Ready to learn Data Science? Browse courses like Effective Data Visualization developed by industry thought leaders and Experfy in Harvard Innovation Lab.
You binged online courses and landed your first Data Science job. Avoid these mistakes to be successful right away.
You prepared well to finally become a Data Scientist. You participated in Kaggle competitions and you binge watched online lectures. You feel prepared, but the work as a real-life Data Scientist will prove vastly different from what you might expect.
This article examines 5 common mistakes of early Data Scientists. The list was assembled together with Dr. Sébastien Foucaud, who has >20 years of experience in mentoring and leading young Data Scientists in both academia and industry. This post aims to help you better prepare for your work in real-life.
Let’s get started.
1. Enter “Generation Kaggle”
Source: kaggle.com on June 30 18.
You have participated in Kaggle challenges and practiced your Data Science skills. It’s nice that you can stack decision trees and neural networks. Truth be told, you won’t do quite as much of model stacking as a Data Scientist. Remember as a general rule that you will spend 80% of your time preprocessing data and 20% of the remaining time building your model.
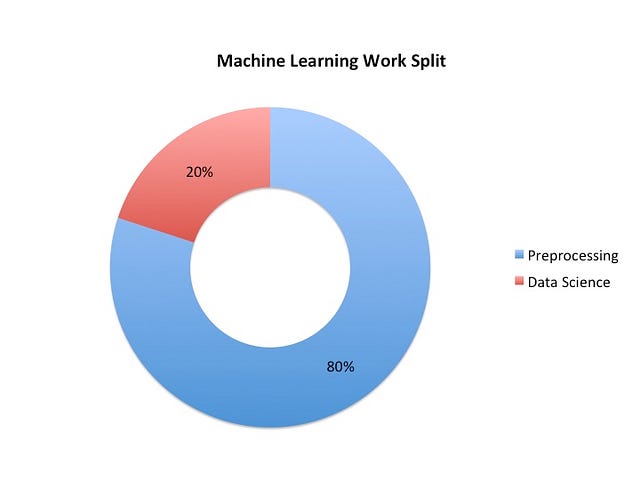
Being part of “Generation Kaggle” is helpful in many ways. The data often comes perfectly cleaned so that you can spend time tweaking your model. But that’s rarely the case in your real world job, where you have to assemble data from different sources with different formats and naming conventions.
Do the hard work and practice the skill you will use 80% of your time, data preprocessing. Scrape images or gather them from an API. Collect song lyrics from Genius. Prepare the data you need to solve a specific problem, then ingest it into your notebook and practice the machine learning life cycle. Being proficient in data preprocessing will undoubtedly make you a Data Scientist with immediate impact at your company.
2. Neural Networks are the cure to everything
Deep Learning models are superior to other machine learning models in the areas of computer vision or natural language processing. But they also have distinct disadvantages.
Neural networks are very data hungry. With less samples, you often fair better with a decision tree or logistic regression model. Neural Networks are also a black box. They are notoriously hard to interpret and to explain. If product owners or managers start to question the output of the model, you have to be able to explain the model. This is much easier for traditional models.
There are many great statistical learning models out there, as explained in this great post by James Le. Educate yourself about them. Know their advantages and disadvantages and apply a model according to the constraints of your use-case. Unless you’re working in the specialized field of computer vision or natural speech recognition, chances are that the most successful models will be traditional machine learning algorithms. You will soon discover that very often the simplest model, like a Logistic Regression, is the best model.
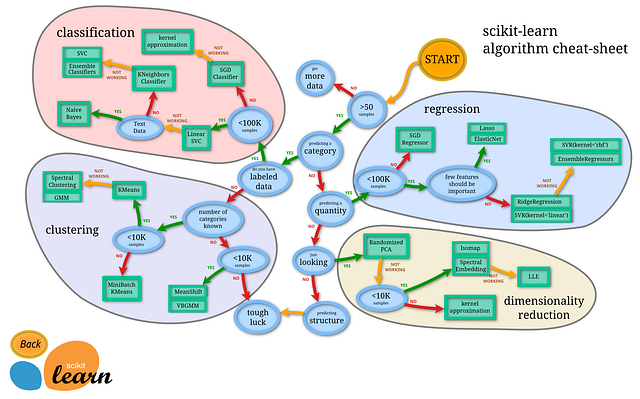
Source: Algorithm cheat-sheet from scikit-learn.org.
3. Machine Learning is the Product
Machine Learning has both enjoyed and suffered tremendous hype in the past decade. Too many start-ups promise Machine Learning to be the cure to any problem there exists.
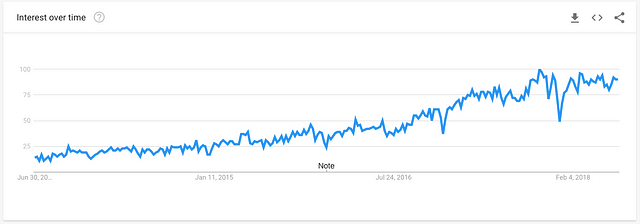
Source: Google Trends for Machine Learning of the past 5 years
Machine Learning itself should never be the product. Machine Learning is a powerful tool to create a product that meets customer demands. If the customer benefits from receiving accurate item recommendations, machine learning can help. If a customer has the need to accurately identify objects in an image, machine learning can help. If the business benefits from presenting valuable ads to its users, machine learning can help.
As a Data Scientist, you need to plan a project with the goal of the customer as your main priority. Only then you evaluate if machine learning can help.
4. Confuse Causation with Correlation
About 90% of data has been produced in the past years. With the emergence of Big Data, data has become vastly available for Machine Learning practitioners. With so much data to evaluate, the chances increase that random correlations are discovered by learning models.
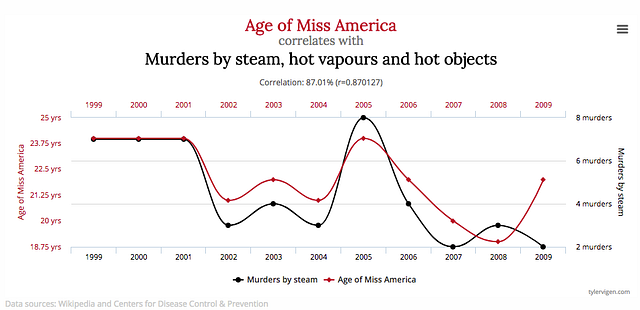
Source: http://www.tylervigen.com/spurious-correlations
The image above shows the age of Miss America and the total number of murders by steam, hot vapours and hot objects. Given that data, a learning algorithm will learn the pattern that the age of Miss America influences the number of murders by certain objects, and vice versa. However, both data points are virtually unrelated and both variables have absolutely no predictive power over the other variable.
When discovering patterns in data, apply your domain knowledge. Is it likely to be a correlation or causation? Answering this questions is key to deriving actions from data.
5. Optimize the wrong metrics
Developing a Machine Learning model follows the agile life-cycle. First, you define the idea and key metrics. Second, you prototype a result. Third, you continually improve until you satisfy the key metric.
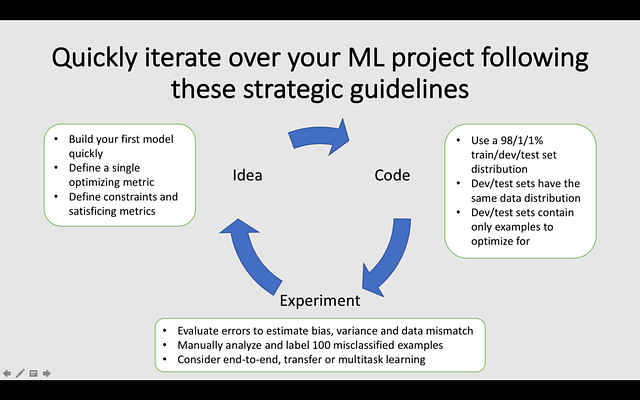
When building a Machine Learning model, remember to do a manual error analysis. While the process is tedious and requires effort, it will help you improve the model efficiently in the following iterations.
Young Data Scientists provide tremendous value to companies. They’re fresh off taking online courses and can provide immediate help. They’re often self-taught, as few universities offer Data Science degrees, and thus show tremendous commitment and curiosity. They’re enthusiastic about the field they’ve chosen and are eager to learn more. Beware of the mentioned pitfalls to succeed in your first Data Science job.
Key takeaways:
- Practice data curation
- Study pros and cons of different models
- Keep the model as simple as possible
- Check your conclusion against causation vs. correlation
- Optimize the most promising metrics


