16 is by no means a big number. How many MAC units would be required to compute a Convolutional Neural Network (CNN) to produce 16 output channels of a 16×16 tile from 16-deep 3×3 tensor convolution in, say, 64 clocks?
It would take at least 9,216 MAC units if not using a fast algorithm. 9,216 MAC units would commonly be used to construct a 96×96 systolic array, but it takes at least a latency of 96 clocks to calculate a 96×96 matrix multiplication (MM). A long train of 96 96×96 matrix multiplications would be required to keep the systolic array occupied.

Photo by Olav Ahrens Røtneon Unsplash
Welcome to the world of tensors in AI. It is now time to get used to the curse of dimensionality.
Tensors vs. Matrices
The title of this article is inspired by and a counter-response to a quote from Professor Charles F. Van Loan in his lecture on tensor unfoldings in 2010.
All tensors secretly wish that they were matrices!
This statement demonstrates the desire of the tensor research community to study tensors by first unfolding them into matrices and then leveraging well-established matrix-theoretic frameworks to study them. It is also an industry standard practice to flatten tensors all the way to matrices to leverage the highly optimized libraries for matrix multiplication (MM) or MM accelerators (MMAs), even though tensors are considered to be the most fundamental data type in all major AI frameworks. Matrices are generally considered to be special cases of tensors by the AI community.
Here might be what conventional wisdom says:
- There are very nice parallelism and data-sharing patterns in MM to leverage.
- Matrices are a more natural or native fit for programmable hardware than tensor.
- There is a native hardware acceleration solution, the systolic array, for MM.
However,
- CNNs are structurally equivalent to MMs. It is not necessary to flatten tensors to leverage the MM-equivalent parallelism and data-sharing patterns.
- Matrices are recursively blocked for temporal locality and packed for spatial locality while climbing up the memory hierarchy. They finally become micro panels, which are small block rows or columns, to be consumed by a software microkernel or GPU shader kernel.
- In my review of Google’s TPU v1 with 256×256 systolic array, the issue of scalability from the curse of the square shape of a systolic array was addressed. Since then it seems to be mainstream to use multiple relatively smaller systolic arrays. For this reason, matrices must be similarly blocked and packed before they are in the square matrix shape that can be consumed by systolic arrays.
As a result, matrices from flattening out tensors are actually blocked and packed to be in the appropriate structure for high-performance execution as illustrated below. The former can be referred to as flat-unfolding, and the latter as block-unfolding. Matrices become the default data type for CNN and AI in general because of the efforts from decades of researching, building, and leveraging the block matrix framework for high-performance MM implementations.
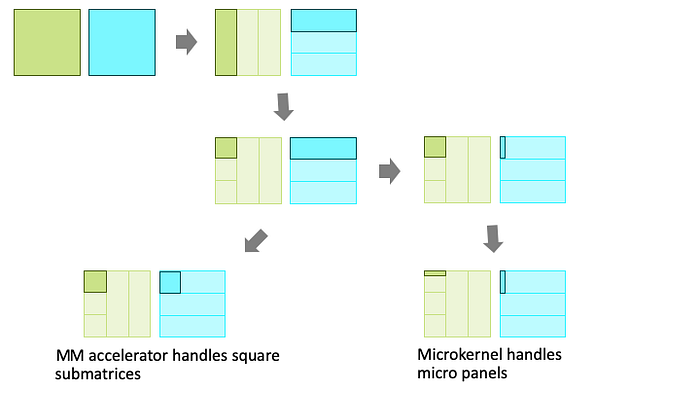
Block-unfolding of a MM
Following the conventional wisdom, a feature map in CNN is coerced to be a column of some matrix and a convolution filter is flattened out to be some consecutive matrix elements in a column. The potential for spatial and temporal reuses of neighboring pixels in a feature map is lost as a result of flat-unfolding.
Block Tensors to the Rescue
One key feature of recursive matrix block-unfolding in MM is that high-level temporal and spatial localities are preserved when the matrices are moving closer to the bare metal of hardware. It should be intriguing to see whether data localities in CNN can be preserved similarly in the tensor form.
It is a reasonable design choice to partition a feature map into tiles and keeping the tiling structure for re-using filters, leveraging fast algorithms for small tiles, and achieving fine-grain SIMD-like parallelism. The tensors should remain as tensors while approaching the bare metal to keep the tiling structure and data locality in a feature map intact.
Furthermore, locality patterns among the input feature maps and output feature maps must be addressed. The former allows data from multiple input feature maps to be shared for the calculation of multiple output feature maps. The latter enables a bigger audience to share the input feature maps. The twist is that you cannot share the whole, and all feature maps since producing an output pixel do not require the whole input feature maps, and it would be impractical to keep all the feature maps on-chip. To conclude, all dimensions need to be partitioned or blocked to some extent, and such a consideration leads to tensors being partitioned into smaller ones and becoming block tensors.
A block tensor is a tensor whose entries are tensors. It is a counterpart of the block matrix.The concept of block tensors can be used to address the curse of dimensionality and preserve the data locality in CNN, similar to how the high-performance computing (HPC) industry adopted the concept of block matrix for MM. Tensor packets, equivalent to micro panels or square submatrices in MM, are defined to be the basic tensor units that must be processed atomically to leverage spatial locality along all dimensions. A tensor block, consisting of tensor packets, is defined as the tensor units that must be transferred between computing units and external memory in their entirety to facilitate temporal locality among the tensor packets.
The atomic tensor packet operation is defined to be producing a minimally sufficient number of output channels of minimally sufficient-sized tiles from a minimally sufficient number of input channels. Due to the curse of dimensionality in tensors, processing such tensor packets could become a big effort even though each tensor packet is small in size in each dimension. It can be iterated or applied concurrently within a tensor block to solve bigger problems. The ideas are elaborated semi-formally in the rest of the post.
CNN in Terms of Block Tensors
Input A and output C of a CNN consist of multiple input feature maps (IFMs), and output feature maps (OFMs), respectively. They can be considered as 3-dimensional tensors, with dimensions x, y for feature maps, input depth w for indexing IFMs, and output depth z for indexing OFMs. In order to achieve fine-grain SIMD parallelism and leverage fast algorithms with spatial locality, each feature map can be further partitioned along xand y dimensions into tiles. The compound index (tx, ty) is used to identify an input tile and an output tile, respectively. For each unique pair of an IFM w and an OFM z, there is a filter B(w, z), typically consisting of 3×3 filter parameters. The input and output tensors become block tensors of tiles as illustrated below
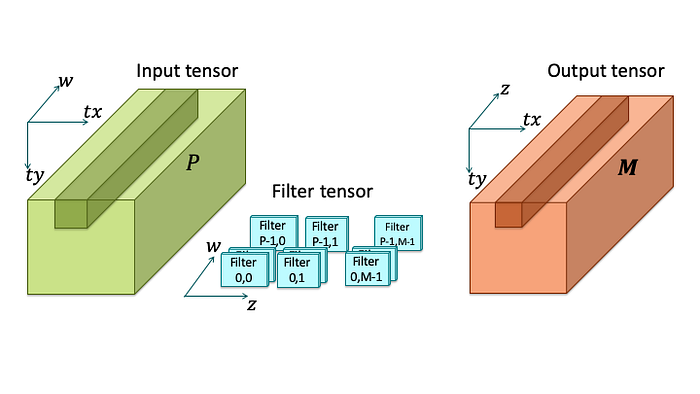
CNN in terms of block tensors of tiles
Tiled CNN can be represented more compactly and precisely in tensor-theoretic notations as follow:
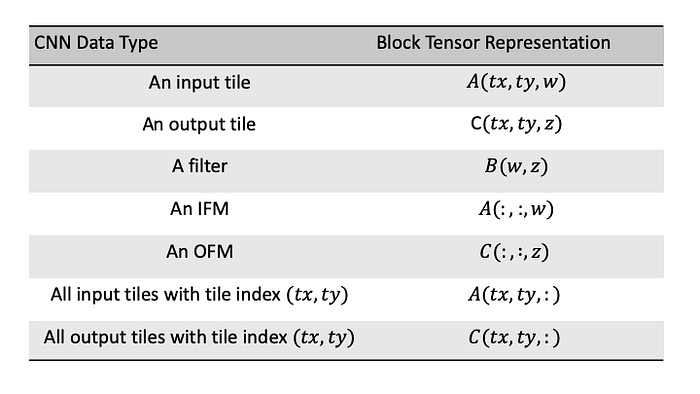
The colon notation means taking all data from that dimension. A(:, :, w)represents IFM w, since it takes all tiles from that IFM.
CNNs are Structurally Equivalent to MMs
Conventional wisdom says we must flat-unfold tensors to matrices to leverage the parallelism and data-sharing patterns in MMs. However, it is actually the other way around. CNNs are structurally equivalent to MMs in terms of their parallelism and data-sharing patterns as shown below, and that is the reason why MMs have been so pervasively used in CNNs.
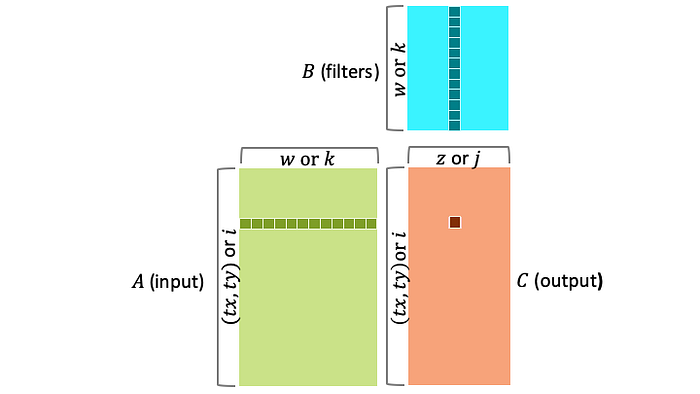
CNNs are structurally equivalent to MMs
The rows of A can be blocked since the computations of rows in C are independent. Equivalently, a feature map can be tiled since pixels can be independently computed.
The MM-equivalent parallelism and data-sharing pattern remains intact with respect to tiles.
Output tiles in the same feature map share the same filters but not the same input tiles. Output tiles along the output dimension share the same input tiles, but not the same filters. The equivalence between MMs and CNNs can be described more compactly in tensor-theoretic notations in the following table:
The Depths Need to be Tiled (Blocked), too
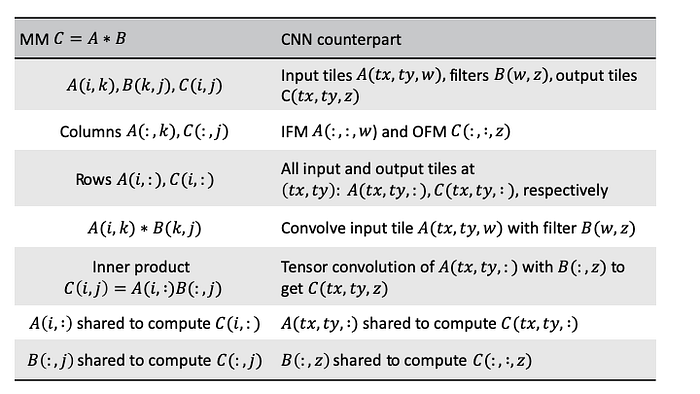
Now, imaging size of on-chip memory is constrained, and it is desirable to fully leverage the MM-equivalent data-sharing patterns in CNNs among IFMs, OFMs, and filters within a chunk of data that we bring on-chip. What should the geometry of the chunk of data look like? It must have sufficient (x, y) to reuse the filters, sufficient w to have enough input data to be shared, and sufficient z to effectively share the input data as illustrated below:
On-chip buffers must have sufficient coverages along all dimensions
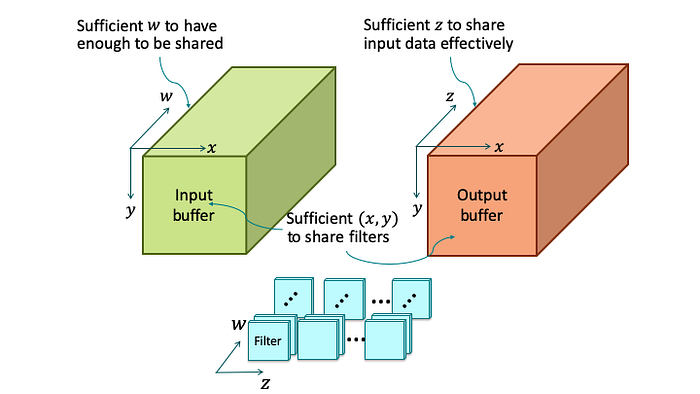
This observation leads to blocking w and z dimensions in addition to blocking x and y dimensions, which we have already done. This is to make sure input and output chunks of data cover a minimally sufficient number of IFMs and OFMs, respectively. New indexes tw and tz are introduced to identify a group of IFMs, and a group of OFMs, respectively. We define an input tensor packet A(tx, ty, tw) as a group of (tx, ty)-aligned tiles from IFM group tw. Similarly, we define C(tx, ty, tz) as a group of (tx, ty)-aligned tiles from OFM group tz. B(tw,tz) represents a group of filters, each for a pair of an IFM from group tw, and an OFM from group tz. It is called a filter tensor packet. Input, output, and filter tensors are now block tensors of tensor packets as shown below

CNN in terms of block tensors of tensor packets
MM-equivalent parallelism and data-sharing pattern remains intact with respect to tensor packets.
A tensor microkernel in software or a tensor packet engine in hardware could be designed to handle the atomic operation of convolving an input tensor packet A(tx, ty, tw) with a filter tensor packet B(tw, tz) as illustrated below:
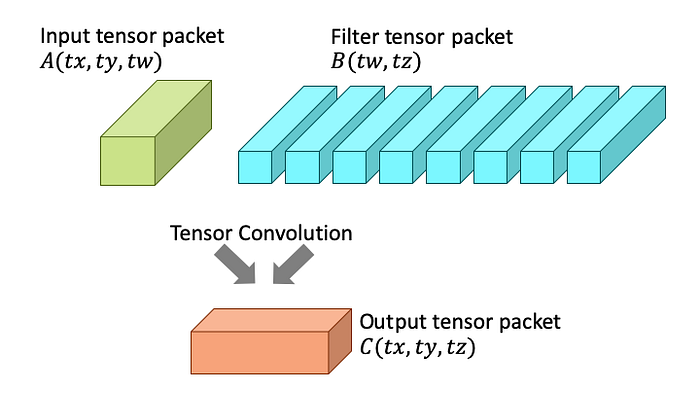
Atomic tensor packet operation
Assume input and output tiles are 6×6 and 4×4, respectively, and use 8 as the size of an IFM group and an OFM group. Without using a fast algorithm for 3×3 convolution, it takes 2,304 MAC units to finish this operation in 4 clocks. The 2,304-way parallelism is invested fairly equally among all dimensions, including x and y along a feature map, input depth w, and output depth z. Blocking with small tile size such as 4×4 enables the use of a fast algorithm such as Winograd so that 2,304-way parallelism can be achieved with only 576 MAC units.
Recursive Blocking of Tensors
A tensor packet is the fundamental unit to be consumed in its entirety by the computing units. In order to preserve the data locality and tiling structure among the tiles, we introduce an intermediate block level between the full tensor and tensor packet, tensor block, to include the tensor packets we want to bring on-chip in their entirety. It is the fundamental unit for temporal locality among tiles, and for spatial locality when there are sufficient computing units, on-chip memory, and supplying bandwidth. A tensor block is identified with (bx, by, bz) along x, y, and z dimensions.
Below is an example of recursive blocking of tensors. An entire tensor is a block tensor of 4x4x2 block tensors of 1x1x8 block tensors of 4×4 tiles, where (dx, dy) is an offset to find a pixel within a tile, and dz is an index to identify a specific feature map within a group.
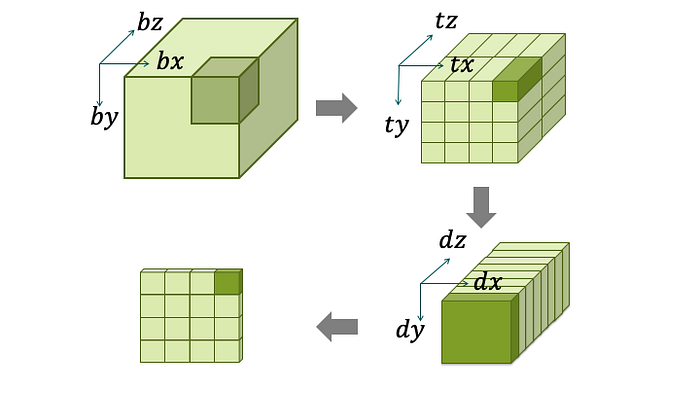
Recursive blocking of tensors to preserve locality in a feature map
Tensor blocks are stored linearly in memory. We do not need to worry about how exactly they are ordered. For a tensor block, there would be two different block-unfolding orders, one optimized to store a tensor block to DRAM, and the other optimized to present it to the computing unit. A transposition mechanism in software and/or hardware would be required to transpose from one format to another on the fly as illustrated below.
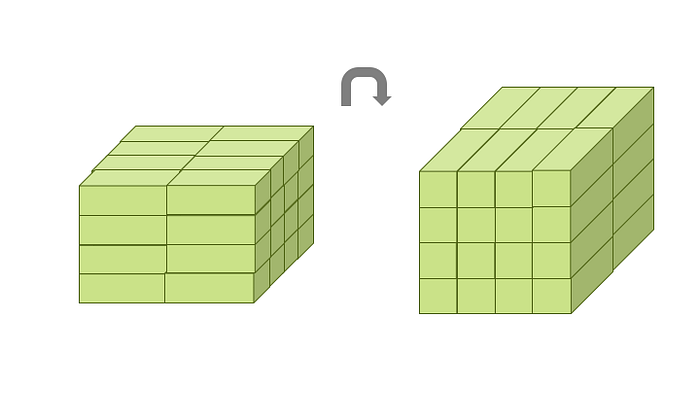
Transposition of a tensor block
The latency from performing transposition can be covered by double buffering. When a tensor block is presented to the computing units, it is unfolded into tensor packets in the (tx, ty)-major orders so the tensor packets can be processed in parallel in (x, y) domain with the computing units arranged accordingly.
All Tensors Secretly Wish to Be Themselves
Professor Van Loan also said in a talk on block unfolding of block tensors:
Block unfolding preserves structure and locality of data. …In my opinion, blocking will eventually have the same impact in tensor computations as it does in matrix computations.
Tensors are block-unfolded into tensor blocks for temporal locality in multiple dimensions so that when brought on-chip, data can be shared among multiple dimensions. A tensor block is further block-unfolded into tensor packets that have minimally sufficient coverages along all dimensions. In the presented case, it would take a big 2,304-way parallelism to process such tensor packets. MM-equivalent parallelism and data-sharing patterns are applied to tensor packets in a tensor block.
To the best of our knowledge, what has been discussed in this post might be the first effort in computing history to adopt the concept of block tensors to the bare metal. Scalable and greater parallelism across x and y dimensions for applications dealing with high-resolution video/images can be achieved. CNN might be the first killer app of block tensors with its revolutionizing power and being deeply rooted in tensors.
All tensors secretly wish to be themselves as block tensors, expecting their potential to be unleased to achieve breakthroughs in AI hardware.


