Last week, I was discussing the key features of an Enterprise Knowledge Graph (EKG) with some colleagues, and I realized that although we were using the same words, we were talking about different things. We had a problem with the semantics of the word “Enterprise”. This is a bit ironic since many of these people I was talking to had a strong background in semantics.
Many people co-mingle the terms from open linked data world and the semantic web stack’s role with the concepts related to sustainability and scalability of enterprise knowledge graphs. My assertion is these are independent and orthogonal concepts. They both share the goal of highly connected and easy-to-query data. But in my definition of EKG, there is no requirement for using any components of the semantic web stack to qualify as an enterprise knowledge graph.
How you connect your data within your graph is an implementation detail, not a defining characteristic of an EKG. Every project has different requirements to link data and uses a different set of tools from my experience. For example, entire companies help you design and build master data management systems that perform entity resolution of customer data.
To me, what defines a true EKG is an answer to the question: Does your system support the demanding requirements of sustainable, scale-out, highly connected, and queryable datasets in large,diverse organizations?
Let’s list the attributes of graph projects that we have found to be the most relevant to predicting if small departmental level graph projects will ever evolve from a pilot phase to a true enterprise-scale solution.
1. Scale-out data size — adding more RAM, SSD, and spinning disk should not interrupt services. Operations staff should be able to add new nodes to a cluster and have the data automatically migrate to the new nodes without service interruption. If you have to shut down critical services to do this, you don’t really have an enterprise-class system.
2. Scale-out compute — adding additional CPUs should be possible without service interruption. That means even adding new hardware such as an FPGA to perform real-time similarity calculations in parallel to your EKG without service interruption.
3. Scale-out security — adding more projects with more roles and more users should not impact system performance. The preferred method of implementing this is to use role-based access control (RBAC) at the vertex level. Because RBAC removes the requirement of associating a user’s ID with each vertex, RBAC is a much more scaleable authorization process.
4. Scale-out manageability — monitoring the continual performance of 100s of applications executing thousands of graph queries is a complex process. EKGs must have ways to integrate detailed query performance logging and quickly alert operations staff when service levels become slower than expected values.
5. Scale-out data quality —EKG software must make it easy to perform data validation as it enters the EKG and as it evolves within the EKG as new relationships are inferred. Creating rich and maintainable data quality rules in declarative languages like XML Schema with GUI editors and writing rules for link quality such as in SHACL will need to be an integral component of future EKGs.
6. Scale-out algorithms — EKGs need to run an extensive library of standard graph algorithms and a new generation of machine-learning algorithms that create graph embedding. Complex CPU-intensive queries must be able to run on EKGs without impacting application service levels.
7. Scale-out query — EKGs need query software that allows developers to express distributed queries in high-level query languages. We learned from the Map-Reduce days that forcing developers to write 10-pages Java programs that take days to run on unindexed raw files will not cut it in the future. Features such as Accumulators in GSQL make it easy for graph query developers to express distributed queries in just a few lines of code.
Staying Small is Still OK
Not every graph project needs to evolve into an enterprise sale project. Small departmental projects that focus on a few tasks can still be cost-effective and useful to the people in that department. The challenge I see is that many graph pilot projects hope that their solution will scale-up but don’t have a concrete plan to scale up.
My advice is to begin a project with the end in mind. Ask around if a vendor has references that have scaled to meet the demanding needs of thousands of concurrent users using hundreds of applications with zero downtime.
On-the-wire vs. In-the-Can Thinking
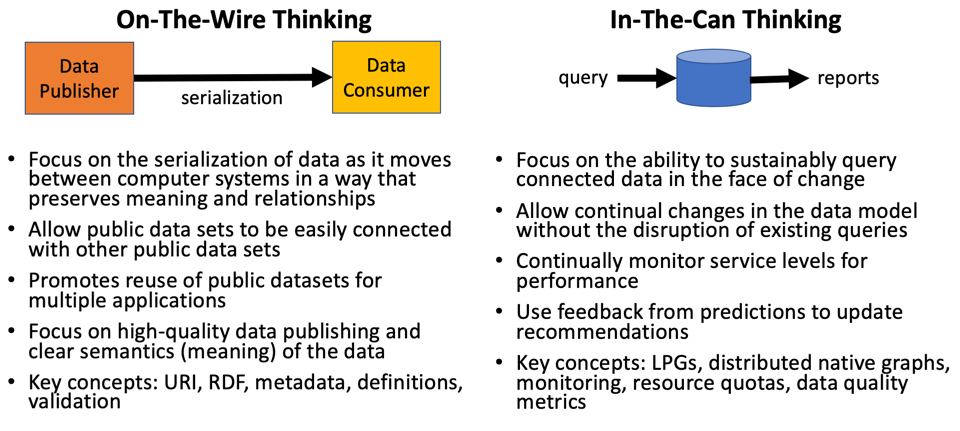
One of the key issues that many solution architects struggle with is the requirements for representing connected data on-the-wire vs. representing connected data in a database (in-the-can). As articulated by Tim-Bernes Lee in their landmark Scientific American issue in May of 2001, the Semantic Web’s original vision was a vision of publishing data, not of scalable enterprise database query technology.
Although it was a laudable goal to use the same stack for both purposes, it didn’t seem to work out. The problems with schema evolution and RDF reification (The Jenga Tower Problem) prevented large-scale RDF database systems from being cost-effective for any teams of more than a dozen developers. RDF* (RDF “star”) is a laudable effort, but it might be too little, too late. LPG database products now have come to dominate the enterprise graph market and have shown that they can meet the enterprise’s demanding requirements.
Conclusion
Words are important. My advice is to ask your colleagues and your vendor precise questions about what they mean when they use the word “Enterprise” when describing their graph products and services. If they insist that you must use the semantic web stack to be considered enterprise-worthy, then seek clarification on what their requirements are for success.
If colleagues talk about on-the-wire issues related to precise data publishing, then suggest they use the word “semantic knowledge graph.” If they try to address the issues of a specific department, then try using the word “project knowledge graph” or “department knowledge graph”.
If colleagues clearly articulate the need for sustainable scale-out graph databases that support large organizations’ diverse needs, you might have a start on gaining consensus on what the word “Enterprise” really means in the phrase “Enterprise Knowledge Graph”.



