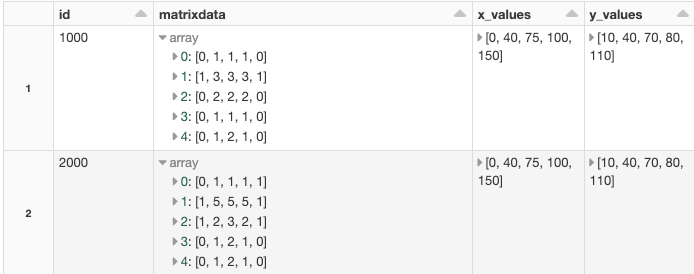
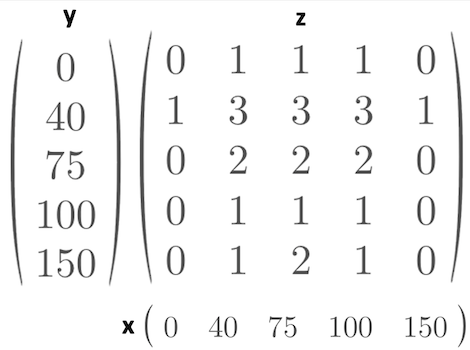
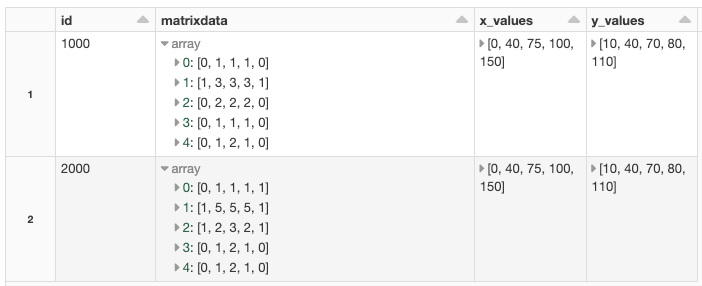
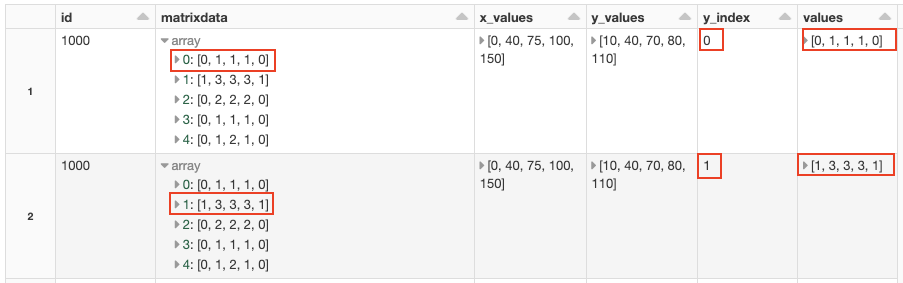

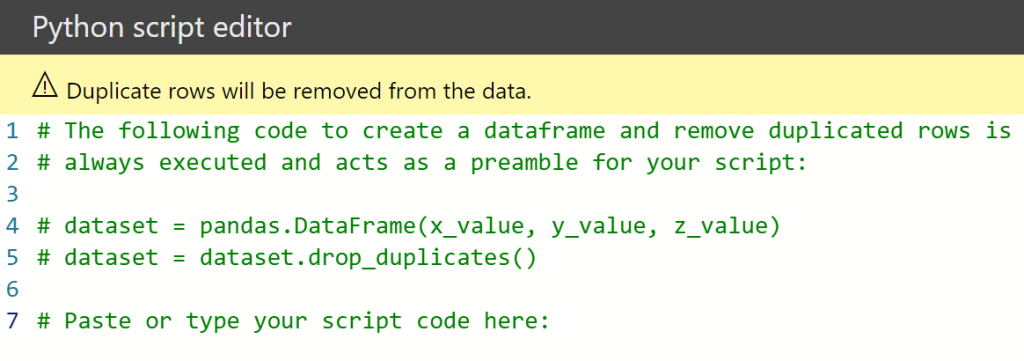
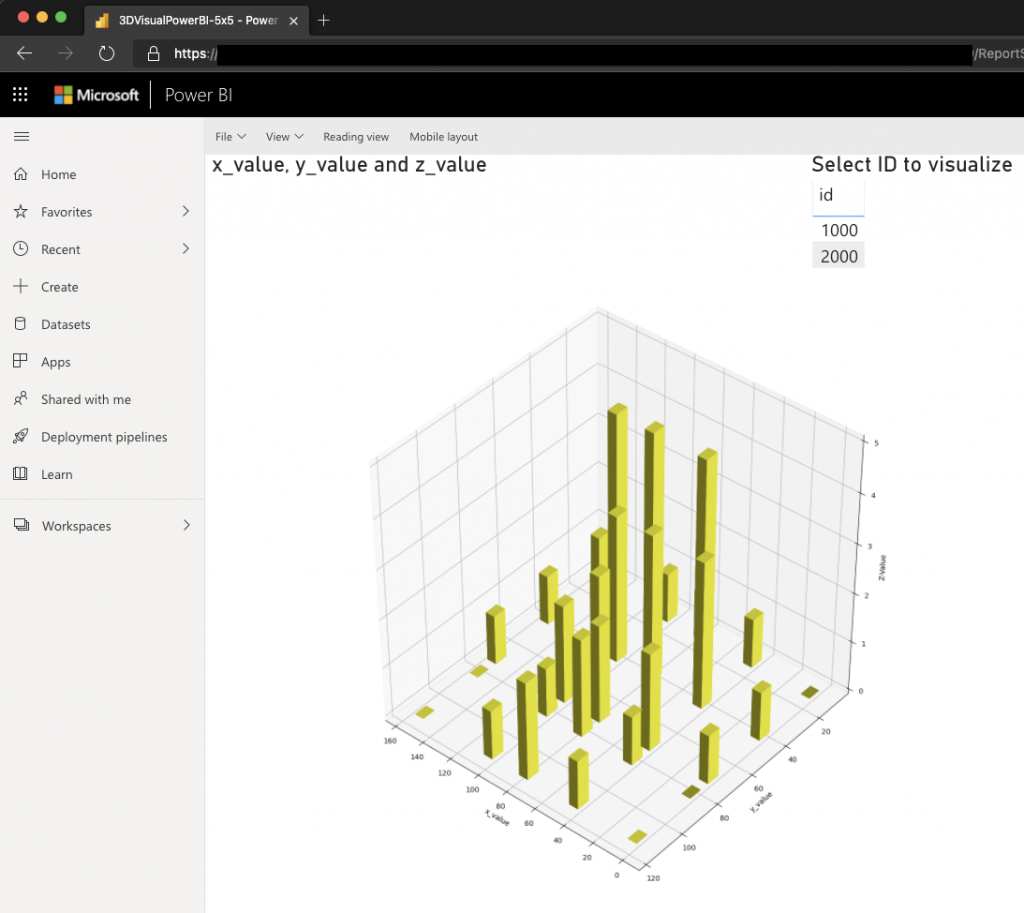
Internet of Things (IoT) gadgets are everywhere. Cars, buildings, roadways, airplanes, home appliances, and other items have tens of billions of sensors, processors, and internet-connected gadgets. IoT devices detect motion, regulate temperature, share and collect data, measure weather, and provide location information, power logistics, and medical research. They also enable self-driving vehicles, to name just
IoT is a powerful economic driver. IoT Innovation is actively shaping businesses and consumer trends. Most of the technologies developed before and during the pandemic address the Internet of Things directly or indirectly. From healthcare and retail to automobile and manufacturing, IoT innovations are opening new avenues across industries. It covers almost every segment of

One of the biggest issues companies face when starting an IoT project is deciding who should be responsible. Should it be the engineering team that is responsible for the core technicalities of the device, or should it be the product management team that is responsible for the end functionalities of the IoT product? Starting on
