this problem is different than the architecture used for image classification. With different architectures, we are asking the net to learn different things. Before, we were asking it to learn what features of images matter. Here, we are asking it to pay attention to a sequence of characters to predict the next character in a sequence. To do this, unlike with image classification, the net needs a way of keeping track of its “state”. For example, if the prior characters it has seen are “c-h-a-r-a-c-t-e”, the network should “store” that information and predict that the next character should be “r”.
A Recurrent Neural Network architecture is capable of this: it feeds the state of each neuron back into the network during its next iteration, allowing it to learn sequences (there’s a lot more to it than this, but we’ll get into that later).
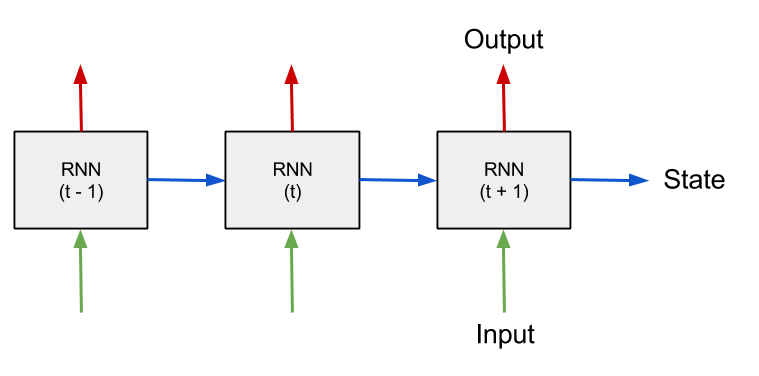
Image of a Recurrent Neural Net architecture. Source.
To really excel at text generation, however, the nets must also decide how far back to look in the sequence. Sometimes, as in the middle of words, the net simply has to look at the last few characters to determine which character comes next, and other times it may have to look back many characters to determine, for example, if we are at the end of a sentence.
There is a special type of cell called an “LSTM” (Long Short Term Memory) cell that does this particularly well. Each cell decides whether to “remember” or “forget” based on weights internal to the cell itself that are updated with each new character that the net sees.
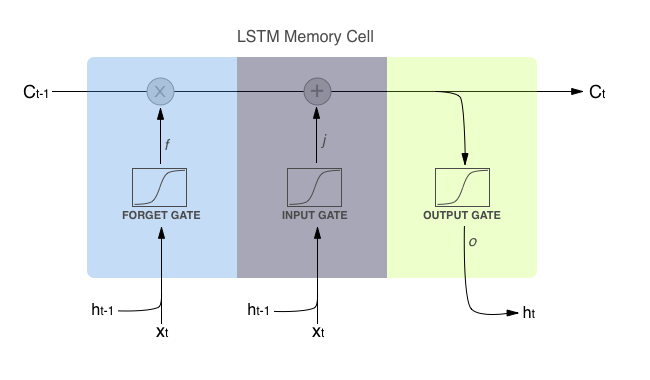
The inner workings of an LSTM cell. Source.
Breakthroughs
In short: we can generate text that looks sort of like a characature of the text we are trying to generate, minus a few mispelled words and mistakes that prevent it from being proper English. This Andrej Karpathy post has some fun examples, from generating Shakespeare plays to generating Paul Graham essays.
The same architecture has been used to generate handwriting by sequentially generating the x and y coordinates, just as language is generated character by character. Check out this demo here.

Written by a neural net. Can we still call it *hand*writing? Source
We’ll dive further into how recurrent neural nets and LSTMs work in a future post.
Resources
Theoretical: This Chris Olah post on LSTMs is a classic, as is this post from Andrej Karpathy on RNNs generally, what they can accomplish, and how they work.
Code: This is a great walkthrough on how to get started building an end-to-end text generation model, including the preprocessing of the data. This GitHub repo makes it easy to generate handwriting using a pretrained RNN-LSTM model.
3. Language Translation
Machine translation — the ability to translate language — has long been a dream of AI researchers. Deep Learning has brought that dream much closer to reality.
Data required
Pairs of sentences between different languages. For example, the pair “I am a student” and “je suis étudiant” would be one pair of sentences in a dataset training a neural net to translate between English and French.
Deep Learning Architecture
As with other deep learning architectures, researchers have “hypothesized” how computers might ideally learn to translate languages, set up an architecture that attempts to mimic this. With language translation, fundamentally, a sentence (encoded as a sequence of words) should be translated into its underlying “meaning”. That meaning should then be translated into a sequence of words in the new language.
The way sentences are “transformed” from words into meaning should be an architecture that is good at dealing with sequences — this turns out to be the “Recurrent Neural Network” architecture described above.

Encoder-decoder architecture diagram. Source
This architecture was first discovered to work well on language translation in 2014 and has since been extended in many directions, in particular with “attention” an idea that we’ll explore in a future blog post.
Breakthroughs
This Google blog post shows that this architecture does indeed accomplish what it set out to accomplish, blowing other language translation techniques out of the water. Of course, it doesn’t hurt that Google has access to such great training data for this task!
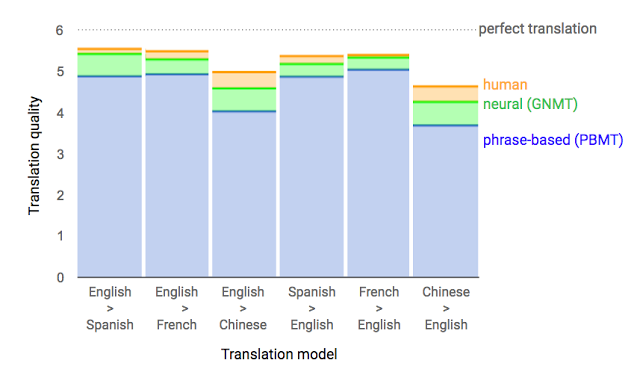
Google Sequence-to-Sequence based model performance. Source
Resources
Code & Theoretical: Google, to their credit, has published a fantastic tutorial on Sequence to Sequence architectures here. This tutorial both gives an overview of the goals and theory of Sequence to Sequence models and walks you through how to actually code them up in TensorFlow. It also covers “attention”, an extension to the basic Sequence-to-Sequence architecture that I’ll cover when I discuss Sequence-to-Sequence in detail.
4. Generative Adversarial Networks
Neural networks can be trained to generate images that look like images of a given class — images of faces, for example, that are not actual faces.
Data required
Images of a particular class — for example, a bunch of images of faces.
Deep Learning Architecture
GANs are a surprising and important result — Yann LeCun, one of the leading AI researchers in the world, said that they are “the most interesting idea in the last 10 years in ML, in my opinion.” It turns out we can generate images that look like a set of training images but are not actually images from that training set: images that look like faces but are not actually real faces, for example. This is accomplished via training two neural networks simultaneously: one that tries to generate fake images that look real and one that tries to detect whether the images are real or not. If you train both of these networks so that they learn “at the same speed” — this is the hard part of building GANs — the network that is trying to generate the fake images actually can generate images that look quite real.
To go into just a bit of detail: the main network that we want to train with GANs is called the generator: it will learn to take in a vector of random noise and transform it into a realistic looking image. This network has an “inverse” structure from a convolutional neural network, aptly named a “deconvolutional” architecture. The other network, that tries to distinguish real from fake images, is a convolutional network just like those used for image classification, and is called the “discriminator”.
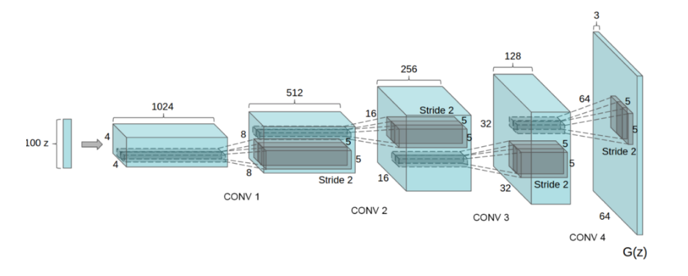
Deconvolutional architecture of a “generator”. Source

Convolutional architecture of the “discriminator”. Source
Both neural nets in the case of GANs are Convolutional Neural Nets, since these neural nets are especially good at extracting features from images.
Breakthroughs & Resources

Images generated by a GAN from a dataset of faces of celebrities. Source
Code: This GitHub repo is both a great tutorial on training GANs using TensorFlow and contains some striking images generated by GANs, such as the one above.
Theoretical: This talk by Irmak Sirer is a fun introduction to GANs, as well as covering many Supervised Learning concepts that will help you understand the findings above as well.
Finally, the excellent Arthur Juliani has another fun, visual explanation of GANs here, along with code to implement one in TensorFlow.
Summary
This was a high level overview of the areas where Deep Learning has generated the biggest breakthroughs over the last five years. Any of these models we discussed has many open source implementations. That means that you can almost always download a “pre-trained” model and apply it to your data — for example, you can download pre-trained image classifiers that you can feed your data through to either classify new images or draw boxes around the objects in images. Because much of this work has been done for you, the work necessary to use these cutting edge techniques is not in “doing the deep learning” itself — the researchers have largely figured that part out for you — but rather in doing the “dev” work to get the models others have developed to work for your problem.
Hopefully now you have a bit of a better understanding of what the capabilities of Deep Learning models are, and are a bit closer to actually using them!


