Ready to learn Machine Learning? Browse courses like Machine Learning Foundations: Supervised Learning developed by industry thought leaders and Experfy in Harvard Innovation Lab.
This is the 2nd article of series “Coding Deep Learning for Beginners”. You can view the 1st article here.
Goals
Getting into Machine Learning isn’t an easy thing. I really want to take good care of the reader. That’s why from time to time, you can expect articles focused only on theory. Because long articles discourage from learning, I will keep them at 5–8 minutes of reading time. I cannot just put everything into a single article — code snippets, math, terminology — because that would result in reducing the explanations of essential concepts. I believe that dividing the knowledge into smaller parts and expanding it across more articles will make the learning process smooth as there will be no need to take stops and detours.
Machine Learning model
Starting with the definition of “model” which will appear quite often from now on. The names like Linear Regression, Logistic Regression, Decision Trees etc. are just the names of the algorithms. Those are just theoretical concepts that describe what to do in order to achieve the specific effect. Model is a mathematical formula which is a result of Machine Learning algorithm implementation (in case of these articles — in code). It has measurable parameters that can be used for prediction. Models can be trained by modifying their parameters in order to achieve better results. It is possible to say that models are representations of what a Machine Learning system has learned from the training data.
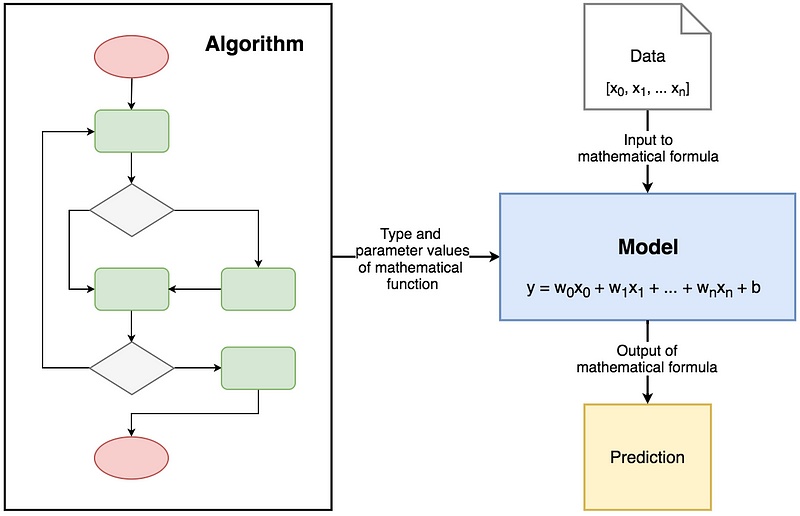
Diagram visualising difference between Machine Learning Algorithm and Machine Learning Model.
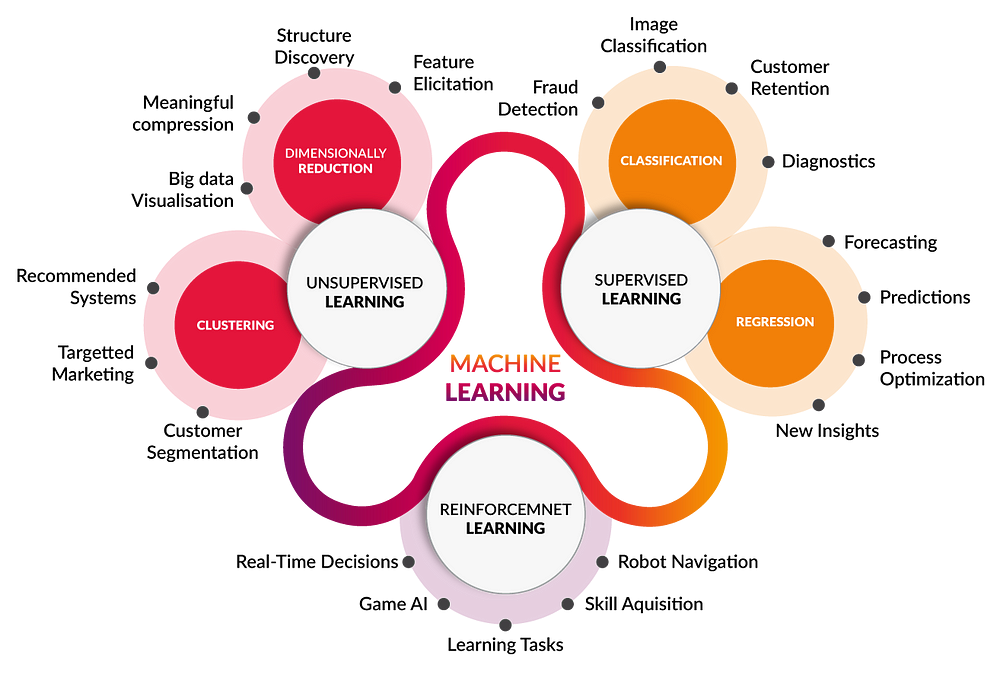
Branches of Machine Learning
There are three most regularly listed categories of Machine Learning:
- Supervised Learning
- Unsupervised Learning
- Reinforcement Learning
Supervised Learning
The group of algorithms that require dataset which consists of example input-output pairs. Each pair consists of data sample used to make prediction and expected outcome called label. Word “supervised” comes from a fact that labels need to be assigned to data by the human supervisor.
In training process, samples are being iteratively fed to the model. For every sample, the model uses the current state of parameters and returns a prediction. Prediction is compared to label, and the difference is called an error. The error is a feedback for the model of what went wrong and how to update itself in order to decrease the error in future predictions. This means that model will change the values of its parameters according to the algorithm based on which it was created.
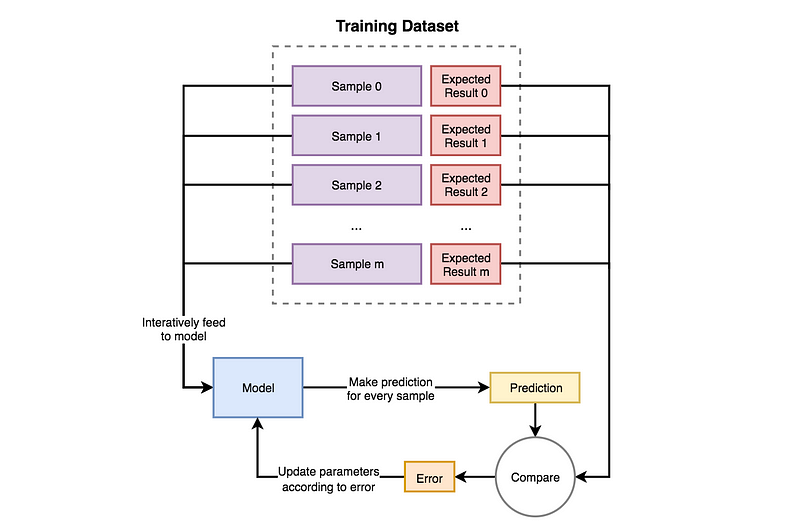
Diagram demonstrating how Supervised Learning works.
Supervised Learning models are trying to find parameter values that will allow them to perform well on historical data. Then they are used for making predictions on unknown data, that was not a part of training dataset.
There are two main problems that can be solved with Supervised Learning:
- Classification — process of assigning category to input data sample. Example usages: predicting whether a person is ill or not, detecting fraudulent transactions, face classifier.
- Regression – process of predicting a continuous, numerical value for input data sample. Example usages: assessing the house price, forecasting grocery store food demand, temperature forecasting.
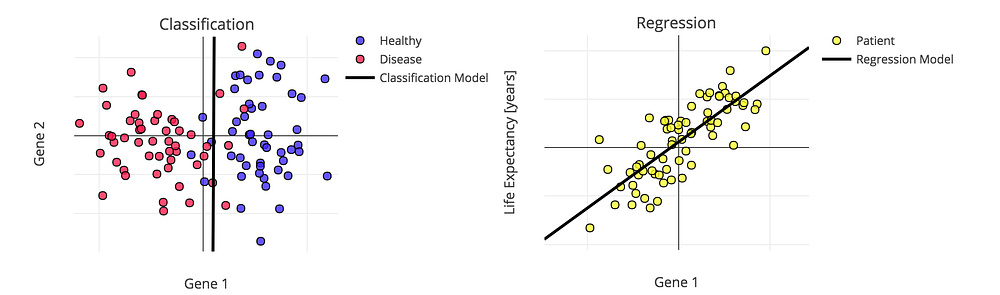 .
.Example of Classification and Regression models
Unsupervised Learning
Group of algorithms that try to draw inferences from non-labeled data(without reference to known or labeled outcomes). In Unsupervised Learning, there are no correct answers. Models based on this type of algorithms can be used for discovering unknown data patterns and data structure itself.
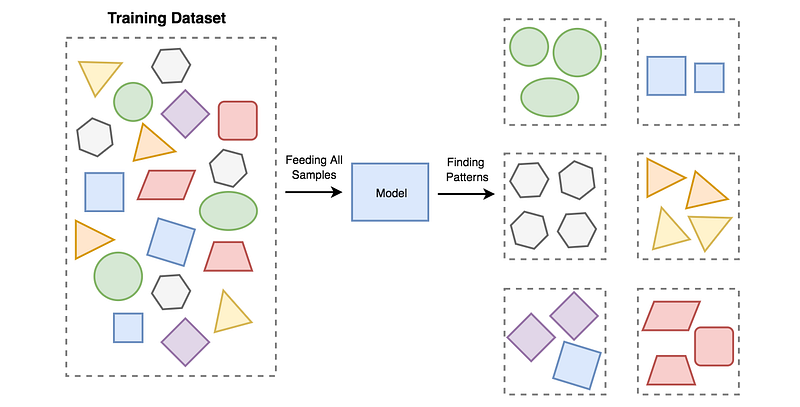
Example of Unsupervised Learning concept. All data is fed to the model and it produces an output on it’s own based on similarity between samples and algorithm used to create the model.
The most common applications of Unsupervised Learning are:
- Pattern recognition and data clustering – Process of dividing and grouping similar data samples together. Groups are usually called clusters. Example usages: segmentation of supermarkets, user base segmentation, signal denoising.
- Reducing data dimensionality – Data dimension is the number of features needed to describe data sample. Dimensionality reduction is aprocess of compressing features into so-called principal values which conveys similar information concisely. By selecting only a few components, the amount of features is reduced and a small part of the data is lost in the process. Example usages: speeding up other Machine Learning algorithms by reducing numbers of calculations, finding a group of most reliable features in data.
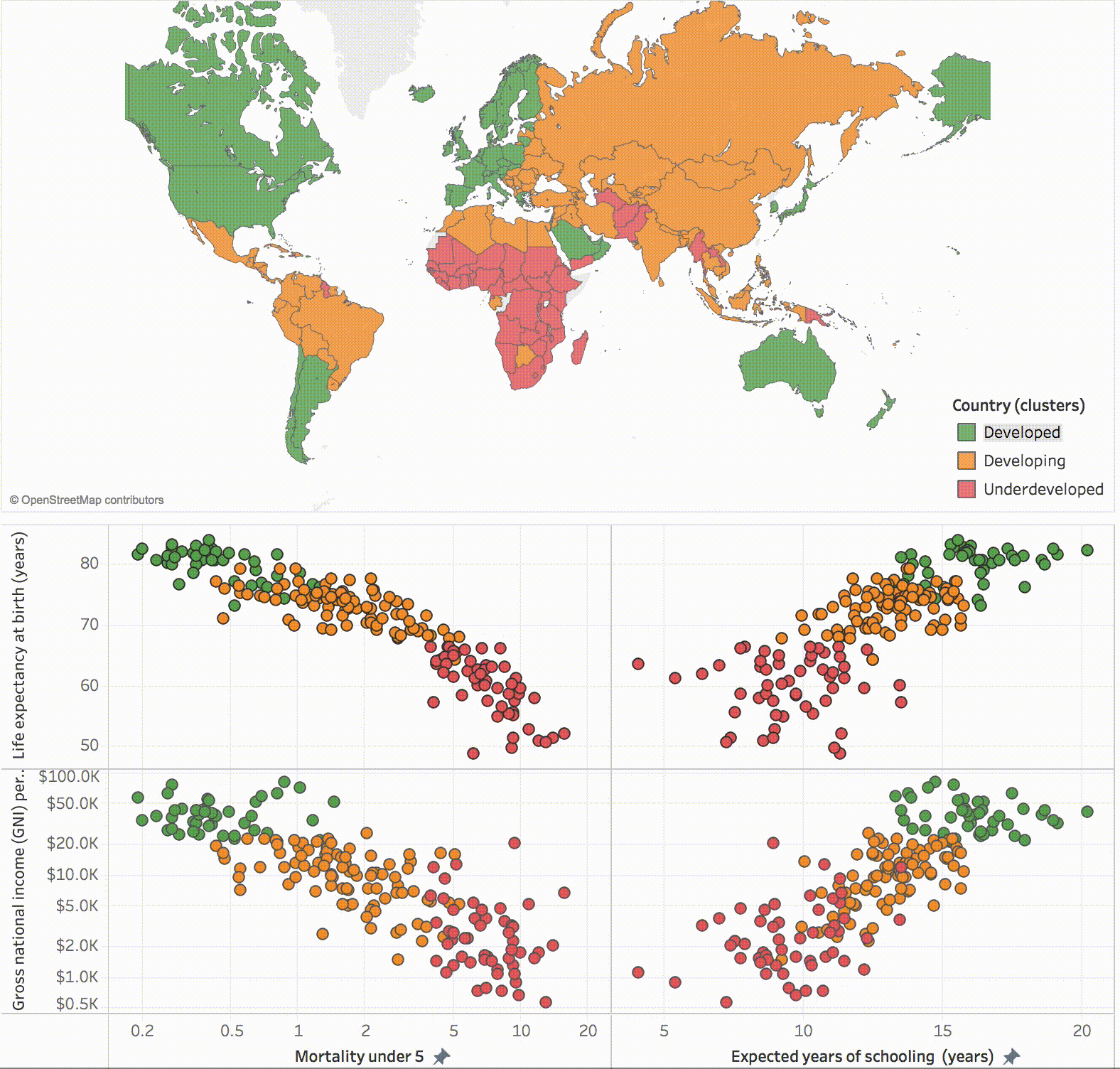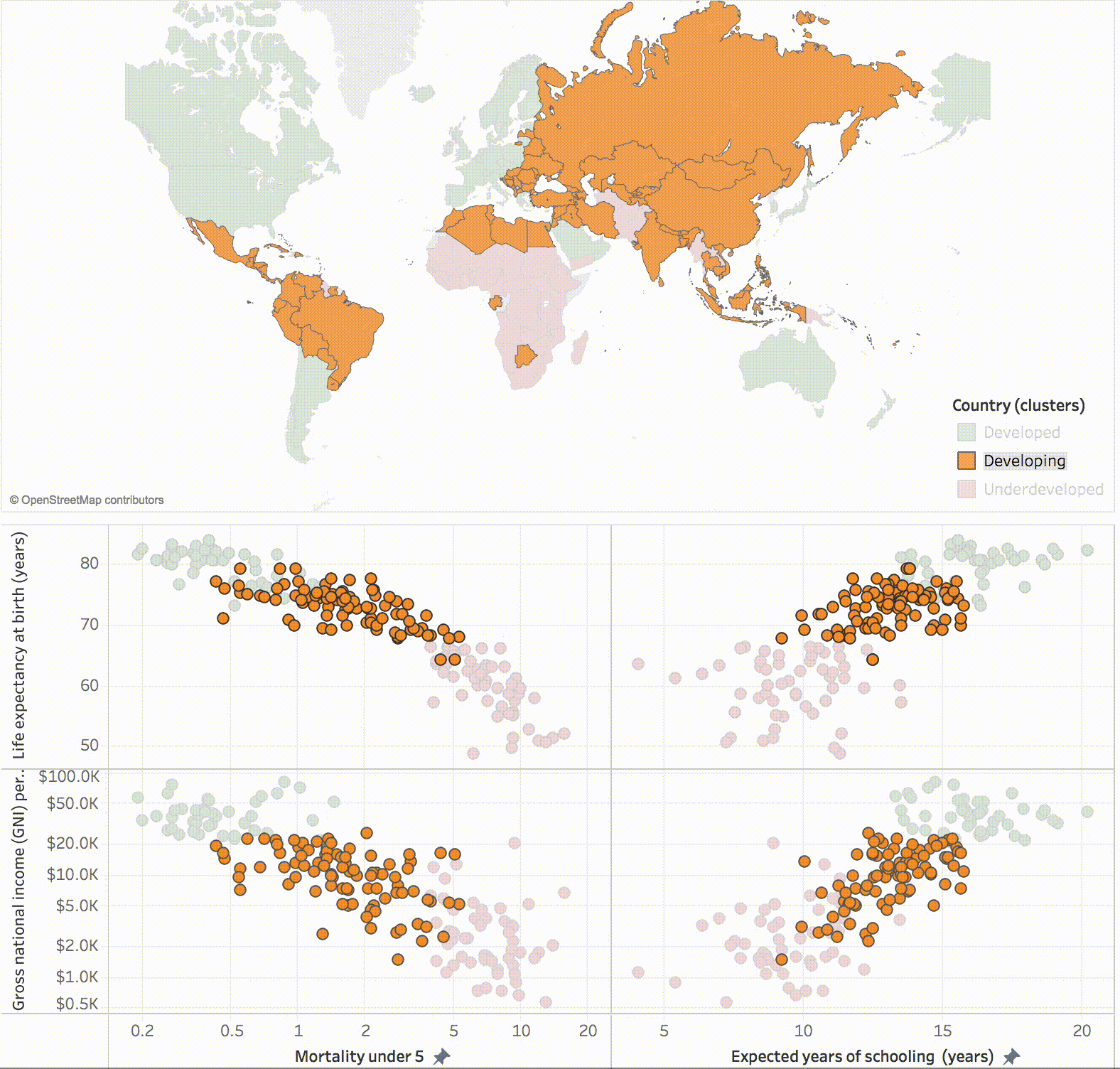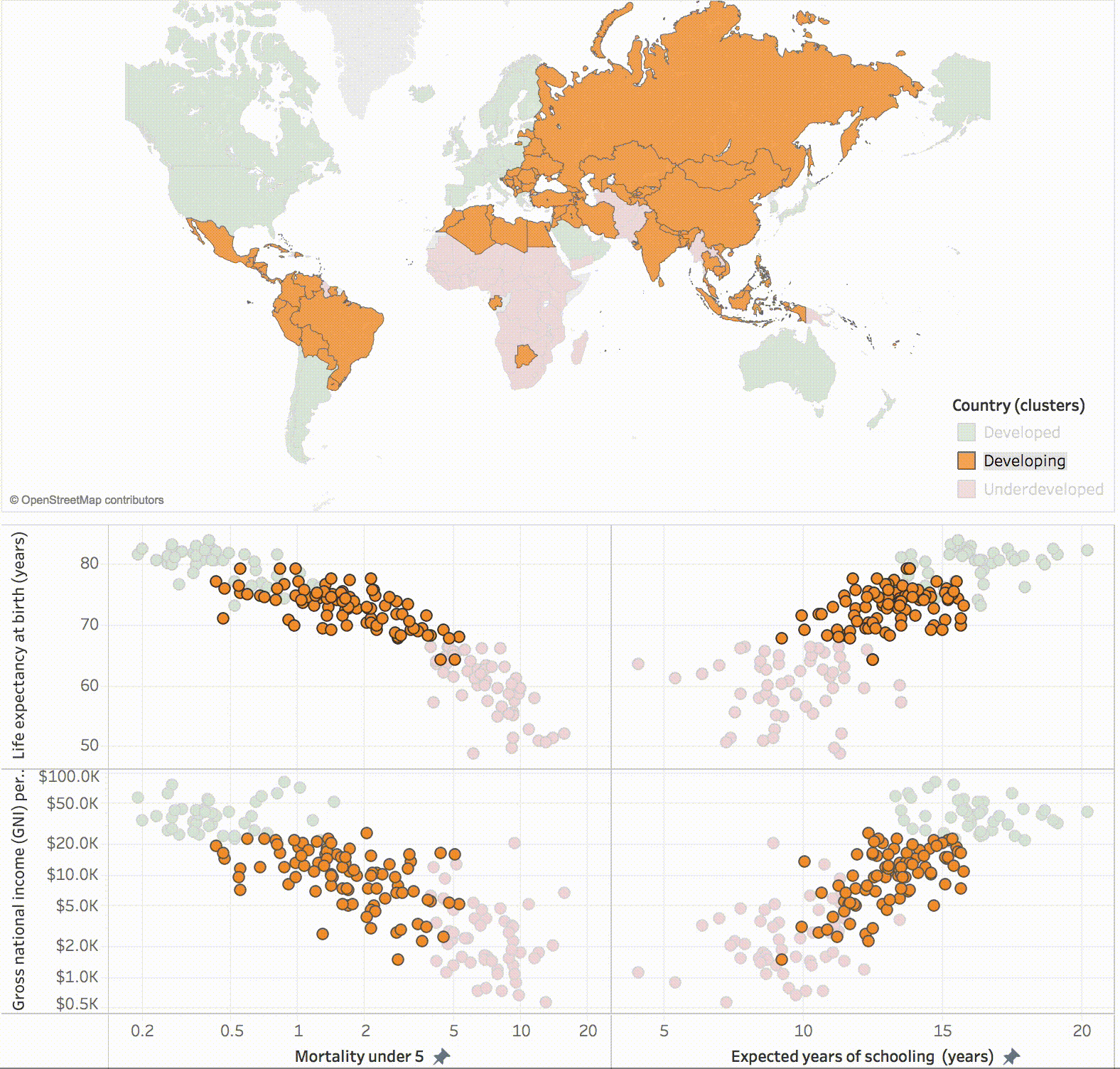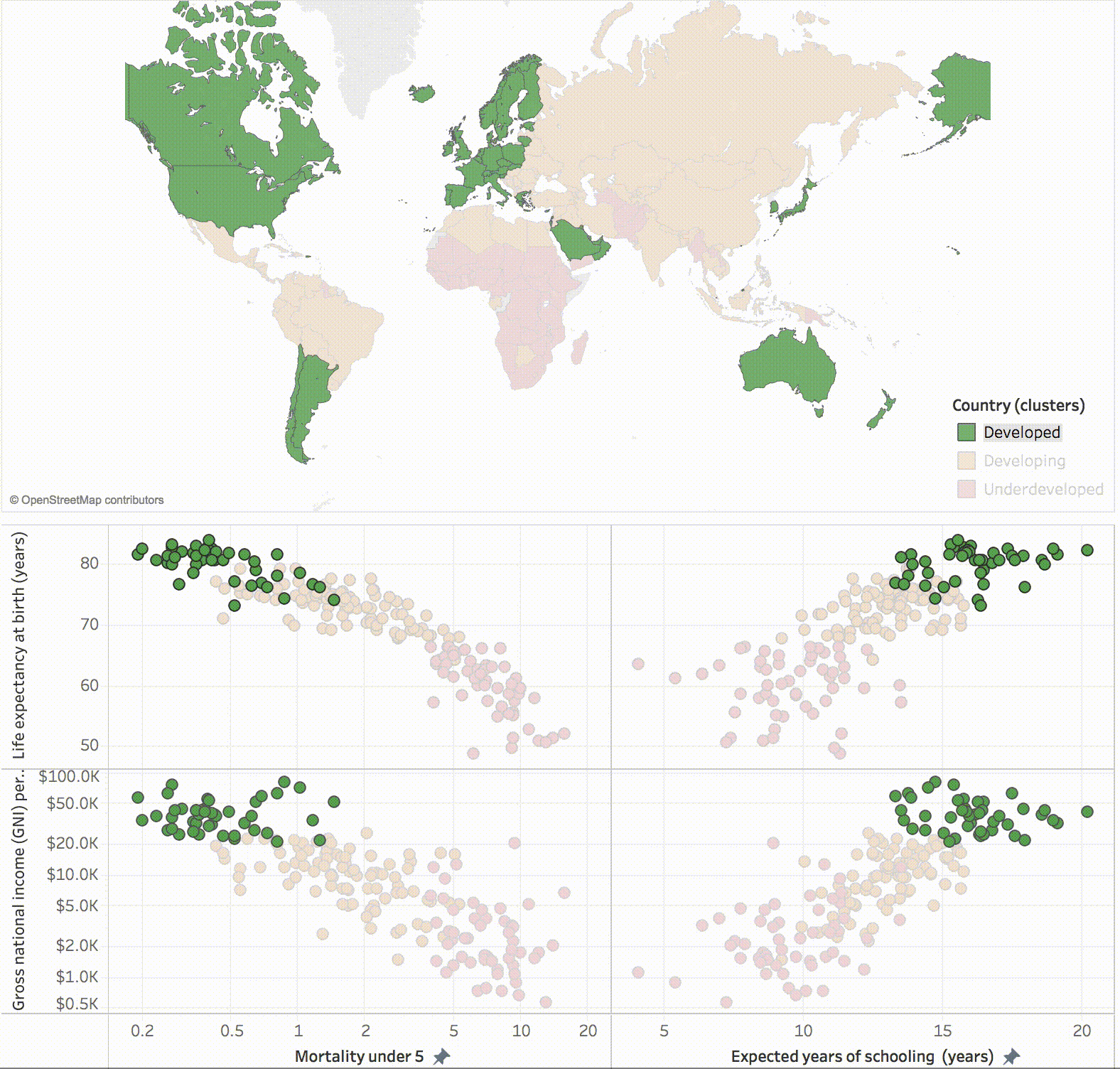
Dividing data from various countries around the world into three clusters representing Developed, Developing and Underdeveloped nations (source: Tableau blog).
Reinforcement Learning
Branch of Machine Learning algorithms which produces so-called agents. The agent role is slightly different than classic model. It’s to receive information from the environment and react to it by performing an action. The information is fed to an agent in form of numerical data, called state,which is stored and then used for choosing right action. As a result, an agent receives a reward that can be either positive or negative. The reward is a feedback that can be used by an agent to update its parameters.
Training of an agent is a process of trial and error. It needs to find itself in various situations and get punished every time it takes the wrong action in order to learn. The goal of optimisation can be set in many ways depending on Reinforcement Learning approach e.g. based on Value Function, Gradient Policy or Environment Model.
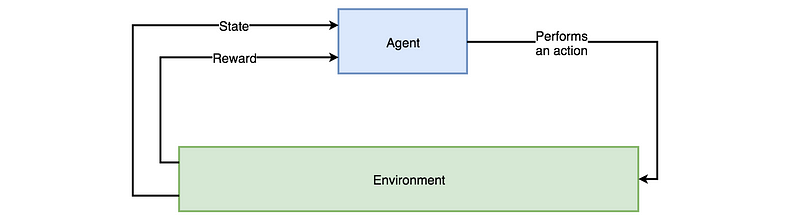
Interaction between Agent and Environment.
There is a broad group of Reinforcement Learning applications. Majority of them are the inventions, that are regularly mentioned as most innovative accomplishments of AI.

Example of solutions where Reinforcement Learning is used. From self-driving cars through various games such as Go, Chess, Poker or computer ones — Dota or Starcraft, to manufacturing.
Simulating the movement of 3D models is a complicated task. Such models need to interact with different models in a given environment. Reinforcement Learning is becoming more actively used as a tool for solving this problem, as the results it produces seem very trustworthy for human eye and algorithms are capable of automatically adjusting to rules describing the environment.
Main video accompanying the SIGGRAPH 2018 paper: “DeepMimic: Example-Guided Deep Reinforcement Learning of Physics-Based Character Skill”. https://youtu.be/vppFvq2quQ0
Summary
And that’s it. In the next article, I will explain basics and implementation of Linear Regression algorithm which is one of the basic Supervised Learning algorithms.



