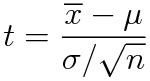t.test(holdout_res,mu=0)

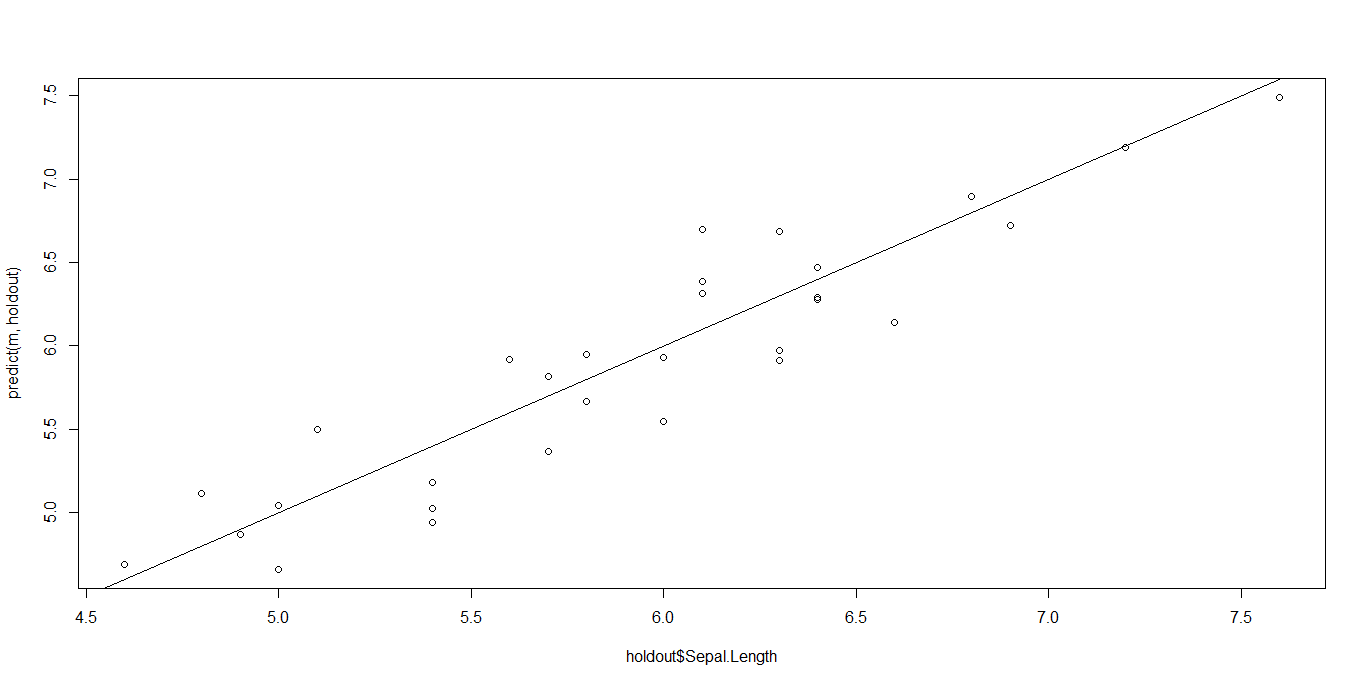
As we can see, the p-value is greater than 5%, so we cannot reject the null hypothesis and can say that the mean value of the holdout residuals is statistically similar to 0.
Then, we can test if the holdout residuals have the same average as the training ones. This is called Welch’s t-test.
t.test(training_res,holdout_res)

Again, a p-value higher than 5% can make us tell that there aren’t enough reasons to assume that the mean values are different.
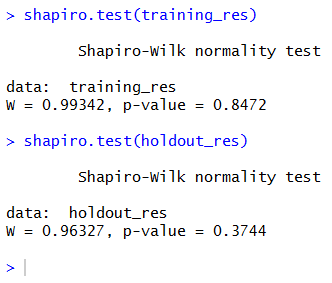
Both p-values are higher than 5%, so we can say that both sets show normally distributed residuals. We can safely go on performing the F-test.