This blog will speculate on how enterprise knowledge graphs (EKGs) will evolve to contain specialized functions and specialized subgraphs. We will use metaphors from the evolution of centralized nervous systems (CNS) in primitive life forms to make some key points about architectural trade-off analysis.
If EKGs are really going to become the centralized “Brain” of organizations, they will need to evolve from where they are today to take on new roles. We also need to understand the challenges of depending on central control of organizations.
EKG and CNS Metaphor: Sponges, Octopuses, and the Human Brain
We will be using the metaphor of the CNS in organisms to discuss how EKGs are evolving. This requires us to look at the spectrum of different ways that organisms have evolved different types of nervous systems and how important these are at adapting to new environments.
Let’s begin with the sponge. It has no real central nervous system. There is no cell-type specialization of neurons in sponges that exchange information using electrochemical signals. Sponges have homogeneous cells that communicate using chemical signals, but they are slow and evenly distributed throughout the sponge’s body.
This decentralized design has some advantages. You can cut a sponge in half, and both parts can survive. Simple designs are easier to maintain and have fewer single points of failure.
When we think of the “sponge information architecture,” we can imagine many small departmental subgraphs, databases, and spreadsheets that are disconnected. They are all small islands of “cells” of information in an enterprise, and they don’t communicate in real-time. However, you can often do a reorganization of your company by and sell business units, and it will continue to function without impacting the individual team performance.
Next, consider the octopuses. Although octopuses have neurons and a centralized brain, over half the neurons are also distributed in each of the octopus’ limbs. Octopuses do general planning for movement in their central brain, but they allow the details of complex limb motion to be done within the neurons of each limb itself.
An “octopus information architecture” has some centralized role for an EKG, but it does not perform the detailed predictive business planning within each business unit. Technically we call this a semi-centralized EKG architecture. The EKG will still have specialized subgraphs, but they need to be designed to send abstract concepts to departmental graphs where the execution details are done.
Finally, consider the human brain. Our brains have highly centralized nervous systems, and both large-scale body movement planning and fine motion control are all performed within the skull. Our eyes process images and send the data to our visual cortex, and separate brain areas coordinate predictive motion with our limbs. However, we don’t delegate motion planning into neurons within our limbs. We do have many highly specialized regions of our brain for doing different functions.
Human brains display both low-level homogeneous cell types (Neurons) but high-level diversity of the connection patterns within the brain’s thousands of subregions.
I believe that different organizations will also evolve different styles of EKGs based on their environments. And just like the ways that different types of CNS have evolved, in the same way, different types of EKGs will also evolve to meet the needs of different types of organizations. EKG will also follow similar evolutionary paths as CNS evolution. They will start simple and slowly evolve more complex and specialized structures. I also believe that large organizations with centralized EKGs will come to dominate companies just like humans have come to dominate life on planet Earth.
Complexity Has a Cost
Complexity always comes with some cost. Many examples of plants and animals in the living world today have kept their organization simple. Because of this simplicity, they thrived. Datastores like key-value stores are good examples of keeping the data stores and their interfaces simple to become easier to scale-out. Unfortunately, this simplicity also prevents us from efficiently doing complex queries on key-value stores.
Evolutionary Progress in Non-Linear
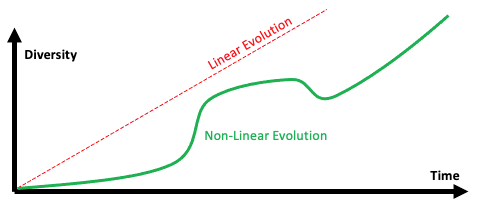
Most people know about the concept of the Cambrian Explosion. The Cambrian Explosion occurred around 541 million years ago when ocean lifeforms were primitive — much like sponges. Before the Cambrian Explosion life forms were relatively simple and didn’t change quickly over time. After the Cambrian Explosion, we had both rapid evolution and huge growth in the diversity of animals.
The Cambrian Explosion is an example of a non-linear evolutionary system. If we plotted the number of different types of animals over time, it would not fit a straight line. So do most systems that evolve behave like Complex Systems. EKGs will also follow many of the complex systems’ rules and show nonlinear growth patterns triggered by key events such as the GQL standard and the arrival of graph hardware.
Early Life Forms and the Evolution of the Central Nervous System
But how did the Central Nervous System evolve? Why is the growth non-linear?
Unlike plants that wait for food to come to them, some early life forms were more mobile. They moved to where the food was, and later, they also needed to learn to catch prey and move away from predators. So to catch its prey or to evade its predators, they needed muscles.
Unlike sponges that were stationary, jellyfish move around. Jellyfish animals have distributed Nerve Nets throughout their body. They don’t show any signs of centralized nervous systems yet. The key evolutionary step in the evolution of centralized nervous systems was the Cephalization of the body plan. This process organized body parts around a bilateral body plan.
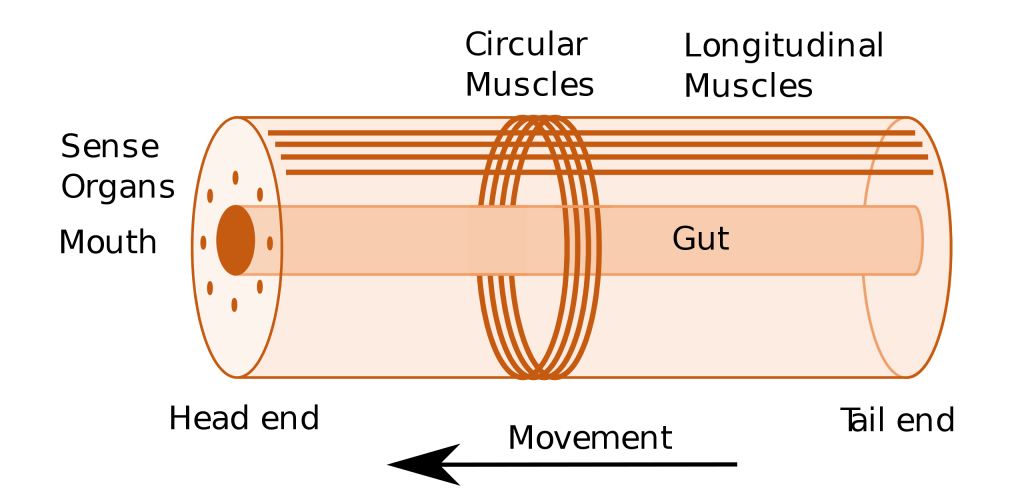
Once the basic body plan around a gut evolved, specialized tissues that expanded and contracted became muscles. Sense organs appeared around the mouth of the gut. And now the question arose — how do we coordinate senses with muscles? Should this coordination be distributed or centralized?
Jellyfish took the decentralized route. They kept their body plans simple and put sense organs at the tips or edges of their body plans, and they never evolved a gut and bilateral symmetry.
But Bilateria took a different route. They took a specific body architecture and found that a centralized nervous system could coordinate senses and muscles.
Today it seems evident that the distributed native labeled property graph is the equivalent of the bilateral body plan. It has all the key architectural features we need to build a scalable and sustainable EKG. There will still be niche environments for other graph database architectures. But we now have an architecture that will trigger a “Cambrian Explosion” in graph databases that will power future EKGs.
The Evolution of Best Practices
Diverse Environments Accelerate Evolution
Imagine that the entire planet earth was a uniform shallow ocean. There was no variation in the depth of the ocean and no landmasses. If this were the case, we would not see the same diversity of life forms today. Because the earth provides non-uniform ecological landscapes, we get much more diversity of life forms.
The same will be true of the evolution of EKGs. Organizations are not homogeneous. They serve different industries and different types of customers with a wide variety of products and services. Because of this diversity, we should expect to see EKGs diversify in some of their architectures.
Software Homogeneity Allows for Hardware Optimization
Now here is an oppositional thought to the diversity observation. If there are thousands of different databases, no vendor would sink a billion dollars into optimizing silicon hardware for one architecture. But the evolution of distributed native labeled property graphs (DNLPGs) has put a sharp focus on one single architecture — the use of pointer hoping to traverse relationships. Since almost all modern enterprise knowledge graphs use NLPGs we are starting to see hardware optimized for these databases.
That means that any other database that does not leverage DNLPGs will see a 1,000x disadvantage in performance. That means that evolutionary forces will force these non-DNLPG systems to focus on other areas than performance. If they don’t the laws of survival of the fittest will eliminate them from the database marketplace.
Yes, these rules are somewhat contradictory. But we need to keep them both in our minds as we try to visualize how EKGs will evolve.
Specialized Brain Regions
One of the most incredible things in the universe is how brains have taken a single structure, the neuron, and have used that same structure to build an incredible variety of more complex structures within brains. Human brains have thousands of different regions that have developed specialization over more than 500 million years of evolution. We can expect EKGs to develop highly specialized regions but still use a common structure: vertices and edges with attributes. Here are just a few specialized subgraphs that might develop:
- Geolocation — information about places such as addresses, cities, states, and regions.
- Access Control (security) — associates a user with their roles and permissions.
- Customer Knowledge — all customer touchpoints including web visits, e-mails, purchases, returns, and product reviews.
- Product Knowledge — detailed knowledge about products, specifications, warranties, product taxonomies, similar products, and competitor products.
- General Language Knowledge — structures that describe words, word meanings, synonyms, acronyms, abbreviations, related words, and definitions.
- Business Terminology — Terms that are specific to your organization and industry. May contain specialized definitions for common words within your field.
- Data Conversion Knowledge — How raw data is converted into connected knowledge. Include rules for schema matching, schema mapping, data format conversion, and data quality checks.
- Data Linage Knowledge-How did data arrive in the EKG? Where did it come from and how was it transformed. How recent and how relevant is the data to a specific task?
- Business Rule Knowledge — How are deterministic business rules stored and executed in the EKG? How do people view and update the rules? What are the downstream consequences of a high-level rule is changed?
- Reporting Knowledge-How are reports created. Where did the data come from? How often are the reports run and by what agents? What is the cost of running the reports? Who created and maintains the reports? What are the most similar reports to any given report?
- Causality Knowledge — What is the cause of various business events? Can we explain the root causes of problems with our customer experience? Can see simulate choices to predict future costs?
Brains and Skulls: Protecting Your EKG
As centralized nervous systems became more complex they started to become a single point of failure for animals. A blow to an unprotected brain could quickly render an animal unconscious and vulnerable to predators.
If an octopus loses part of its decentralized brain in one of its limbs it can still survive and even grown a new limb. Similarly, a departmental data mart can crash and not impact your customer experience.
So how to protect a central resource where our customer experience depends on it being available 7×24? How do we build a “skull” around our EKG to make sure it has high availability? Using a distributed graph database that has a high level of replication is one solution. But protecting your EKG from rough queries is also critical.
Several years ago, a friend of mine was involved in a project to make it easier to query low-level data in a Data Lake using a new open-source query program. The problem was that the software did not have any ability to limit resources such as CPU time, memory, or IO for any query. As a result, a small error in a query would make the entire Data Lake unusable until the query finished or every node in the cluster was rebooted. Needless to say, the project was halted even after considerable investment. The core attributes of fine-grain enterprise-class control of resources had not yet evolved.
In summary, EKGs need not just fine-grain access controls, but they also need internal controls to protect real-time services from disruption.
Conclusion: Let the EKG Explosion Begin
We are now at the stage that several powerful forces are at work to create an explosion in different types of EKGs:
- A standardized data model — the Labeled Property Graph (LPG)
- A scale-out architecture — Distributed Native LPGs
- A standard query language -Graph Query Language (GQL)
- Hardware optimized for the pointer hopping and random access patterns of distributed native LPGs
- Software that supports enterprise concerns (HA, Security, etc.)
- Integration of graph-machine learning software to automatically predict future events and make recommendations
As a result, I expect that in a few years, we will see EKGs that are as diverse as the animal types at the end of the Cambrian Explosion. We will also see a decline in older more primitive relational architectures as EKGs evolve more sophisticated features.
Note that relational databases and spreadsheets will not go away. We still have sponges in the world because their simple designs have benefits. But sponges don’t dominate our planet. Organizations that embrace EKGs’ diversity and complexity are destined to control far more resources than those that stick with simple designs.



