Teaching yourself deep learning is a long and arduous process. You need a strong background in linear algebra and calculus, good Python programming skills, and a solid grasp of data science, machine learning, and data engineering. Even then, it can take more than a year of study and practice before you reach the point where you can start applying deep learning to real-world problems and possibly land a job as a deep learning engineer.
Knowing where to start, however, can help a lot in softening the learning curve. If I had to learn deep learning with Python all over again, I would start with Grokking Deep Learning, written by Andrew Trask. Most books on deep learning require a basic knowledge of machine learning concepts and algorithms. Trask’s book teaches you the fundamentals of deep learning without any prerequisites aside from basic math and programming skills.
The book won’t make you a deep learning wizard (and it doesn’t make such claims), but it will set you on a path that will make it much easier to learn from more advanced books and courses.
Building an artificial neuron in Python

Most deep learning books are based on one of several popular Python libraries such as TensorFlow, PyTorch, or Keras. In contrast, Grokking Deep Learning teaches you deep learning by building everything from scratch, line by line.
You start with developing a single artificial neuron, the most basic element of deep learning. Trask takes you through the basics of linear transformations, the main computation done by an artificial neuron.
You then implement the artificial neuron in plain Python code, without using any special libraries.
This is not the most efficient way to do deep learning, because Python has many libraries that take advantage of your computer’s graphics card and parallel processing power of your CPU to speed up computations. But writing everything in vanilla Python is excellent for learning the ins and outs of deep learning.
In Grokking Deep Learning, your first artificial neuron will take a single input, multiply it by a random weight, and make a prediction. You’ll then measure the prediction error and apply gradient descent to tune the neuron’s weight in the right direction. With a single neuron, single input, and single output, understanding and implementing the concept becomes very easy. You’ll gradually add more complexity to your models, using multiple input dimensions, predicting multiple outputs, applying batch learning, adjusting learning rates, and more.
And you’ll implement every new concept by gradually adding and changing bits of Python code you’ve written in previous chapters, gradually creating a roster of functions for making predictions, calculating errors, applying corrections, and more. As you move from scalar to vector computations, you’ll shift from vanilla Python operations to Numpy, a library that is especially good at parallel computing and is very popular among the machine learning and deep learning community.
Deep neural networks with Python
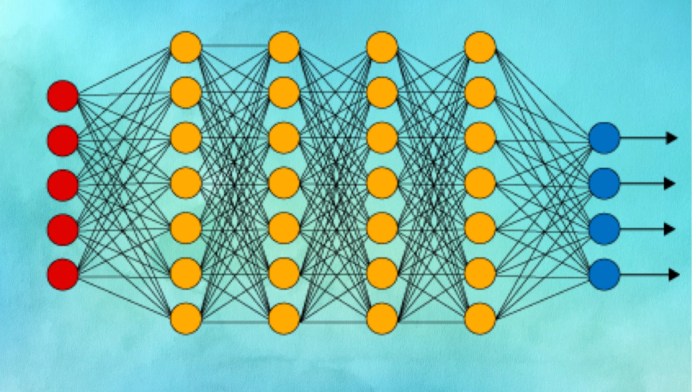
With the basic building blocks of artificial neurons under your belt, you’ll start creating deep neural networks, which is basically what you get when you stack several layers of artificial neurons on top of each other.
As you create deep neural networks, you’ll learn about activation functions and apply them to break the linearity of the stacked layers and create classification outputs. Again, you’ll implement everything yourself with the help of Numpy functions. You’ll also learn to compute gradients and propagate errors through layers to spread corrections across different neurons.
As you get more comfortable with the basics of deep learning, you’ll get to learn and implement more advanced concepts. The book features some popular regularization techniques such as early stopping and dropout. You’ll also get to craft your own version of convolutional neural networks (CNN) and recurrent neural networks (RNN).
By the end of the book, you’ll pack everything into a complete Python deep learning library, creating your own class hierarchy of layers, activation functions, and neural network architectures (you’ll need object-oriented programming skills for this part). If you’ve already worked with other Python libraries such as Keras and PyTorch, you’ll find the final architecture to be quite familiar. If you haven’t, you’ll have a much easier time getting comfortable with those libraries in the future.
And throughout the book, Trask reminds you that practice makes perfect; he encourages you to code your own neural networks by heart without copy-pasting anything.
Code library is a bit cumbersome
Not everything about Grokking Deep Learning is perfect. In a previous post, I said that one of the main things that define a good book is the code repository. And in this area, Trask could have done a much better job.
The GitHub repository of Grokking Deep Learning is rich with Jupyter Notebook files for every chapter. Jupyter Notebook is an excellent tool for learning Python machine learning and deep learning. However, the strength of Jupyter is in breaking down code into several small cells that you can execute and test independently. Some of Grokking Deep Learning’s notebooks are composed of very large cells with big chunks of uncommented code.
This becomes especially problematic in the later chapters, where the code becomes longer and more complex, and finding your way in the notebooks becomes very tedious. As a matter of principle, the code for educational material should be broken down into small cells and contain comments in key areas.
Also, Trask has written the code in Python 2.7. While he has made sure that the code also works smoothly in Python 3, it contains old coding techniques that have become deprecated among Python developers (such as using the “for i in range(len(array))” paradigm to iterate over an array).
The broader picture of artificial intelligence

Trask has done a great job of putting together a book that can serve both newbies and experienced Python deep learning developers who want to fill the gaps in their knowledge.
But as Tywin Lannister says (and every engineer will agree), “There’s a tool for every task, and a task for every tool.” Deep learning isn’t a magic wand that can solve every AI problem. In fact, for many problems, simpler machine learning algorithms such as linear regression and decision trees will perform as well as deep learning, while for others, rule-based techniques such as regular expressions and a couple of if-else clauses will outperform both.
The point is, you’ll need a full arsenal of tools and techniques to solve AI problems. Hopefully, Grokking Deep Learning will help get you started on the path to acquiring those tools.
You can also pick up a lot of knowledge browsing machine learning and deep learning forums such as the r/MachineLearning and r/deeplearning subreddits, the AI and deep learning Facebook group, or by following AI researchers on Twitter.
The AI universe is vast and quickly expanding, and there is a lot to learn. If this is your first book on deep learning, then this is the beginning of an amazing journey.



