5 critical elements of ML model selection & deployment
87% of Data Science projects never make it into production. That statistic is shocking. Yet if you’re like most Data Scientists, it probably doesn’t surprise you. Nontechnical stakeholders struggle to define business requirements. Crossfunctional teams face an uphill battle to set up robust pipelines for replicable data delivery. Deployment is hard. Machine learning models can take on a life of their own.
Here’s a list of five practical steps for future-proofing your model against these challenges of model selection and deployment. If you’ve been ignoring these critical elements in the past, you may find your deployment rate skyrockets. Your data products may depend on correctly deploying the tips from this article.
1.0 Don’t Underestimate Interpretability
An interpretable model is one that is inherently explainable. For example, Decision Tree based methods — Random Forest, Adaboost, Gradient Tree Boosting — offer up a clear view of their underlying decision logic.

Interpretability may be mandatory in the heavily regulated fields of criminal justice and finance. It also tends to be an underrated element of a strong data science project.
Along with inherent interpretability, a Decision Tree model has the following helpful properties:
- Easily depicted in a visual format
- Able to detect any non-linear bivariate relationship
- Good predictive power across a wide variety of use cases
- Provides ranked feature importance
- Low requirements for feature preprocessing
- Works with categorical features using
sklearn.OneHotEncoder - Handles outliers well and does not easily overfit
- Can be used for either classification or regression
For these reasons, Decision Trees are a solid initial model to explore many typical business problems.
At the point of making a decision, are stakeholders more likely to trust an uninterpretable black box Neural Network or a Random Forest? Consider that a very detail-oriented (or very bored) business person could clearly trace the logic in every single underlying Decision Tree if they so chose. If the job of a Chief Data Officer is to keep the CEO out of jail, then this level of interpretability is clearly a win.

Beyond the Decision Tree, the family of interpretable models includes Naive Bayes Classifier, Linear and Logistic Regression, and K-Nearest Neighbors (for clustering and regression). These intrinsically interpretable models have the added benefit that they save significant time and resources in training and serving at a negligible cost to predictive performance relative to black box Neural Networks.
1.1 How to select the right model
Whether aiming for interpretability or not, use this resource (Decision Trees everywhere!) to guide your model selection:
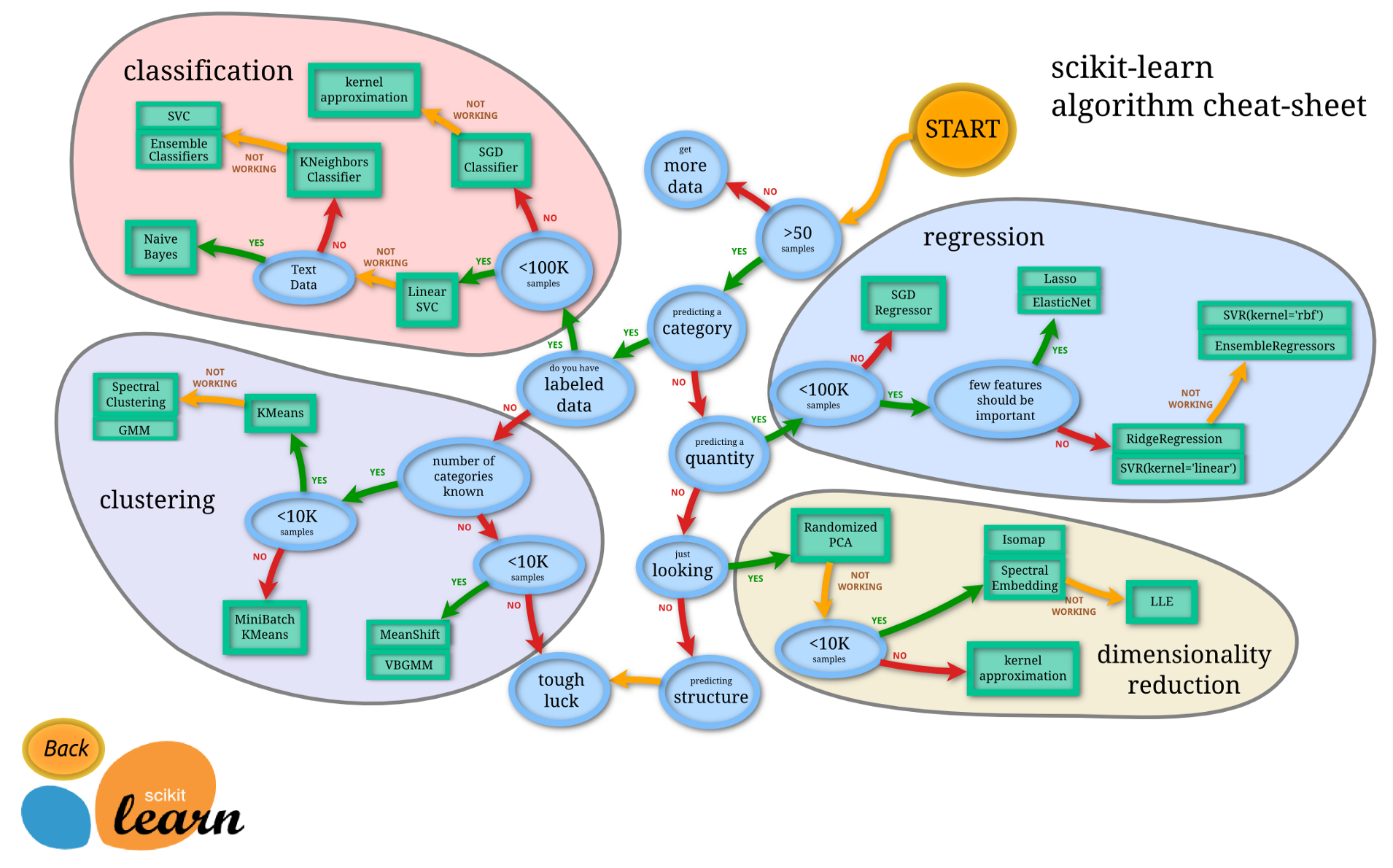
1.2 Read more about Model Selection
Comprehensive Guide to Model SelectionA systematic approach to picking the right algorithm.
2.0 Prune for Productionization
Of course, sometimes going with a Neural Network may be your best option. Perhaps you’re doing image recognition or natural language processing (NLP). Perhaps you’re working with a very complicated dataset. If you’re using a Neural Net, you should consider how to pare back the model before putting it into production.

In the words of Mark Kurtz, Machine Learning Lead at Neural Magic:
Most weights in a neural network are actually useless.
After training, 60–90% of weights can be removed with no impact on performance. The result is faster inference time, reduced model size, and lower cost to serve users. In fact, the Neural Magic team argues that this sparsification could enable a renaissance in CPU-based architectures and “no hardware” AI.ICML Paper: Inducing and Exploiting Activation Sparsity for Fast Neural Network InferenceIn July 2020, at the International Conference on Machine Learning, we presented a paper on methods for maximizing the…neuralmagic.com
Pruning involves removing the unused pathways in the Neural Network, keeping the necessary ones. Gradual magnitude pruning (GMP) has emerged as a favorite technique. In general, unstructured pruning — i.e. the removal of specific weights rather than entire neurons — allows for greater control over the sparsification process, resulting in better performance.
2.1 How to prune your model before productionizing
- Retrain network at a slightly higher learning rate than final one used in training
- At the start of epoch 1, set all the sparsity for all layers to be pruned to 5%
- Iteratively remove the weights closest to zero once per epoch until designated sparsity is reached
- Hold sparsity constant for the remainder of retraining while reducing learning rate
2.2 Read more about the Lottery Ticket Hypothesis
3.0 Prevent Data and Model Drift
After deployment, the forces of drift will inevitably buffet your model and cause its performance to degrade over time. Data drift occurs when the model’s underlying input changes with a data feature or features longer measuring what was originally measured. Model drift occurs when environmental conditions change, and the model is no longer reliably representing the real world.

3.0a Data Drift
Data drift is typically the result of changes in the data collection process. For example, a sensor at a manufacturing plant could break, recording several hours of zero temperatures before the problem can be corrected. Then the new may sensor may record temperatures in celsius, rather than the previous measurement in Fahrenheit. Without context on these changes, the zero values and switch to a new standard of measurement will have an adverse effect on the downstream model.
The same can be said for changes to qualitative information. Survey data collection methodology — e.g. switching from mailing questionnaires to polling landlines — will have an impact on the demographics of respondents. Even slight changes to the way a question is worded will adversely impact a model’s capability to draw longitudinal inferences from the dataset.
Data drift could also result from changes to the definitions of the fields in the dataset. For example, the data owner at the manufacturing plant could decide that the term “scrap” should refer not just to unusable material, but also material that will eventually reprocessed into recycled products. This change in terminology will also impact model performance.
3.0b Model Drift
Changes in the real world environment may degrade a model’s predictive power.
Given the cataclysm of a year that 2020 has been, models of consumer behavior generally need to be kicked to the curb. Carl gold is the Chief Data Scientist at Zuora, a services provider for subscription businesses that helps them move beyond analytics with advanced data products. In a recent interview, he shared his perspective on the impact of the pandemic:
I’m telling everyone to update their model. Now, if you do a new churn model, you should really only use data since COVID if possible.
That will only be possible for a consumer company that has a lot of observations. Generally, business-to-business companies have a small data challenge. So there’s so many competing concerns with refitting your model.
The job doesn’t stop once you’ve deployed.
You should continuously monitor your model’s predictions for accuracy because that’ll actually give you the warning sign if it’s been too long since retraining.
3.1 How to make your model robust to drift
- Set up a Data Sharing Agreement with data source owners to receive advanced warnings of data drift
- Monitor the distribution of incoming data against original training data — you can do this using the Kolmogorov-Smirnov (K-S) test or simply comparing the z-score
- Monitor a time series dataset for drift from the previous time period — you may want to deploy the Population Stability Index (PSI) metric to do so
- Retrain your model on a scheduled basis — e.g every five months — or through online learning, where the model is constantly intaking new training data and new versions are released in a continuous integration / continuous deployment process.
3.2 Read more about model retraining
4.0 Take Advantage of Positive Feedback Loops
Algorithms are a powerful tool for empowering data-driven action. Through retraining on paired predicted and actual data, the results of the model become increasingly sophisticated over time.
The output of the data product provides high quality signals when integrated back into the data lifecycle. Andrew Ng referred to this concept as thevirtuous cycle of AI. Harvard Business Review called it the insights engine.

Robust capture of data-driven decisions and their outcomes could further enrich the data collection process. Hopefully soon, more feedback collection opportunities will be built into dashboards, web interfaces, and other data products. Feedback collection can empower the end user and improve the insight engine.
4.1 How to take advantage of positive cycles
- Communicate with stakeholders at the beginning of the planning process about the outsized benefits of effective machine learning models
- Create data collection pipelines from the deployed model
- Ensure accuracy of metadata
4.2 Read more about what makes for an effective data product
5.0 Prevent Negative Feedback Loops
A word of caution: far from being a self-sustaining system, a data product requires consistent monitoring. While the algorithmic feedback loop can create an insight-enriched dataset, it can also generate a bias-perpetuating cycle. There are many examples where the deployment of machine learning tools, particularly those with limited interpretability and explainability, accidentally deepened societal biases.

For example, a data science contracting firm created an algorithm to predict recidivism that was deployed in New York, Wisconsin, California, Florida, and other jurisdictions. ProPublica found that the algorithm perpetuated existing inequalities into a well-trodden feedback loop.
Although the defendant’s race was explicitly left out of the feature set, the algorithm used features highly correlated to race that informed inadvertently biased judgments. These features should also have been eliminated in order to reduce disparities in the judgment of the machine learning system. Read more about these risks in this article.
As a lighthearted solution to the stagnation of a negative feedback loop, a computer scientist invented a randomness generator to shake up his social life:Randomized LivingStarting in 2015, I let a computer decide where I lived and what I did for over two years. It sent me all over the world…maxhawkins.me
5.1 How to avoid a downward spiral
- Start with a checklist that helps you think through the ethical implications of your model
- Thoroughly investigate potential sources of bias in your pre-processing, processing, and post-processing phases of model training — and then remediate sources of bias
- Communicate model performance across protected classes in documentation
5.2 Read more about anti-bias tools
Summary
Failing to plan is planning to fail. So said Benjamin Franklin, immediately before getting struck by lightning while flying a kite out his bedroom window during a thunderstorm.
I like to think that if he were alive today, the Founding Father of the $100 bill would have been building a GPU-powered deep learning box, regularly PR’ing open source projects, and selecting and deploying models like a boss.
By starting off your next data science project with a robust planning process, you can ensure your model has better than 1:9 odds of making it into production. Use these tips for better model selection and deployment:
- Don’t Underestimate Interpretability
- Prune for Productionization
- Prevent Data and Model Drift
- Take Advantage of Positive Feedback Loops
- Prevent Negative Feedback Loops
Only fly a kite out your bedroom window during a thunderstorm if you want to get misquoted.



